
Hadoop Configuration
In on-premise deployments, the following properties are used to configure Hadoop and are provided in the dpe/etc/application-SPARK_HADOOP.properties file.
| Configuring Spark using Hadoop is currently supported only on the Linux platform. |
Basic settings
| Property | Data type | Description | ||
|---|---|---|---|---|
|
String |
Sets the script for customizing how Spark jobs are launched.
For example, you can change which shell script is used to start the job.
The script is located in the Set this to
The default value for Linux is |
||
|
String |
Points to the location of Ataccama licenses needed for Spark jobs.
The property should be configured only if licenses are stored outside of the standard locations, that is, the home directory of the user and the folder Default value: |
||
|
String |
Sets the Default value:
|
||
|
String |
Sets additional Java options and system properties for Spark jobs. You can use this to pass JVM arguments and configure runtime behavior. Some useful examples include:
Multiple options should be separated by spaces, for example: However, no spaces are allowed within a single value. |
||
|
String |
Configures Spark driver options.
For example, Default value: |
Cluster libraries
The classpath with all required Java libraries needs to include the dpe/lib/* folder.
The files in the classpath are then copied to the cluster.
You can also add custom properties for additional classpaths, for example, plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.cp.drivers, which would point to the location of database drivers.
To exclude specific files from the classpath, use the pattern !<file_mask>, for example, !guava-11*.
| Property | Data type | Description | ||
|---|---|---|---|---|
|
String |
The classpath delimiter used for libraries for Spark jobs. Default value: |
||
|
String |
The libraries needed for Spark jobs.
The files in the classpath are copied to the Hadoop cluster.
Spark jobs are stored as Default value: |
||
|
String |
Default value: |
||
|
String |
Excludes certain Java libraries and drivers that are in the same classpath but are not needed for Spark processing.
Each library needs to be prefixed by an exclamation mark (
Default value: |
||
|
String |
Required when using Kerberos and Yarn on some Hadoop distributions, such as Cloudera. Points to the keytab file that stores the Kerberos principal and the corresponding encrypted key that is generated from the principal password. See also |
||
|
String |
Required when using Kerberos and Yarn on some Hadoop distributions, such as Cloudera. The name of the Kerberos principal. See also |
Using Apache Knox
| This configuration option is available starting with versions 13.3.2, 13.5.0 and later. |
Apache Knox is an Apache gateway service for facilitating safe communication between your own Hadoop clusters and outside systems such as Ataccama’s. When you use Apache Knox, you need to have a ONE Runtime Server with Remote Executor component configured on your edge node.
In this deployment option, Data Procesing Engine (DPE) is located outside of Hadoop DMZ and communicates with Hadoop and ONE Runtime Server via REST API through Apache Knox API. DPE Spark jobs such as profiling, evaluations, and plans are started on the ONE Runtime Server instance (instead of DPE) on your edge node that has the remote executor enabled.
DPE itself uses two Knox services: Hive JDBC via Knox and ONE Runtime Server via a newly created Ataccama-specific Knox service. Browsing your data source such as Hive is done via a JDBC request from DPE through Knox and then directly to your Hive.
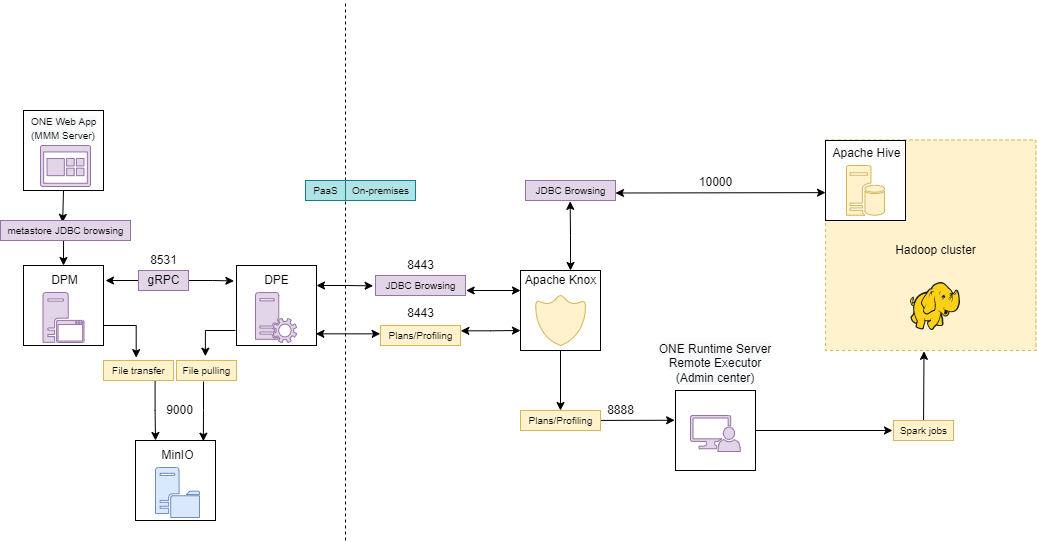
In order to configure DPE for Apache Knox, follow these steps:
-
Install ONE Runtime Server with Remote Executor on your edge node.
-
Configure your Knox to redirect requests to Remote Executor. For more information, see How to Secure Remote Executor with Apache Knox.
-
Enable
application-SPARK_KNOX.propertiesin theapplicaition.propertiesby addingspring.profiles.active=SPARK_KNOX. -
Configure your DPE using additional
application-SPARK_KNOX.propertiesindpe/etcfolder:Property Data type Description plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.cpdelimString
The classpath delimiter used for libraries for Spark jobs.
Default value:
;(semicolon).plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.lcp.runtimeString
Value:
../../../lib/runtime/*;../../../lib/jdbc/*;../../../lib/jdbc_ext/*.Classpath properties are defined using lcpto indicate a local classpath so as to not copy all jar files to the Hadoop via DPE and Knox but rather directly use those installed on the edge node.plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.lcp.ovrString
Value:
../../../lib/ovr/*.plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.lcp.extString
Value:
../../../lib/ext/*.plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.gatewayString
The URL where Apache Knox redirects all communication.
Value:
https://<host>:8443/gateway/default/bde/executor.The default port for Apache Knox is
8443.plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.authString
In order to use Apache Knox set to
basic. DPE uses a username and password to authenticate with Knox.plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.exec=${ataccama.path.root}/bin/knox/exec_knox.shString
The script for Apache Knox.
-
Configure your metastore to be able to browse your datasource. See Metastore Data Source Configuration.
Authentication
There are two available modes of authentication: basic and Kerberos.
For basic authentication, you only need to provide the username (SPARK.basic.user property).
| Property | Data type | Description | ||
|---|---|---|---|---|
|
String |
The username for data processing on the cluster. Used only for basic authentication. Default value: |
||
|
String |
The type of authentication.
Available options: To use Apache Knox, set to
Default value: |
||
|
Boolean |
If set to If the property is not set, the option is enabled by default. Used only for Kerberos authentication. |
||
|
String |
Points to the Kerberos configuration file, typically called Default value: |
||
|
String |
Points to the keytab file that stores the Kerberos principal and the corresponding encrypted key that is generated from the principal password. Used only for Kerberos authentication. To use a Kerberos ticket instead of the keytab file, comment out the this property. Default value: |
||
|
String |
The name of the Kerberos principal. The principal is a unique identifier that Kerberos uses to assign tickets for granting access to different services. Used only for Kerberos authentication. Default value: |
Advanced configuration
Temporary storage
The following properties define the default folders for storing local files on the Hadoop Distributed File System (HDFS) or on the local file system.
| Property | Data type | Description |
|---|---|---|
|
String |
The location of the folder for user files on HDFS. Default value: |
|
String |
Points to the location of libraries for Spark on HDFS. Default value: |
|
String |
Indicates where the Hadoop worker node is located on the local file system. Default value: |
|
Boolean |
If set to |
|
Number |
Defines the default permissions for HDFS, specifically the umask applied when files and folders are created. Default value: |
Spark configuration
All properties with the spark prefix are passed to Spark.
Two properties are required: SPARK.spark.master and SPARK.spark.io.compression.codec.
You can also add new custom properties by following this pattern: plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.spark.<custom_property_name>.
| Property | Data type | Description | ||
|---|---|---|---|---|
|
String |
The master node of the Spark cluster. Spark can only be run on YARN; other modes are not supported. Required.
Must be set to |
||
|
String |
Specifies how Spark is deployed: using worker nodes ( Default value: |
||
|
String |
Defines which support is used for external catalog implementation on Spark. Default value: |
||
|
String |
The Hive metastore version. Default value: |
||
|
String |
Points to the libraries for the Hive metastore.
You can use the libraries that are bundled with Spark ( Default value:
|
||
|
String |
The URL of the Spark history server. Default value: |
||
|
Boolean |
Enables event logging on Spark. Default value: |
||
|
String |
Defines where Cloudera or Hortonworks logs are stored. Default value:
|
||
|
String |
Sets the compression method for internal data. Required.
Must be set to |
||
|
Number |
Determines how many times YARN tries to submit the application. For debugging, set the value to a number higher than 1. Default value: |
||
|
String |
The name of the queue to which YARN submits the application. Default value: |
||
|
Boolean |
If set to The latest partition corresponds to the first partition listed when all partitions are sorted in alphanumeric order. If that partition consists of two or more columns, the higher level partition is used; however, all lower level partitions are included as well. For example, if there are two partitions, |
||
|
Boolean |
If set to
|
Performance optimization
| Property | Data type | Description |
|---|---|---|
|
Boolean |
Enables dynamic allocation of resources on Spark.
If set to Default value: |
|
Number |
Defines the maximum number of executors that can be used on Spark. Used if dynamic allocation of resources is enabled. Default value: |
|
Number |
Defines the minimum number of executors that are used on Spark. Used if dynamic allocation of resources is enabled. Default value: |
|
Number |
Specifies how many cores need to be used for each executor. If the property is set, multiple executors can use the same worker node provided that the node has sufficient resources for all executors. Default value: |
|
Number |
If the dynamic allocation of resources is not enabled, the property specifies how many executors are used on Spark.
If the dynamic allocation is enabled, the number specified here is used as the initial number of executors provided that the value is higher than the value of the property Default value: |
|
String |
Determines how much memory is allocated to each executor process. Default value: |
|
Boolean |
Enables the shuffle service. This is helpful for dynamic allocation, as the shuffle files of executors are saved and the executors that are no longer needed can be removed with no issues. Default value: |
Spark environment variables, debugging, and configuration
| Property | Data type | Description |
|---|---|---|
|
Boolean |
Enables the debugging mode. The debug mode shows the driver and the executor classloaders used in Spark, which lets you detect any classpath conflicts between the driver and the executor. Default value: |
|
String |
Points to the folder containing Hadoop client configuration files for the given cluster, such as Default value: |
|
String |
Sets the Default value:
|
|
Boolean |
If set to Required for Cloudera’s CDH distribution of Hadoop. Default value: |
|
Boolean |
If set to Default value: |
|
Boolean |
Enables the debug logging level for Log4j. Default value: |
|
Boolean |
If set to Default value: |
|
String |
The name of the script that launches the bundled application on the given cluster. Default value: |
|
Boolean |
Enables the YARN timeline service. The timeline service is used to collect and provide application data and metrics about the current and historical states of the application. Default value: |
Was this page useful?