
Databricks Lineage Scanner
The Databricks scanner uses lineage information available in the Databricks Unity Catalog.
Scanned and supported objects
|
While we strive for comprehensive lineage capture, certain dataflows and transformations might be incomplete or unavailable due to technical constraints. We continuously work to expand coverage and accuracy. |
-
Column lineage (
system.access.column_lineage)-
Schema: lineage system table schema
-
-
Workspaces, directories, and notebooks (using Unity Catalog REST API), namely the following fields:
-
Path
-
Language
-
Creation and modification timestamps
-
Object ID
-
Resource ID
-
-
Additional data dictionary metadata (using Unity Catalog REST API):
-
Catalogs
-
Schemas
-
Tables
-
Limitations
Databricks Unity Catalog limitations
See the article Lineage limitations in the official Databricks Unity Catalog documentation.
Currently in Public Preview.
Scanner limitations
The following applies to both the online and file-based scanners.
-
Cross lineage to and from a cloud storage path (such as S3, Azure Data Lake storage) is currently not supported, including scenarios such as:
-
Loading data from cloud storage files.
-
Unloading data from Databricks to cloud storage files.
The following is an example of a non-supported statement:
Reading a CSV file on S3 into a Databricks table:create table test_table as SELECT * FROM read_files( 's3://<bucket>/<path>/<file>.csv', format => 'csv', header => true);
-
-
Job information is missing for notebooks executed from jobs. When lineage originated from a notebook that has been executed from a job task, the Unity Catalog lineage table contains only the ID of the notebook entity.
This is a limitation of Unity Catalog system tables that contain only the Databricks entity that is the direct source of the lineage event (the notebook).
Supported connectivity
The scanner connects to the Databricks workspace using the following connection methods:
-
Online scanner: See Online Databricks scanner.
-
Connector type: JDBC and Unity Catalog REST API.
-
Authentication methods:
-
Personal Access Token (PAT).
-
Microsoft Entra ID (formerly Azure Active Directory) using a service principal with client credentials.
-
-
-
File-based scanner: File-based Databricks scanner.
-
Local folder with extracted metadata.
-
Online Databricks scanner
The online scanner uses the Unity Catalog system tables.
A JDBC connection is established to query the lineage from the system table system.access.column_lineage.
Lineage metadata enrichment
To enrich the lineage data with transformation information from the Databricks notebook, the respective API is called. For details, see List contents.
Lineage post-processing
The lineage information from Unity Catalog system tables has several shortcomings that the scanner handles by post-processing it.
Non-existing database objects detection
The following Data Dictionary tables are accessed to determine whether the lineage database objects (tables, views, columns) existed at the time of lineage extraction:
-
system.information_schema.tables -
system.information_schema.columns
Lineage for external tables referenced via cloud storage path
External tables referenced using their cloud storage path are not resolved. See Troubleshooting external table queries.
To support this use case, the scanner uses the Unity Catalog REST API.
Both statements insert data into the same external table. For the first one, the scanner invokes the Unity Catalog REST API to look up the external table (by its cloud storage path).
INSERT INTO delta.`abfss://ataccama-testing@ataccamadatalakegen2.dfs.core.windows.net/customer`
SELECT c.* FROM stage_customer c;
INSERT INTO my_catalog.my_schema.customer
SELECT c.* FROM stage_customer c;Online scanner prerequisites
The following prerequisites must be in place before you run the Databricks online lineage scanner:
-
Authentication credentials:
-
For PAT authentication: A Databricks Personal Access Token with access to system tables and the Unity Catalog REST API.
-
For Microsoft Entra ID authentication: A service principal registered in Microsoft Entra ID with a valid client secret. The service principal must be added to the Databricks workspace and granted access to the required resources. For details, see Manage service principals in the Databricks documentation.
-
-
The system schema
ACCESSmust be enabled. Databricks system table schemas are disabled by default. For lineage extraction, the schemaACCESSis required and must be enabled.For instructions, see Enable system tables.
-
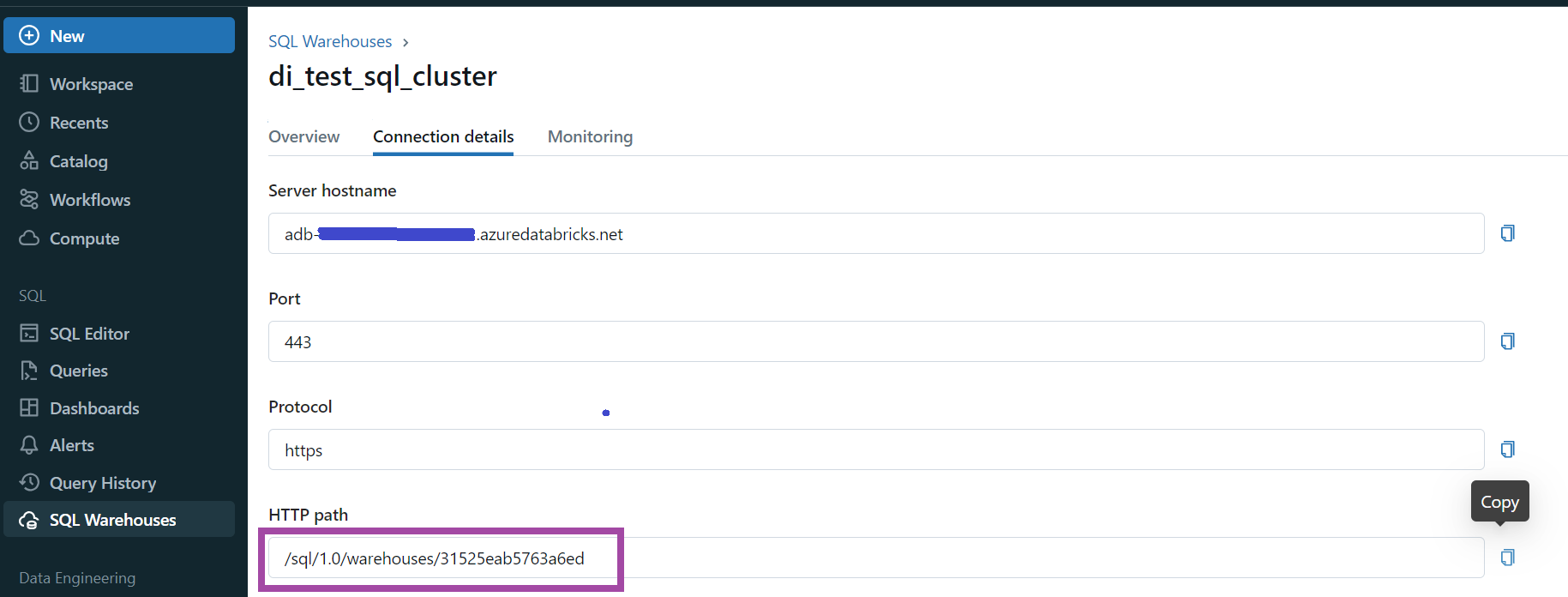
Databricks cluster or Databricks SQL warehouse for metadata extraction. For metadata extraction via JDBC, the scanner requires a Databricks all-purpose cluster or a Databricks SQL warehouse (see the configuration parameter
httpPath).We recommend using a serverless SQL warehouse. Size
X-SMALLshould be sufficient for most use cases.If the metadata extraction step takes a very long time (for example, more than 30 minutes), consider using a larger SQL warehouse.
-
Access to relevant data dictionary tables.
-
Access to Unity Catalog REST APIs.
-
Access to Databricks REST APIs.
Online scanner configuration
Fields that act as include or exclude filters (includeCatalogs, excludeCatalogs, includeSchemas, excludeSchemas) are case insensitive and support SQL-like wildcards, such as the percent sign (%) and underscore (_).
For example, to include all schemas ending with PROD, add the filter %PROD.
When trying to run the Databricks scanner, you are asked for the master password and the value of DATABRICKS_TOKEN.
|
All fields marked with an asterisk (*) are mandatory.
| Property | Description |
|---|---|
|
Identifies the source type to be scanned.
Must be set to |
|
A human-readable description of the scan. |
|
List of Ataccama ONE connection names for future automatic pairing. |
|
Lineage history in days.
For example, if set to |
|
Databricks host domain. |
|
Databricks compute resources URL. To find out your HTTP path, see Get connection details for a Databricks compute resource. See also Determine HTTP path for an SQL warehouse. |
|
Databricks workspace URL. |
|
Personal Access Token (PAT) used for JDBC connection and REST API authentication.
Required when |
|
The application (client) ID registered in the Microsoft Entra portal.
Found in App registrations > [app name] > Overview.
Required when |
|
The client secret value generated for the application in the Microsoft Entra portal (App registrations > [app name] > Certificates & secrets).
Required when |
|
The directory (tenant) ID of your Microsoft Entra instance.
Found in App registrations > [app name] > Overview.
Required when |
|
Restricts lineage extraction to a specified list of catalogs. All source catalog objects ( |
|
List of excluded catalogs. If one of the source catalog objects ( |
|
Restricts lineage extraction to a specified list of schemas. |
|
List of excluded schemas. If one of the source catalog objects ( |
{
"baseOutputFolderName": null,
"scannerConfigs": [
{
"sourceType": "DATABRICKS",
"description": "Scan Databricks for us-east region",
"lineageFromPastNDays": 30,
"host": "adb-4013958699284341.1.azuredatabricks.net",
"httpPath": "/sql/1.0/warehouses/31525eab5763a6ed",
"token": "@@ref:ata:[DATABRICKS_TOKEN]",
"workspaceUrl": "https://adb-4013958699284341.1.azuredatabricks.net",
"includeCatalogs": [
"prod_stage",
"prod_bi"
],
"excludeCatalogs": [
""
],
"includeSchemas": [
"silver",
"gld%"
],
"excludeSchemas": [
""
]
}
]
}
File-based Databricks scanner
Databricks system tables can be manually exported into a CSV file, which can then be processed to extract lineage information without a direct connection to Databricks.
| With file-based processing, Databricks Notebook metadata enrichment is not available. |
Export lineage metadata to CSV
Use the following SQL query to extract lineage metadata to CSV format.
| Before executing the query, change the default time range to seven days. This means that only lineage from the last seven days will be extracted. |
SQL query for extracting lineage metadata to CSV
WITH filtered_column_lineage AS (
SELECT
account_id,
metastore_id,
workspace_id,
entity_type,
entity_id,
entity_run_id,
source_table_full_name,
source_table_catalog,
source_table_schema,
source_table_name,
source_path,
source_type,
lower(source_column_name) AS source_column_name,
target_table_full_name,
target_table_catalog,
target_table_schema,
target_table_name,
target_path,
target_type,
lower(target_column_name) AS target_column_name,
event_time
FROM system.access.column_lineage l
WHERE source_column_name IS not null
AND target_column_name IS not null
AND event_time > current_date() - INTERVAL 7 DAYS
QUALIFY
(source_table_name is null OR target_table_name is null OR
(row_number() OVER (PARTITION BY source_table_full_name, target_table_full_name, lower(source_column_name), lower(target_column_name) ORDER BY event_time DESC) = 1))
)
SELECT lin.*,
dense_rank() OVER (ORDER BY lin.source_table_full_name, lin.target_table_full_name, lin.entity_id, lin.entity_run_id, lin.event_time DESC) as unique_transformation_id,
src_tab.table_name as source_table_name_from_data_dict,
lower(src_col.column_name) as source_column_name_from_data_dict,
trg_tab.table_name as target_table_name_from_data_dict,
lower(trg_col.column_name) as target_column_name_from_data_dict
FROM filtered_column_lineage lin
LEFT JOIN system.information_schema.tables src_tab ON
src_tab.table_catalog = lin.source_table_catalog AND
src_tab.table_schema = lin.source_table_schema AND
src_tab.table_name = lin.source_table_name
LEFT JOIN system.information_schema.columns src_col ON
src_col.table_catalog = lin.source_table_catalog AND
src_col.table_schema = lin.source_table_schema AND
src_col.table_name = lin.source_table_name AND
lower(src_col.column_name) = lin.source_column_name
LEFT JOIN system.information_schema.tables trg_tab ON
trg_tab.table_catalog = lin.target_table_catalog AND
trg_tab.table_schema = lin.target_table_schema AND
trg_tab.table_name = lin.target_table_name
LEFT JOIN system.information_schema.columns trg_col ON
trg_col.table_catalog = lin.target_table_catalog AND
trg_col.table_schema = lin.target_table_schema AND
trg_col.table_name = lin.target_table_name AND
lower(trg_col.column_name) = lin.target_column_name;File-based scan configuration
All fields marked with an asterisk (*) are mandatory.
| Property | Description |
|---|---|
|
Authentication method to use.
Possible values: |
|
Identifies the source type to be scanned.
Must be set to |
|
A human-readable description of the scan. |
|
List of Ataccama ONE connection names for future automatic pairing. |
|
Path to the column lineage CSV file. Can be an absolute or relative path. |
{
"scannerConfigs": [
{
"sourceType": "DATABRICKS",
"description": "Scan Databricks for us-east region",
"columnLineageFile": "work/databricks_column_lineage.csv"
}
]
}{
"baseOutputFolderName": null,
"scannerConfigs": [
{
"sourceType": "DATABRICKS",
"name": "DatabricksScan",
"description": "Scan Databricks using Entra ID service principal",
"authMethod": "ENTRA_ID",
"lineageFromPastNDays": 30,
"host": "adb-4013958699284341.1.azuredatabricks.net",
"httpPath": "/sql/1.0/warehouses/31525eab5763a6ed",
"clientId": "@@ref:ata:[DATABRICKS_CLIENT_ID]",
"clientSecret": "@@ref:ata:[DATABRICKS_CLIENT_SECRET]",
"tenantId": "@@ref:ata:[DATABRICKS_TENANT_ID]",
"workspaceUrl": "https://adb-4013958699284341.1.azuredatabricks.net",
"includeCatalogs": [
"prod_stage",
"prod_bi"
],
"excludeCatalogs": [
""
],
"includeSchemas": [
"silver",
"gld%"
],
"excludeSchemas": [
""
]
}
]
}FAQ
How do I configure lineage across multiple cloud regions
As there is a single Unity instance (and single Metastore) governing all catalogs, schemas, and tables within a Microsoft Azure, Amazon Web Services, or Google Cloud Platform region, a single Databricks connection can capture lineage only from a single cloud region. If you have Unity Catalog in multiple cloud regions, you need a separate lineage scan for each cloud region.
Was this page useful?