
Ataccama 16.3.0 Release Notes
This release brings data quality closer to your data infrastructure, with new integrations for Snowflake, Databricks, and Atlan. MDM introduces a new streaming event handler and Admin Center improvements.
Release date |
October 20, 2025 |
Support |
Long-Term Support (LTS) |
Upgrade notes |
DQ&C, MDM, RDM, ONE Desktop |
Latest patch |
Patch 27 (April 14, 2026) |
Products |
ONE Data Quality & Catalog, ONE MDM, ONE RDM, ONE Runtime Server, ONE Desktop |
Downloads |
|
Security updates |
Release Highlights
Data Quality Gates for Snowflake ONE DQ&C
Define data quality rules once in Ataccama ONE, then deploy them as native Snowflake UDFs callable directly in SQL.
Read more ↓
Databricks Pushdown Processing ONE DQ&C
Run profiling and data quality evaluation as a pushdown workload directly in Databricks.
Read more ↓
View ONE DQ Results in Atlan ONE DQ&C Atlan
Browse data quality results from Ataccama ONE directly in the Atlan catalog without switching platforms.
Read more ↓
Automated Lineage Harvesting ONE DQ&C
Schedule lineage scan plans with cron expressions and manage edge processing directly from the web application.
Read more ↓
ONE Data in Hybrid Environments ONE Data
Use ONE Data across hybrid deployments where Ataccama ONE runs in the cloud and Data Processing Engines run on-premise.
Read more ↓
Streaming Event Handler ONE MDM
Publish events with batching, scope filtering, and simplified configuration via the new Streaming Event Handler.
Read more ↓
ONE
Introducing Ataccama Data Quality Gates
Ataccama Data Quality Gates enables you to deploy and execute data quality rules directly within your data processing environments, validating data in motion as it flows through pipelines.
Define rules once in Ataccama ONE, then deploy them as native platform functions that execute locally within your data infrastructure.
This initial release supports Snowflake, deploying the DQ rules as User-Defined Functions (UDFs) callable directly in SQL, and local execution in Python.
For full release notes, see Ataccama Data Quality Gates Release Notes.
Databricks Pushdown Processing
Pushdown profiling is available on Databricks sources. Run profiling and data quality evaluation as an SQL pushdown workload directly in Databricks and benefit from enhanced security and performance.
For more details about how pushdown processing works and how to set it up for your connection, see Databricks SQL Pushdown Processing.
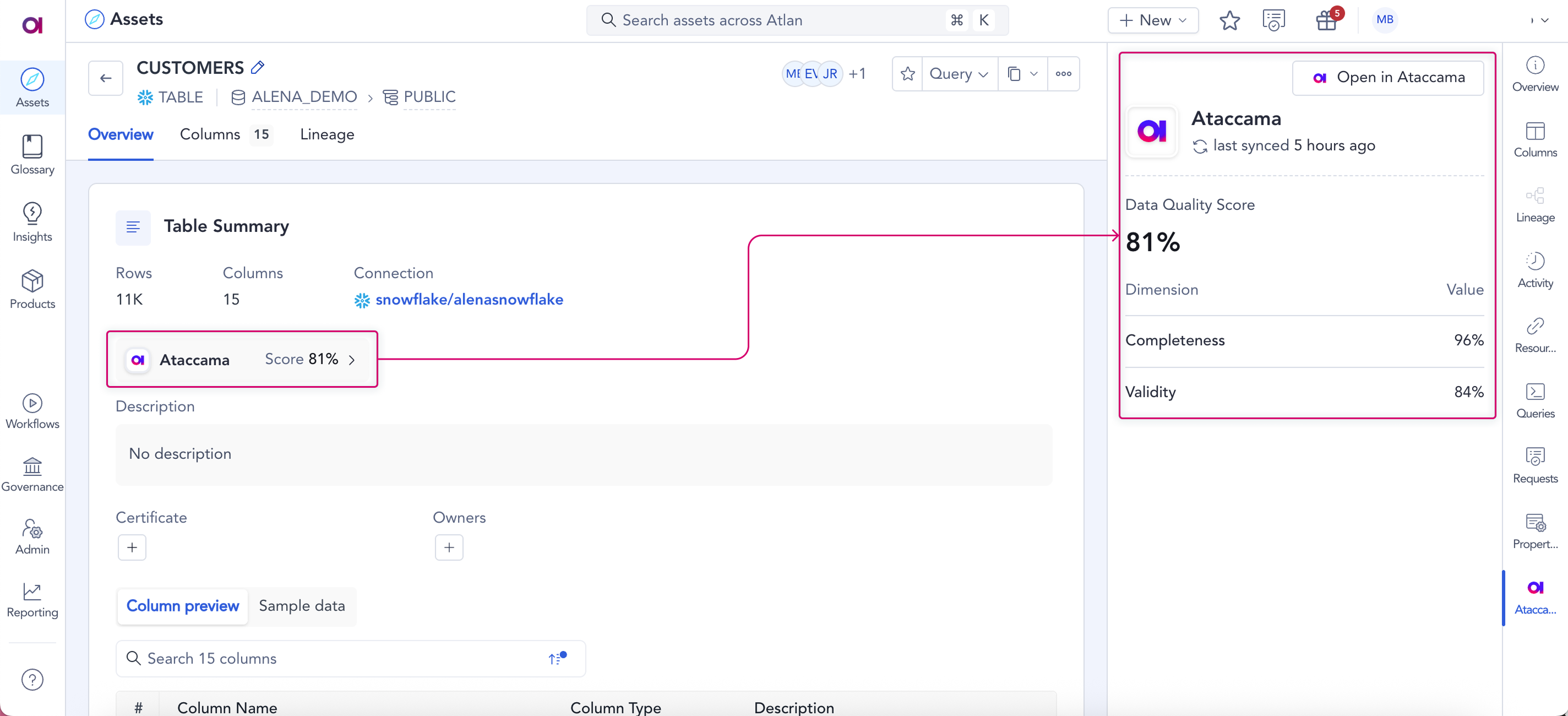
View ONE DQ Results in Atlan
Atlan can now retrieve data quality results directly from Ataccama ONE and display them in its catalog. This lets you perform quality-aware data discovery without switching between platforms.
Atlan displays overall data quality results at both the table (catalog item) and attribute levels, including their dimensional breakdowns. Additionally, you can click through from Atlan assets to corresponding catalog items in ONE for detailed context and analysis.
The integration provides full control over which ONE data sources are included in the integration.
For more information and setup instructions, see Atlan Integration and Configure Atlan Integration.
ONE Data Available in Hybrid Environments
ONE Data is now fully supported in hybrid environments, where all of Ataccama ONE runs in the cloud except Data Processing Engines (DPEs).
This update allows you to take full advantage of ONE Data capabilities across both on-premise and cloud deployments.
For details about how to make ONE Data available in a hybrid setup, see ONE Data Setup for Hybrid Deployments.
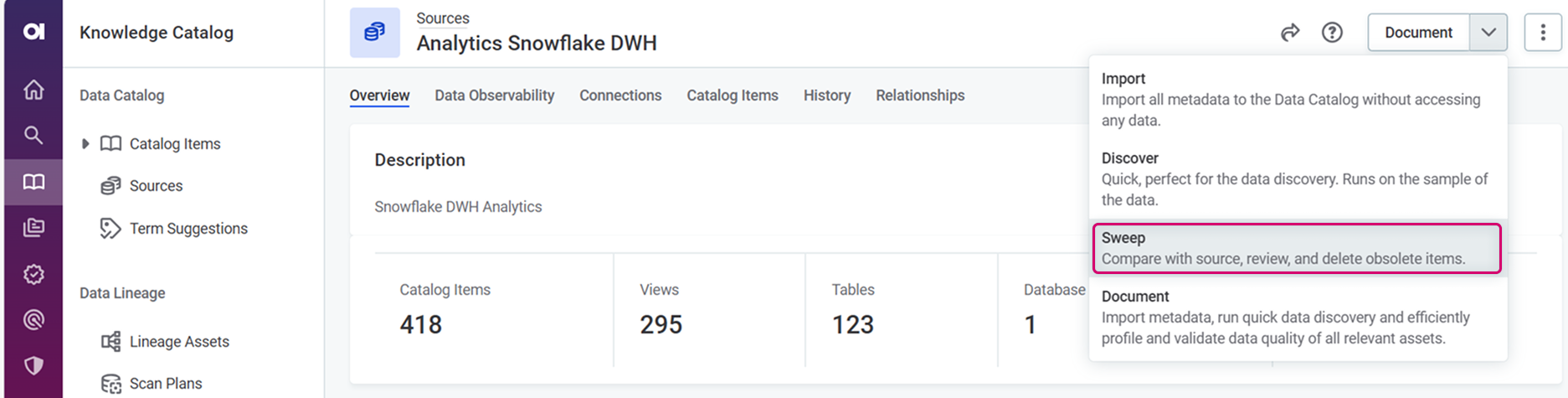
Remove Obsolete Catalog Items in Bulk
Keep your Data Catalog up to date with the new Sweep documentation flow.
Start by running the Sweep documentation flow to identify catalog items that no longer exist in the data source, either because they’ve been deleted or renamed. Then review and delete identified catalog items in bulk from the Notification Center.
Catalog Item Page Performance
The catalog item screen has been optimized to improve loading performance by reducing the amount of data fetched by default.
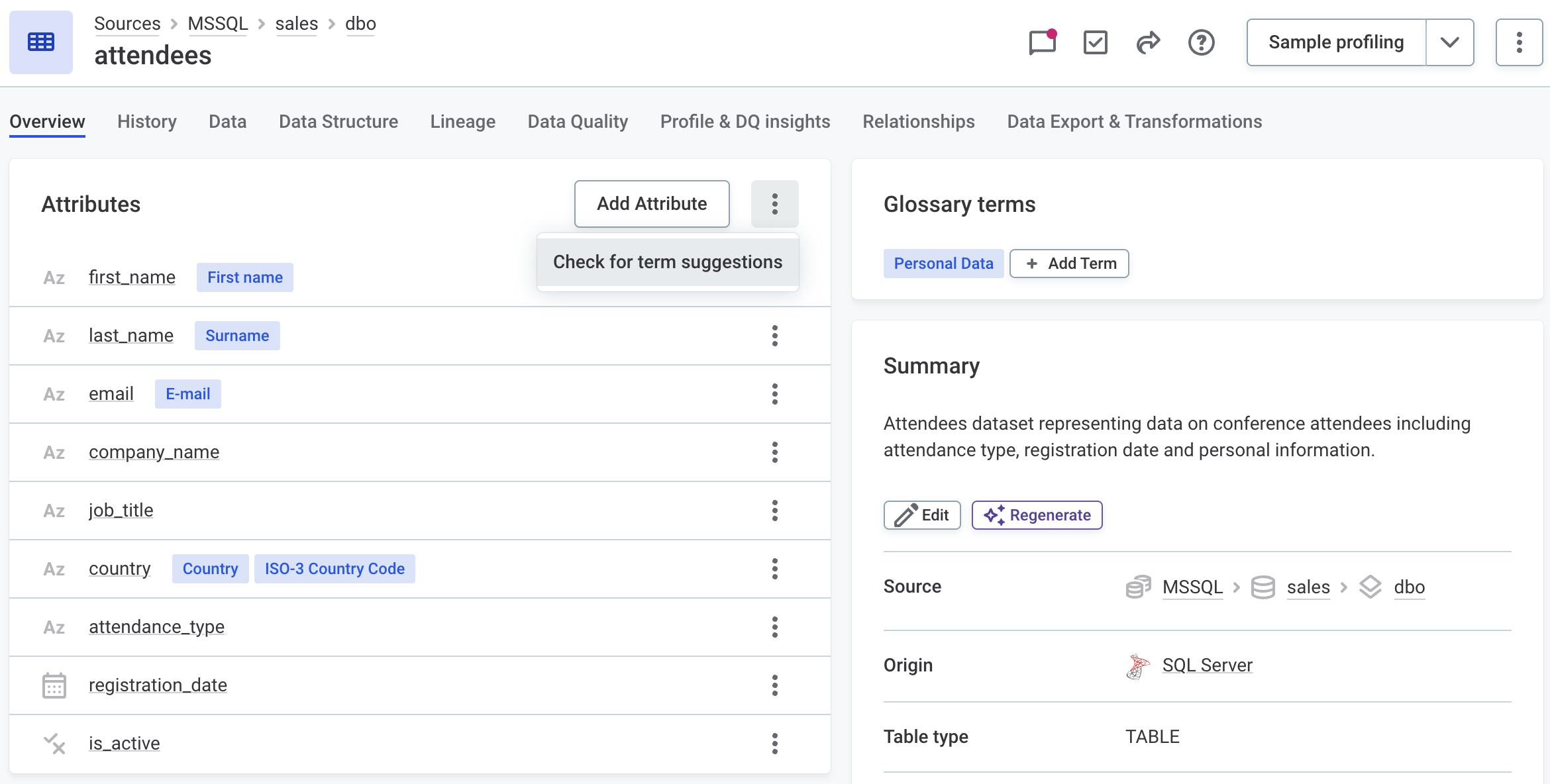
Attribute-Level Information Display
Term suggestions and anomaly icons are no longer displayed on the attribute listing on the catalog item Overview tab.
-
Term suggestions can be managed from Knowledge Catalog > Term Suggestions, or accessed for a specific catalog item via the three dots menu in the Attributes section (Check for term suggestions).
Individual attribute term suggestions remain visible in the attribute details sidebar.
-
Anomalies are indicated by a banner at the catalog item level, where users can view details.
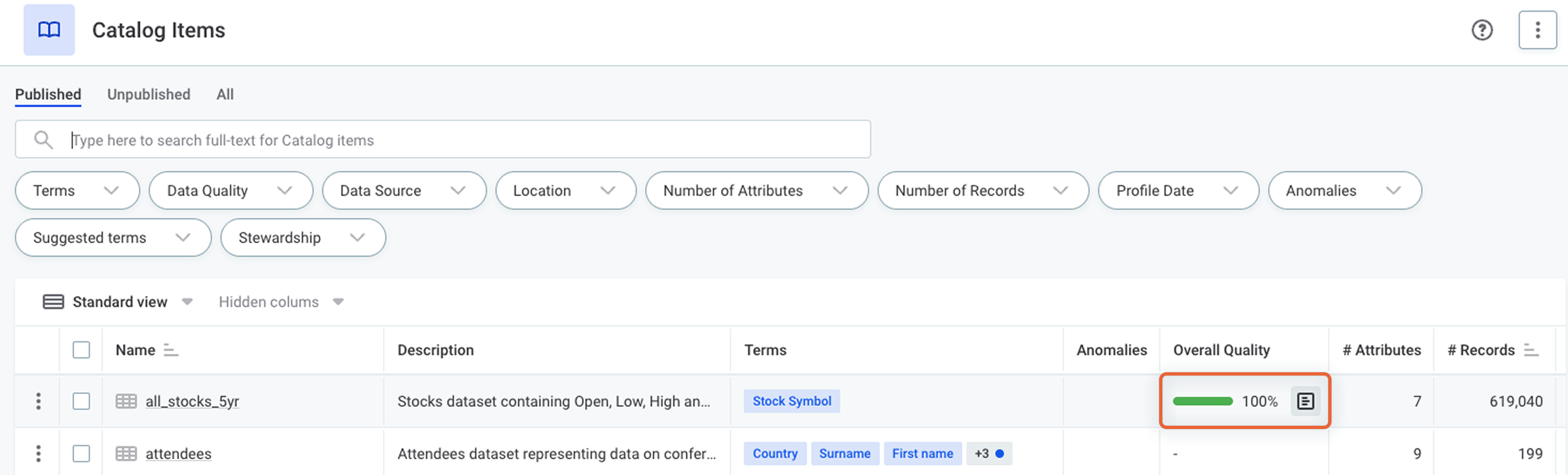
Overview Tab and Navigation
The following widgets have been removed from the Overview tab default layout:
-
Data Quality widget
-
Number of records widget
To maintain quick access to this information:
-
Navigating to a catalog item from monitoring projects now opens the Profile & DQ Insights tab directly.
-
A new shortcut from the quality column in the catalog item listing links to the Data Quality tab.
|
Re-enabling hidden features
Removed widgets and attribute-level information can be re-added if needed, though this can impact performance. See Entity Screen Customization. |
New Authentication Options for Snowflake in Data Stories
Snowflake sources in Data Stories now support key-pair authentication and OAuth 2.0. For configuration details, see Data Stories Connection.
Support for S3-Compatible Data Sources
Connect to S3-compatible storage solutions like MinIO, expanding your object storage options beyond AWS S3.
For configuration details, see Amazon S3 Connection and follow the instructions for S3 compatible connectors.
New MS Teams Notifications Integration
MS Teams notifications for monitoring projects are now available again through a new integration method.
If you previously used MS Teams notifications in Ataccama ONE, generate a new incoming webhook in MS Teams using the Workflows app and update your notifications configuration in ONE accordingly. See MS Teams Integration.
Enhancements to Lineage Edge Processing
Edge processing for lineage scanners can now be managed directly in the web application:
-
Turn on edge processing from your scan plan - Turn on edge processing when creating or editing a scan plan and select from connected edge instances via dropdown. Previously, edge processing had to be configured within the scan plan.
-
Lineage Configuration screen - View and manage all connected and deactivated edge instances. You can refresh the list to see the latest status and deactivate instances as needed.
For details, see Lineage Edge Processing.

Schedule Lineage Scan Plans
Lineage scan plans can now run automatically at defined intervals using cron expressions. This keeps your lineage metadata current with minimal manual effort.
-
Automatic import - Import scan results automatically after successful scans. Review and publishing remain under your control.
-
Automatic publishing - Fully automate lineage updates using automatic publishing (applies the Expand write strategy).
-
Progressive approach - Start with manual imports, enable automatic import for semi-automation, then add automatic publishing for full automation as you build trust in your data.
For more details, see Schedule scan plan.
MDM
New Event Handler and Publisher
A new Event Handler and Publisher implementation brings improved stability and performance across event storing, filtering, processing, and traversing operations.
With the new event scope filter, you can target events more efficiently. Event batching and streaming offer flexible publishing options: large transactions can be broken into smaller chunks for publishing (batching), while small transactions can be collected and published as one chunk (planned).
The new implementation is streamlined to plan publisher only with simplified configuration for easier setup and maintenance. For more details, see Streaming Event Handler.

Improvements to Admin Center
The MDM Web App Admin Center now features enhanced task execution monitoring, new navigation and usability improvements, and the ability to monitor the Orchestration server status all in one spot.
Enhanced Task Execution Monitoring
Key improvements include:
-
Millisecond-precision tracking - All job timestamps include milliseconds, making it easier to monitor and troubleshoot operations in high-workload environments where multiple transactions complete in parallel, sometimes within sub-second timeframes.
-
Timezone listed in execution reports - Execution reports indicate the server timezone for consistency across environments.
-
Better visibility of tasks in progress - Details and duration of currently running subtasks are expanded by default, including nested subtasks.
For quick status assessment, the task listing also shows one key metric per row—either Started at (if not started) or Finished at (if running). In addition, the Tasks API now provides duration information even for unfinished subtasks, enabling better programmatic monitoring.
-
Running operations count on server stop - The Stop server action displays the count of currently running operations, helping you avoid interrupting critical processes. If not relevant, such tasks can now be force stopped.
-
Persistence status monitoring - If defined, the VLDB persistence type can be monitored from the Persistence Status tab in the Admin Center.
To learn more, see Monitoring.
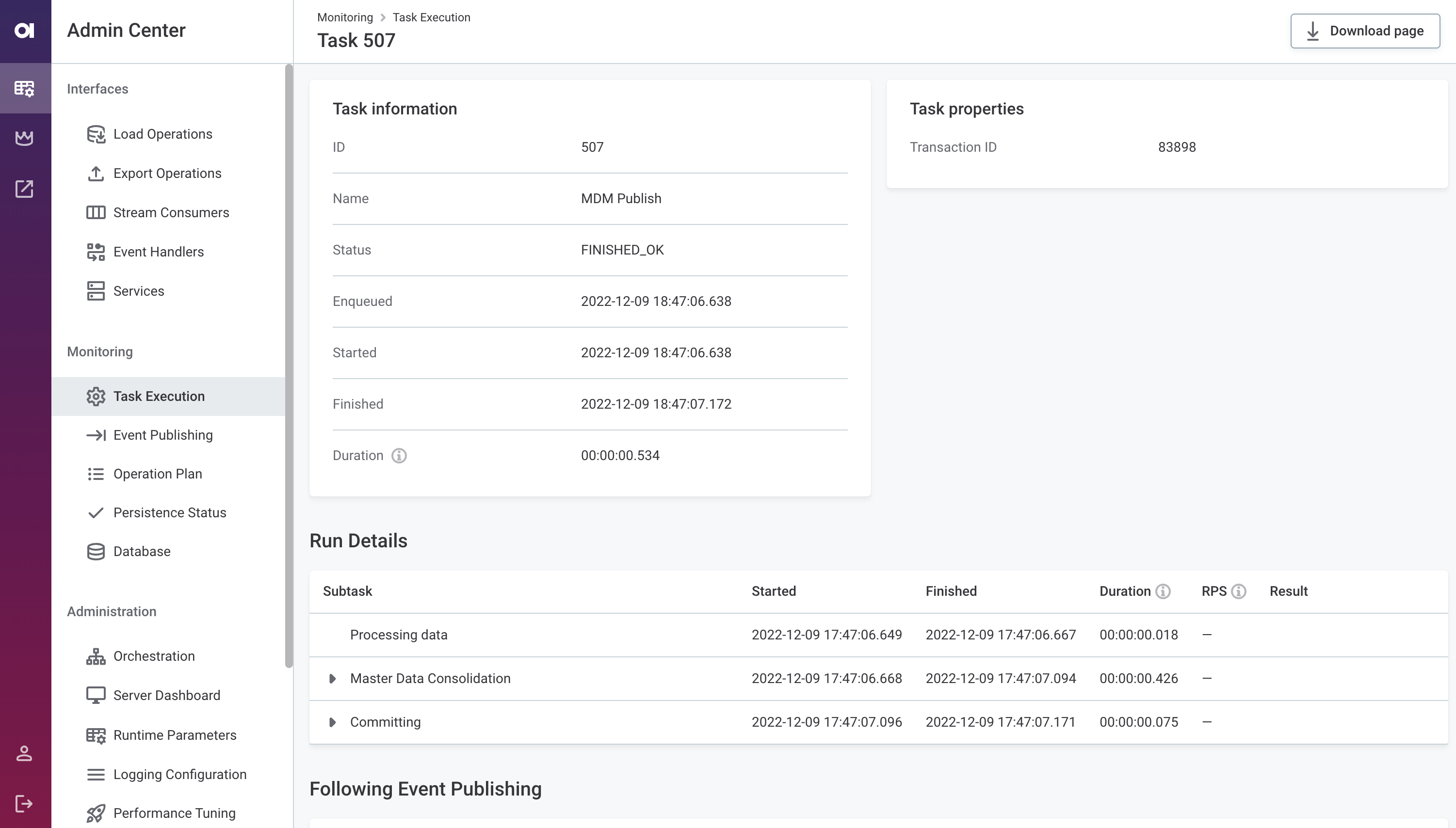
Orchestration Screen Available in Admin Center
Track the health status, resources, services, and various statistics of the Orchestration Server directly from the MDM Web App Admin Center. The new Orchestration screen also allows monitoring and running workflows and schedulers.
To learn more, see Administration.
Changes to Navigation
The navigation menu in MDM Web App Admin Center has been reordered for easier access to key functions.
For a full overview of changes, see MDM Web App Admin Center.
Store Lookup Files in MinIO
MDM now supports storing lookup files in MinIO for improved performance with large files and updates without server restarts.
Choose the right approach for your needs:
-
Static approach - Uses Git storage with server restarts for updates. Best for small files (under 5 MB) and infrequent changes.
-
Dynamic approach - Leverages MinIO and the Versioned File System (VFS) component for no-downtime updates. Best for large files or production environments requiring high availability.
Additionally, MinIO provides built-in backup and recovery capabilities, enhancing data integrity and resilience.
Both approaches work in cloud and self-managed deployments. You can combine both within the same environment or use the dynamic approach for all lookup files regardless of size.
For configuration details and migration steps from the static to the dynamic approach, see Lookups Management in MDM.
Enhanced Matching Proposal Management
Benefit from better visibility and control when working with matching proposals and manual match.
Review and modify merge operations before applying them, track who created or last edited each draft operation, and identify operation types at a glance with color-coded previews. To prevent accidental cross-task actions, task context warnings are now available.
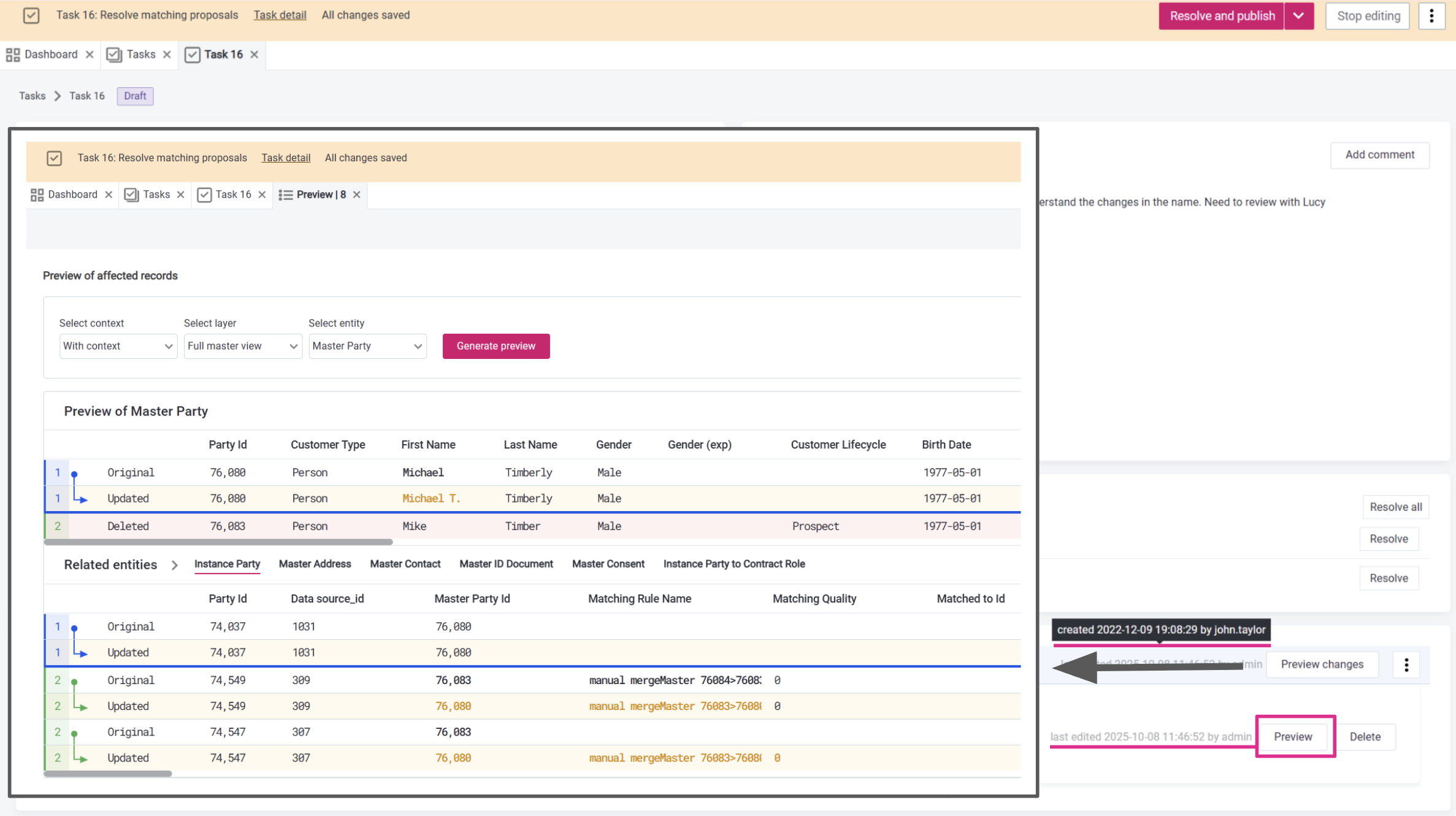
Deprecation Notice
The following features will be deprecated starting from version 17. In case of any questions, contact Ataccama Support.
MS SQL and Oracle RDBMS
As a follow up to version 15.4.0 announcement, MS SQL and Oracle RDBMS will no longer be supported for MDM Storage starting in version 17. While these databases will continue to function during the 16.3.0 LTS support period (two years), we recommend migrating to PostgreSQL at your earliest convenience.
Alternatively, you can switch to Custom Ataccama Cloud, where we manage PostgreSQL on your behalf.
Async Event Handler
The Async Event Handler is obsolete from version 17 and will be removed in version 18.
If you are using the event handler traversing functionality, we recommend migrating to the new Streaming Event Handler. If migration is not immediately possible, the Async Event Handler can continue to be used for small data volumes until version 18.
Old Admin Center
The old Admin Center has been fully replaced with the new implementation, available since 13.8.0.
In 16.3.0 LTS, the old Admin Center is turned off by default. It is deprecated in version 17 and will be removed in version 18.
No user action is needed to migrate: you can start using the new Admin Center immediately. For details, see MDM 16.3.0 Upgrade Notes.
RDM
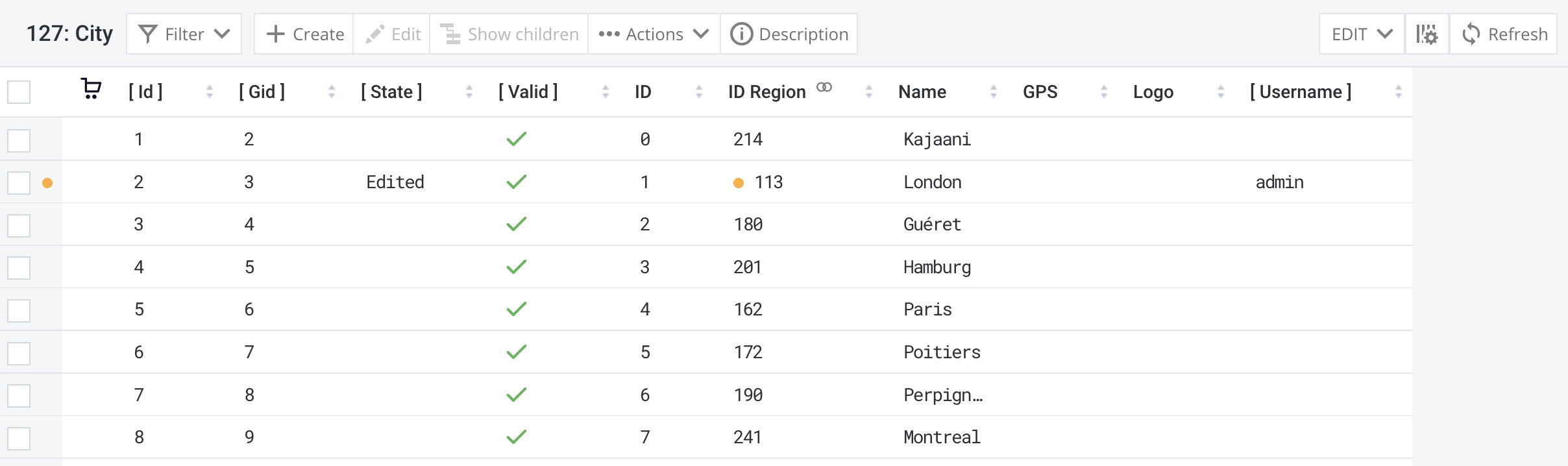
Edited Values Display in RDM Views
RDM Views now display edited values in create and edit dialogs and record detail views more clearly, allowing you to see at a glance which specific attributes were modified.
An orange dot marks updated attributes when the attribute value or a reference to a parent record changes. If the parent record’s values change instead, no indicator is displayed.
Value hovers in grid listings are no longer displayed, as published values cannot be loaded for multiple rows.
Customize Logo and Environment Name
Brand your RDM environment with custom logos and labels. Upload your organization’s logo, set environment-specific text (such as "Production" or "Development"), and apply styling to adjust the logo’s appearance.
For details, see RDM Server Application Properties > Static configuration.
Platform Changes
PostgreSQL 17 Support
ONE components now support PostgreSQL 17 as the recommended database version across the platform (DQ&C, MDM, RDM). When upgrading self-managed, on-premise deployments to version 16.3.0, upgrade to PostgreSQL 17 for optimal performance and support.
PostgreSQL 15 remains available under limited support. This means the application should run on this platform but compatibility is not tested with each version.
For details, refer to Supported Third-Party Components.
Fixes
For fixes delivered in patch releases, see 16.3.0 Patch Releases.
ONE
- Monitoring projects
-
-
Fixed a performance issue in the filter validator that determines suitable attributes for filters.
-
Failed projects no longer leave behind temporary files that take up extra storage space.
-
When running on BigQuery using pushdown processing, column names in generated SQL are no longer duplicated.
-
Fixed inconsistent results in monitoring projects that reference multiple aggregation rules with variables on Databricks.
-
When applying rules to Snowflake catalog items, only published rules are available for selection.
-
The Report tab displays correctly after adding a notification.
-
Notifications are now sent correctly when overall data quality is not available for some catalog items but others meet the notification threshold.
-
Anomaly checks applied on a data slice no longer process the entire catalog item.
-
The Catalog Items screen and catalog items load significantly faster.
-
Fixed the issue with anomaly detection jobs repeatedly failing.
-
Email notifications display values of data quality filters.
-
Extensive filtering operations are handled reliably without crashing, using improved file size and threshold management.
-
When importing configuration from one project to another, all rules from the source project are correctly imported and mapped.
-
When editing anomaly configuration, the value of Sensitivity of anomaly detection is displayed.
-
It is possible to add events and channels to notifications.
-
Publishing works as expected.
-
A warning about number of possible value combinations no longer appears when unselecting attributes to be used as filters.
-
The Invalid Samples screen shows the correct overall quality value when accessed from a historical run.
-
The profile inspector only shows anomalies for attributes with anomaly detection enabled, preventing confusion caused by unrelated anomalies.
-
Email notifications no longer show some data quality results as negative if DQ results are missing.
-
Submission no longer fails when a relevant Data Processing Engine is temporarily disconnected.
-
Monitoring project configuration UI indicates if referenced catalog items have been deleted from Data Catalog.
-
- Rules
-
-
Detection rule inputs are validated, no longer causing job failure because of invalid input names.
-
When assigning a term to an attribute, the rules applied to that term are now displayed in the Applied rules column.
-
In DQ rule creation, the AI prompt used to generate logic and inputs now persists after testing.
-
Sidebar with details of ONE Data table attribute displays the correct number of applied rules.
-
A correct dialog is displayed when changing dimension in the quick creation workflow.
-
Duplicate names are no longer allowed when creating inputs.
-
The Add rule option on the attribute Overview tab is no longer deactivated.
-
When viewing rule occurrences, the Attributes tab also displays rules applied to ONE Data attributes.
-
Rule debug improvements:
-
Deleting conditions is correctly reflected in the debug results.
-
Testing individual conditions shows correct results.
-
Debug shows consistent results for friendly and advanced expressions.
-
-
- Transformation plans
-
-
Sharing plans is now possible.
-
When creating plans, ONE Operator, Data Owner and Data Steward have
Full accessby default. -
DB writer step now defaults to the Append data write strategy, instead of Replace.
-
Only users with corresponding permissions for a catalog item can select Create new catalog item in the Database Output step.
-
A warning is displayed after selecting Validate plan if incompatible data types are detected.
-
Fixed data preview for valid steps preceding the step with validation issue.
-
Data preview jobs are correctly routed to the proper DPE.
-
Transformation plans now gracefully handle attributes with unsupported binary data types by skipping them during execution and displaying a warning in the UI.
-
- Catalog & data processing
-
-
BigQuery, Synapse, and Databricks pushdown processing support additional SQL functions including aggregate, conditional, and mathematical operations:
countDistinct,iif,math.abs,math.acos,math.asin,math.atan,math.e,math.exp,math.log10,math.log,math.pi,math.pow,math.sin,math.sqrt,math.tan. -
Snowflake pushdown processing supports VARIANT, VECTOR, and GEOMETRY column types by converting them to strings.
-
Okta Single Sign-On (SSO) can now be used with Spark processing. Previously, impersonation could be used only for interactive actions and local Data Processing Engine (DPE) jobs.
-
In Microsoft Excel files, empty columns are correctly resolved as String instead of Date and Integer columns are no longer treated as Boolean.
-
Data slices created from a BigQuery source use the correct data type when comparing data in a Timestamp column.
-
When sorting catalog items by # Records, unprofiled items are treated as having
0records and appear at the bottom when sorting by most records first. -
Documentation flow is no longer shown as running if all related jobs are finished (completed or canceled).
-
Databricks job clusters are correctly located during job execution.
-
- Data source connections
-
-
OneLake connections now support folder and file names containing spaces. Using spaces in workspace names is still not supported.
-
Power BI Report Server connector now supports paginated reports.
-
S3 connection configuration screen displays Endpoint and Region fields based on provider type, and the MINIO provider is now labeled as S3 Compatible.
-
The Spark enabled option has been removed from JDBC connections.
-
Databricks connections now support
checkMountPointparameter to verify mount point accessibility before job execution. -
Snowflake JDBC connections no longer time out during network or SSL handshake failures.
-
Database export operations work correctly when using write credentials only, without requiring default credentials for listing schemas and tables.
-
Test Connection feature works correctly for ONE Data connections.
-
Client ID field is now available in the SAP RFC connection creation form.
-
Secret Management Service requests are correctly routed to the appropriate DPE in hybrid cloud environments.
-
In Ataccama Cloud, Keycloak monitoring endpoints are no longer accessible from public domains. When upgrading, adjust your hybrid DPE configuration accordingly. See DQ&C 16.3.0 Upgrade Notes.
-
Invalid JDBC connections no longer block gRPC executor threads for other connections.
-
- ONE Data
-
-
Adding rules or terms to the technical attribute
dmm_record_idis no longer possible. -
It is possible to manually edit values in
DateTimecolumns. -
Added new date-time formats to import wizard.
-
Tables can no longer appear deleted while still being referenced by a transformation plan.
-
When you export a table with an edited name, it is correctly exported using the updated name.
-
- Data Admin Console
-
-
Create Thread Dump and Kill Job actions are available on the DPM job detail page in DPM Admin Console. Previously, they were available only from the job listing menu.
-
Job logs and related files can be downloaded as a ZIP file directly from the console.
-
You can open jobs in a new tab, and the console remembers the previous page position when navigating back.
-
Strict version compatibility rules prevent connections with unsupported DPE versions.
-
- Performance & stability
-
-
Addressed high CPU usage on environments using AWS RDS/Amazon Aurora database.
-
DQ jobs now run more efficiently with optimized memory usage, addressing previous
OutOfMemoryfailures. This improvement includes moving resource-intensive result processing from DPM to DPE and fixing a faulty filter combination limit check. -
Improvements to Anomaly Detector monitoring.
-
- Usability & display
-
-
Text in Custom Term Property doesn’t overflow adjacent elements.
-
Filters in pages with custom layout work as expected.
-
Long explanation texts in monitoring project detailed results do not overlap other fields.
-
Selecting sources in Create SQL Catalog Item dialog works as expected.
-
Selecting a graph with data quality results displays a detailed graph.
-
Icons in email notifications display correctly.
-
Adding terms to comments works as expected.
-
All localization files are correctly applied in self-managed deployments.
-
- Upgradability
-
-
The Task service can be upgraded from 15.4.1 to 16.2.0 without issues.
-
Fixed the issue where ONE sometimes remained in Maintenance mode after upgrading to or deploying version 16.2.0.
-
Fixed the issue where tasks could not be successfully approved or canceled after upgrading to 15.4.0.
-
MDM
-
Record activity status can now be updated programmatically, via REST API. You can change the activity on both master and instance entities. See Activate and deactivate records.
-
When inserting and updating records through REST API, the
source_timestampparameter supports milliseconds according to the ISO 8601 standard for date and time format. See Source timestamp formatting. -
In MDM REST API, using multiple values in preload filters works as expected.
-
MDM Swagger UI now uses OAuth 2.0 authentication.
-
Reading related records via REST API is correctly audited. Previously, only one read request was logged.
-
You can now audit custom actions. See Configuring Audit Log > Other actions.
-
Filtering by date in the MDM Web Application now works as expected.
-
MDM Server can access S3 buckets using
AWS_POD_IDENTITY_TOKENauthentication. -
History Plugin now tracks who last modified each record, the most recent transaction, and whether master records were authored or consolidated.
-
Improved error messaging for relationship misconfigurations.
-
Record details can be accessed by users without edit permissions.
-
Editing a task pending approval no longer creates a new task.
-
Tasks cannot be created without a draft if earlier tasks are closed in a failed state.
-
Filtering tasks by ID behaves consistently regardless of whether the filter was added manually or using the Add value to filter option.
-
Load and export operations in MDM Web App Admin Center display correctly even with large numbers of tasks (over 1M).
-
When using the COMBO lookup type, active and inactive lookup values are easier to distinguish in the MDM Web Application.
-
Lookup type WINDOW no longer allows custom values.
-
Restarting the server through MDM Web App Admin Center is more robust. Previously, it would occasionally interfere with the metrics collector, cause connection leaks, or break batch loads.
-
Improved performance when resolving record conflicts in Kafka streaming setups.
-
Connecting to Kafka works as expected.
-
MDM REST API no longer returns a server error when attempting to start an already active Kafka consumer.
-
The history plugin generates the
nme-history.gen.xmlfile without syntax errors. -
Initial MDM data load jobs no longer get stuck during the final commit phase.
-
Improved performance when running the
processPurgenative service. -
Setting filters in MDM Web App no longer throws errors due to duplicate entries in the user settings database.
-
In MDM Matching,
match_related_idremains consistently linked with the given record ID after rematching, even if the order of input records changes. -
Fixed random failures when using parallelism in matching with statistics tracking enabled.
-
Improved connection pooling in MDM, preventing the application from getting stuck due to
idle-in-transactiontimeout. -
Improved the observability of long-running matching jobs.
-
MasterDataConsolidationprocess gracefully shuts down when encountering anOutOfMemoryexception. -
Read misconfiguration in MDM Server no longer results in broken initialization order, preventing the server from starting.
RDM
-
Edit and Publish actions in the web app are available only after editing a record.
-
Enrich operation now works on entities of VIEW type.
-
In RDM Views, publishing a record correctly updates the record status instead of moving it to Waiting for publishing.
-
Improved stacktrace messaging when an invalid JSON payload is submitted.
-
Optimized comparison queries to prevent MS SQL databases from getting stuck.
-
In RDM web app, tables load within seconds regardless of table count and permissions setup.
-
Added an app variable to the RDM Model Explorer to control whether documentation is generated.
-
RDM Server now consistently establishes connections to the RDM Web Application without Connection refused errors.
ONE Desktop
-
ONE Desktop job results are no longer retained in the Executor Bucket (MinIO). The Delete MinIO Job result cleanup option is applied by default.
-
Unity Catalog column and data type mapping works correctly with Map to Query functionality in Databricks.
-
ONE Desktop successfully connects to MinIO instances behind a proxy.
-
SQL Commands are available in the table context menu.
-
Metadata Reader step correctly filters embedded object array data by specific properties instead of returning all values.
-
Metadata Reader step correctly retrieves
projectStatsdata for monitoring projects. -
CSV viewer displays a message when encountering lines exceeding the maximum record length (65,536 characters) instead of silently skipping or truncating them.
Was this page useful?