
Rule Types: DQ and Detection
This page builds on the concepts behind the end-to-end flow presented in Get Started with Data Quality.
Overview
Rules in ONE are split into two categories: detection rules and data quality evaluation rules (DQ rules). DQ rules are further split into what are called dimensions and you can define which dimensions will contribute to the overall quality calculation.
Detection rules and DQ rules can both be accessed and created from Data Quality > Rules but serve very different purposes in the platform:
-
Detection rules identify catalog item attributes to which a particular business term should be applied, based on the data or metadata. They are applied to terms themselves, and these terms are applied to attributes which in turn satisfy the condition of the rule. Multiple detection rules can be applied to one term.
Detection rules run during profiling, to identify and classify attributes and catalog items according to the rules condition.
-
DQ evaluation rules evaluate the quality of catalog items and their attributes. They are applied to terms, and then subsequently applied to attributes containing those terms for effective large-scale data evaluation.
DQ evaluation rules run during DQ evaluation in the data catalog, in monitoring projects, or as part of data observability.
In monitoring projects, DQ rules are applied directly to catalog item attributes. It is also possible to map DQ rules to individual attributes to run localized DQ evaluation in the Data Catalog.
This is useful, for example, in cases where results have been exported from monitoring projects, remediated in ONE Data, and now, you want to re-evaluate them from the catalog.
The results of these rules can be seen on the Data Quality tab of a catalog item, attribute, or the term itself, or in monitoring projects.
More about detection rules
Detection rules are used for rule-based term detection during profiling and data discovery. There are two types of detection rules, which can be used together or separately on a term:
-
Data-based rules that evaluate attribute data. A typical use case might be to assign terms to attributes that contain values matching those in a certain reference dataset (for example, a ONE Data table containing a list of first names). In this scenario:
-
A detection rule is created with the condition that when an attribute value is in the specified reference table, then Detect Term.
-
On the appropriate term (for example,
First Name), the newly created detection rule is chosen after selecting Add Rules on the term Settings tab.In addition, the term threshold is defined, that is, the percentage of values which should satisfy the rule conditions in order for the term to be applied to the attribute.
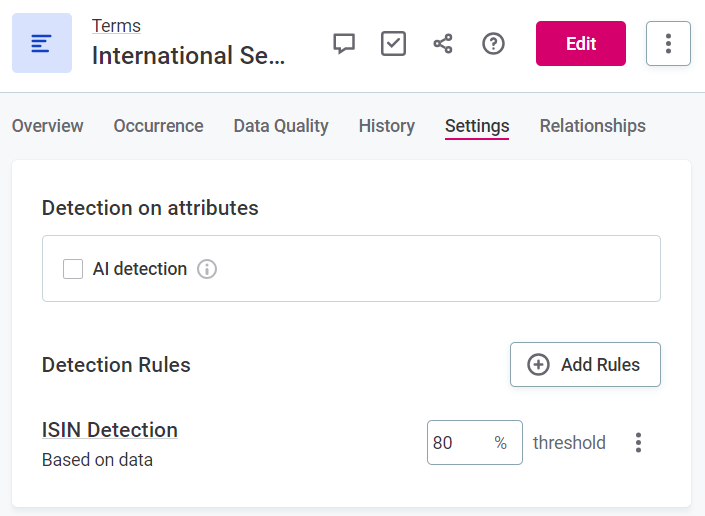
-
The term is added to attributes which match the rule condition and the threshold during data discovery or evaluation.
-
-
Metadata-based rules that apply terms based on information such as the names or descriptions of attributes, catalog items, locations, and data sources, or even attribute comments.
Metadata-based rules can be quite performance heavy.
It is possible to temporarily exclude some metadata rules from the term detection process during profiling. This is suggested in cases where there is a large number of attributes to profile.
To do this, go to Global Settings > Term Detection and enable Limit detection based on metadata to improve performance.

Terms with both metadata- and data-based rules still participate in detection if the rules are connected using the
ANDoperator. IfORis used, only the data-based rules are applied.
Creation of detection rules is handled by going to Data Quality > Rules. Configuration of the rules can also be carried out in the Data Quality sections of the platform, but once they are created, most of the interaction with detection rules is within Business Glossary and Data Catalog where rules are added to terms, and where terms are added to your data as a result of these rules, respectively.
|
Although enabled from the same section, AI term detection and detection rules work independently. Detection rules are not AI-powered. See Terms For details about the Term Suggestions algorithm, refer to Term Suggestions: Behind the Scenes. |
More about DQ evaluation rules
DQ evaluation rules are used to evaluate data based on a specific dimension. These affect the rules in two ways:
-
Depending on the dimension selected, different results are available in the rule condition builder (during rule implementation).
-
Results of rules from contributing dimensions are included in the calculation of the Overall Quality metric which can be seen on the Data Quality tab for a catalog item or for the term itself, or in results and reports of monitoring projects.
For more information about contributing dimensions, see Data Quality Dimensions.
| All predefined glossary terms come with preconfigured DQ rules that evaluate one or more data quality dimensions. |
Data quality rules can be applied to terms, and in turn, indirectly applied to attributes and catalog items to which those terms are mapped. You can also apply data quality rules directly to catalog item attributes manually within monitoring projects or in the Data Catalog. For more information, see Add DQ Rules to Attributes.
Data quality rules in ONE evaluate the quality of catalog items in accordance with defined conditions. Within the context of the Knowledge Catalog and Business Glossary sections of the platform, this occurs during profiling or DQ evaluation. Within the context of the Data Quality section of the application, this occurs during monitoring.
A rule can evaluate as Not applicable when its matching condition is assigned a Not applicable result (provided the dimension has one defined). Such records are excluded from the overall quality percentage rather than counted as passed or failed. For details, see data-quality-dimensions.adoc#not-applicable-results.
DQ dimensions
Dimensions and their results are fully configurable but a number of predefined options exist:
-
Validity: By default, the possible results are Valid and Invalid, that is, if the condition is met, the data is valid or invalid. You could use this dimension when creating rules to verify the usability of the data (for example, regarding data format, data content or attribute relations).
-
Uniqueness: By default, the possible results are Unique, Not populated, and Not Unique. You could use this dimension when creating rules to verify that there are no duplicate values and only one instance appears in the dataset.
-
Completeness: By default, the possible results are Complete and Not complete. You could use this dimension when creating rules to verify that the value field is filled.
-
Accuracy: By default, the possible results are Accurate, No reference available, and Not accurate. You could use this dimension when creating rules to check whether values are accurate and reflect the true values, for example, based on reference data.
-
Timeliness: By default, the possible results are Timeliness ok, Minor delay, and Major delay. You could use this dimension when creating rules to verify whether data is available at the time it is needed.
To create a custom dimension, follow the instructions in Data Quality Dimensions.
Was this page useful?