
Databricks Configuration
Ataccama ONE is currently tested to support the following Databricks versions: 11.3, 12.2, 13.3, 14.3, and 15.4.
The following properties are used to configure Databricks and are provided in the dpe/etc/application-SPARK_DATABRICKS.properties file.
Check that spring.profiles.active property in DPE application.properties is set to SPARK_DATABRICKS profile.
To add your Databricks cluster as a data source, see Metastore Data Source Configuration for Databricks.
Basic settings
| Property | Data type | Description | ||
|---|---|---|---|---|
|
String |
Sets the script for customizing how Spark jobs are launched.
For example, you can change which shell script is used to start the job.
The script is located in the The default value for Linux is |
||
|
String |
Points to the location of Ataccama licenses needed for Spark jobs.
The property should be configured only if licenses are stored outside of the standard locations, that is the home directory of the user and the folder Default value: |
||
|
String |
Sets the Default value:
|
||
|
String |
Sets additional Java options and system properties for Spark jobs. You can use this to pass JVM arguments and configure runtime behavior. Some useful examples include:
Multiple options should be separated by spaces, for example: However, no spaces are allowed within a single value. |
||
|
Boolean |
Enables the debugging mode. The debug mode shows the driver and the executor classloaders used in Spark, which lets you detect any classpath conflicts between the Ataccama classpath and the Spark classpath in the Spark driver and in the Spark executors. Default value: |
||
|
Boolean |
Tests whether the cluster has the correct mount and libraries. Turning the cluster check off speeds up launching jobs when the cluster libraries have already been installed and there are no changes made to the runtime. In that case, checking is skipped. Default value: |
||
|
Boolean |
Enables automatic mounting of internal Azure Storage to Azure Databricks, which simplifies the installation and configuration process. This requires saving of Azure Storage credentials in configuration settings. Default value: |
||
|
Number |
Specifies how many jobs can be run in parallel. Default value: |
||
|
Boolean |
If set to Default value: |
||
|
Boolean |
If set to Default value: |
||
|
String |
The folder in the Databricks File System that is used as a mount point for the Azure Data Lake Storage Gen2 folder. Default value: |
||
|
String |
The location of the ADLS Gen2 folder for storing libraries and files for processing.
The folder is then mounted to the directory in the Databricks File System defined in the property Default value: |
||
|
Boolean |
Defines where lookup files are created.
If set to Default value: |
Cluster libraries
The classpath with all required Java libraries needs to include the dpe/lib/* folder.
The files in the classpath are then copied to the cluster.
You can also add custom properties for additional classpaths, for example, plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.cp.drivers, which would point to the location of database drivers.
To exclude specific files from the classpath, use the pattern !<file_mask>, for example, !guava-11*.
| Property | Data type | Description | ||
|---|---|---|---|---|
|
String |
The classpath delimiter used for libraries for Spark jobs. Default value: |
||
|
String |
The libraries needed for Spark jobs.
The files in the classpath are copied to the Databricks cluster.
Spark jobs are stored as For Spark processing of Azure Data Lake Storage Gen2, an additional set of libraries is required: Default value: |
||
|
String |
Points to additional override libraries that can be used for miscellaneous fixes. Default value: |
||
|
String |
Points to additional Databricks libraries. Default value: |
||
|
String |
Excludes certain Java libraries and drivers that are in the same classpath but are not needed for Spark processing.
Each library needs to be prefixed by an exclamation mark (
Default value: |
||
|
String |
Excludes certain Java libraries and drivers that are in the local classpath.
Each library needs to be prefixed by an exclamation mark ( Default value: |
||
|
String |
Points to the local external libraries. Default value: |
||
|
String |
Excludes certain Databricks libraries from file synchronization between the ONE runtime engine and the libraries installed in Databricks. Libraries that are installed within the cluster and matched by this property are not uninstalled before the job run even if they are not part of ONE runtime. Other libraries (that is, those that are not part of ONE runtime and not matched by the property) are uninstalled before the job start. The property can also be set to a valid regular expression. Default value: |
||
|
Boolean |
Libraries stored in the DBFS root. Default value:
Alternative for restricted clusters: For clusters that don’t allow library installation from S3/ADLS, use volume storage for libraries. See Databricks volume storage. To re-enable storing libraries in the DBFS root, change this property to |
Databricks volume storage
| This feature enables storing Databricks libraries in Unity Catalog volumes instead of DBFS. This is required for clusters that restrict library installation from cloud storage (S3/ADLS) and is available for Databricks runtime 13.3 LTS and above. To learn more, see volumes in the Databricks documentation. |
Add the following properties to configure Databricks to use volume storage for libraries:
| Property | Data type | Description |
|---|---|---|
|
Boolean |
Enables volume storage for libraries.
When set to Default value: |
|
String |
Specifies the location of libraries within the volume. Example value: |
|
Boolean |
Controls automatic library upload and installation when using volume storage.
If Default value: |
|
Boolean |
Used when volume storage requires custom job configuration.
When set to Default value: |
|
String |
Name of the job when using all-purpose cluster.
Use this to specify a custom job name or reference an existing job.
Relevant if |
|
String |
Name of the job when using job cluster.
Use this to specify a custom job name or reference an existing job.
Relevant if |
|
String |
Relevant when |
Amazon Web Services
If you are using Databricks on Amazon Web Services, you need to set the following properties as well as the authentication options. The same user account can be used for mounting a file system and for running jobs in ONE.
| Property | Data type | Description | ||
|---|---|---|---|---|
|
String |
Optional list of credential providers. Should be specified as a comma-separated list. If unspecified, a default list of credential provider classes is queried in sequence.
|
||
|
String |
The access key identifier for the Amazon S3 user account. Used when mounting the file system. |
||
|
String |
The secret access key for the Amazon S3 user account. Used when mounting the file system. |
||
|
String |
The access key identifier for the Amazon S3 user account. Used when configuring Ataccama jobs. |
||
|
String |
The secret access key for the Amazon S3 user account. Used when configuring Ataccama jobs. |
||
|
Boolean |
Enables fast upload of data. For more information, see How S3A Writes Data to S3. Default value: |
||
|
String |
Configures how data is buffered during fast upload.
Must be set to Default value: |
Azure Data Lake Storage Gen2
When using Databricks on Azure Data Lake Storage Gen2, it is necessary to configure these properties and enable authentication. You can use the same user account for mounting the file system and for running Ataccama jobs.
| Property | Data type | Description |
|---|---|---|
|
String |
The type of access token provider. Used when mounting the file system. Default value: |
|
String |
The token endpoint. A request is sent to this URL to refresh the access token. Used when mounting the file system. Default value: |
|
String |
The client identifier of the ADLS account. Used when mounting the file system. |
|
String |
The client secret of the ADLS account. Used when mounting the file system. |
|
String |
Enables the Azure Data Lake File System. Default value: |
|
String |
The type of access token provider. Used when running Ataccama jobs. Default value: |
|
String |
The token endpoint used for refreshing the access token. Used when running Ataccama jobs. Default value: |
|
String |
The client identifier of the ADLS account. Used when running Ataccama jobs. |
|
String |
The client secret of the ADLS account. Used when running Ataccama jobs. |
Databricks job cluster configuration
Depending on your use case, you can choose between two types of clusters to use with Databricks.
| Cluster type | Description | Pros | Cons |
|---|---|---|---|
All purpose cluster |
Perpetually running generic cluster (with auto-sleep) that is configured once and can run multiple Spark jobs at once. |
|
|
Job cluster |
The Databricks job scheduler creates a new job cluster whenever a job needs to be run and terminates the cluster after the job is completed. |
|
The following table includes the default configuration of jobCluster.
|
If you want to enable the job cluster when you upgrade from an earlier version, add and define the necessary properties from the following table and Spark configuration in the |
| The property column in the following table and Spark configuration includes default or example values you should replace depending on your use case. |
| Property | Data type | Description |
|---|---|---|
|
Boolean |
To enable the job cluster, set the property to Default value: |
|
Boolean |
Checks whether the configuration has changed since the last job cluster was created. Default value: |
|
String |
Defines the suffix of jobs run on the cluster.
For example, if Default value: |
|
String |
Defines the Spark version used on the cluster. |
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.resources.node_type_id=Standard_D3_v2 Or plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.resources.instance_pool_id=0426-110823-bided16-pool-x2cinbmv |
String |
Sets the driver and the worker type. This property does not have a default value. Must be set to If you are using an |
|
Integer |
Defines the number of workers If you use autoscaling, there is no need to define this property. Default value: |
|
Boolean |
Enables autoscaling.
If set to Default value: |
|
Integer |
Defines the minimum number of workers when using autoscaling. Only applies if autoscaling is enabled. Default value: |
|
Integer |
Defines the maximum number of workers when using autoscaling. Only applies if autoscaling is enabled. Default value: |
|
Boolean |
When enabled, this cluster dynamically acquires additional disk space when its Spark workers are running low on disk space. This feature requires specific AWS permissions to function correctly. For more information, see the official Databricks documentation. |
|
Array of String |
SSH public key contents that will be added to each Spark node in this cluster. The corresponding private keys can be used to login with the user name ubuntu on port 2200. Up to 10 keys can be specified. |
|
An object containing a set of tags for cluster resources.
Databricks tags all cluster resources (such as AWS instances and EBS volumes) with these tags in addition to |
|
|
String |
DBFS destination.
For example, |
|
S3 location of cluster log.
|
|
|
INT32 |
The max price for AWS spot instances, as a percentage of the corresponding instance type’s on-demand price.
If not specified, the default value is |
|
INT32 |
The first |
|
Availability type used for all subsequent nodes past the |
|
|
Workspace location of init script.
Destination must be provided.
For example, |
|
|
S3 location of init script.
Destination and either region or warehouse must be provided.
For example, |
|
|
(Deprecated) DBFS location of init script.
Destination must be provided.
For example, |
|
|
An object containing a set of optional, user-specified environment variable key-value pairs.
Key-value pair of the form (X,Y) are exported as is (i.e., export X='Y') while launching the driver and workers.
For example,: |
Descriptions for the enable_elastic_disk, ssh_public_keys, custom_tags, cluster_log_conf, spot_bid_price_percent, first_on_demand, availability, workspace, dbfs, s3 and spark_env_vars fields are as defined by the official Databricks documentation.
|
Advanced job cluster options Spark configuration
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.spark.driver.extraJavaOptions=-Dsun.nio.ch.disableSystemWideOverlappingFileLockCheck=true
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.spark.hadoopRDD.ignoreEmptySplits=false
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.spark.serializer=org.apache.spark.serializer.KryoSerializer
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.spark.databricks.delta.preview.enabled=true
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.spark.kryoserializer.buffer.max=1024m
# Storage account (example for Azure Data Lake Storage Gen2)
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.fs.azure.account.auth.type.ataccamadatalakegen2.dfs.core.windows.net=OAuth
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.fs.azure.account.oauth2.client.id.ataccamadatalakegen2.dfs.core.windows.net=<;application-id>
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.fs.azure.account.key.ataccamadatalakegen2.dfs.core.windows.net=<;account key>
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.fs.azure.account.oauth.provider.type.ataccamadatalakegen2.dfs.core.windows.net=org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.fs.azure.account.oauth2.client.secret.ataccamadatalakegen2.dfs.core.windows.net=<;secret>
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.job-cluster.spark-conf.fs.azure.account.oauth2.client.endpoint.ataccamadatalakegen2.dfs.core.windows.net=https://login.microsoftonline.com/<directory-id>/oauth2/tokenTroubleshooting
Jobs not triggered when Databricks cluster is sleeping
- Problem
-
No jobs are being created in DPM when profiling, DQ evaluation, or monitoring projects are being run while the Databricks cluster is sleeping. Before jobs are triggered, MMM tries to get new information about the table schema. Since the cluster is not running, it waits for the cluster to start up and the job will be submitted only after it gets new information about the table schema (about five minutes after the cluster wakes up).
This issue also affects browse, metadata import, data preview, and SQL catalog item creation on Databricks connections.
- Possible solution
-
Use SQL Warehouse for browsing and change from
All purpose clustercluster type toJob cluster. SQL Warehouse for browsing starts within seconds and not minutes and can get the latest schema information quickly, meaning the jobs can be triggered.
This can be achieved by creating a new serverless SQL warehouse in Databricks and replacing the value for plugin.metastoredatasource.ataccama.one.cluster.[cluster_name].url with the warehouse URL.
To do this:
-
In Databricks, select the SQL warehouses tab and then select Create SQL warehouse.
-
Create a new SQL warehouse, type
Serverless.This warehouse needs to have access to your data. 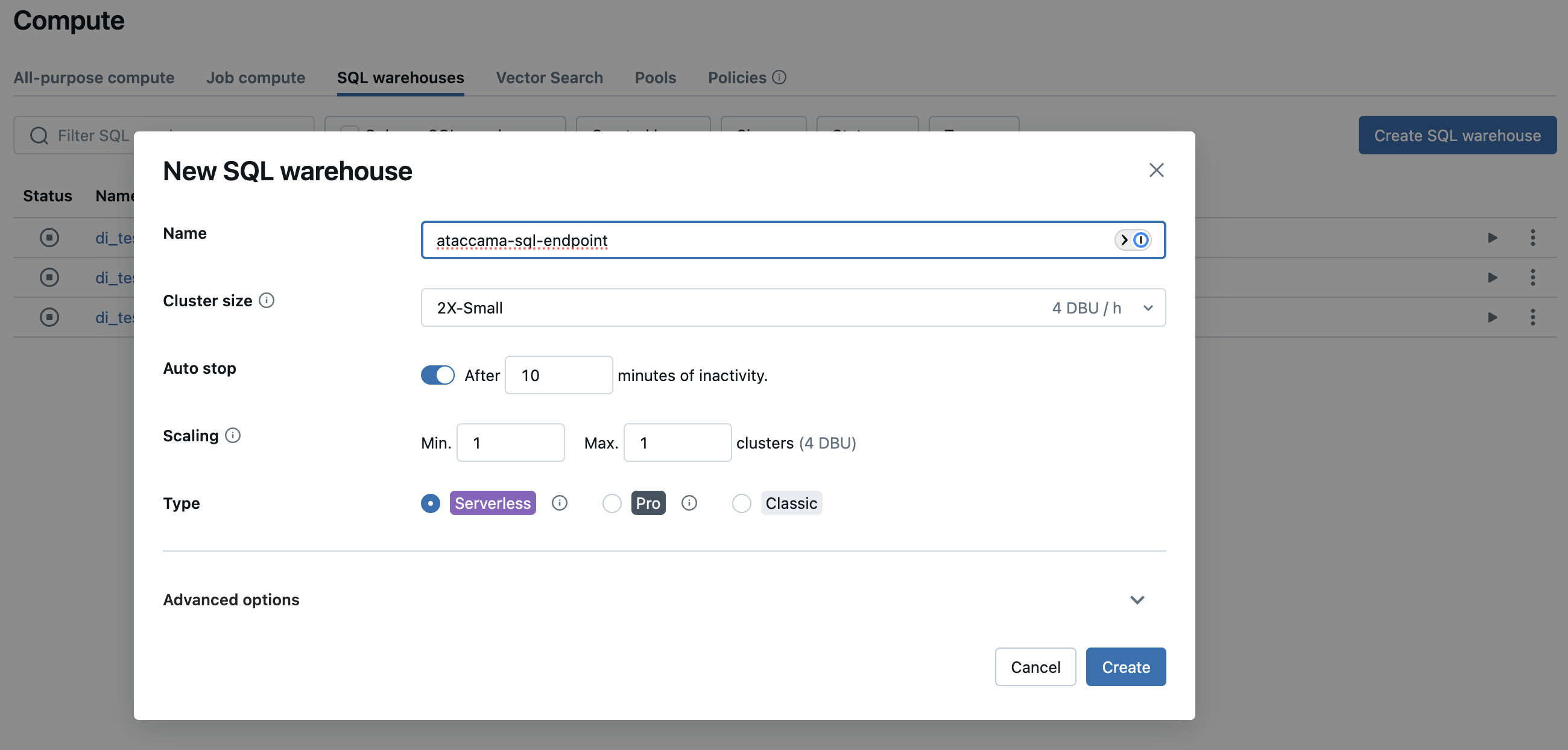
-
Obtain the JDBC URL of the newly-created SQL warehouse from the Connection details tab.
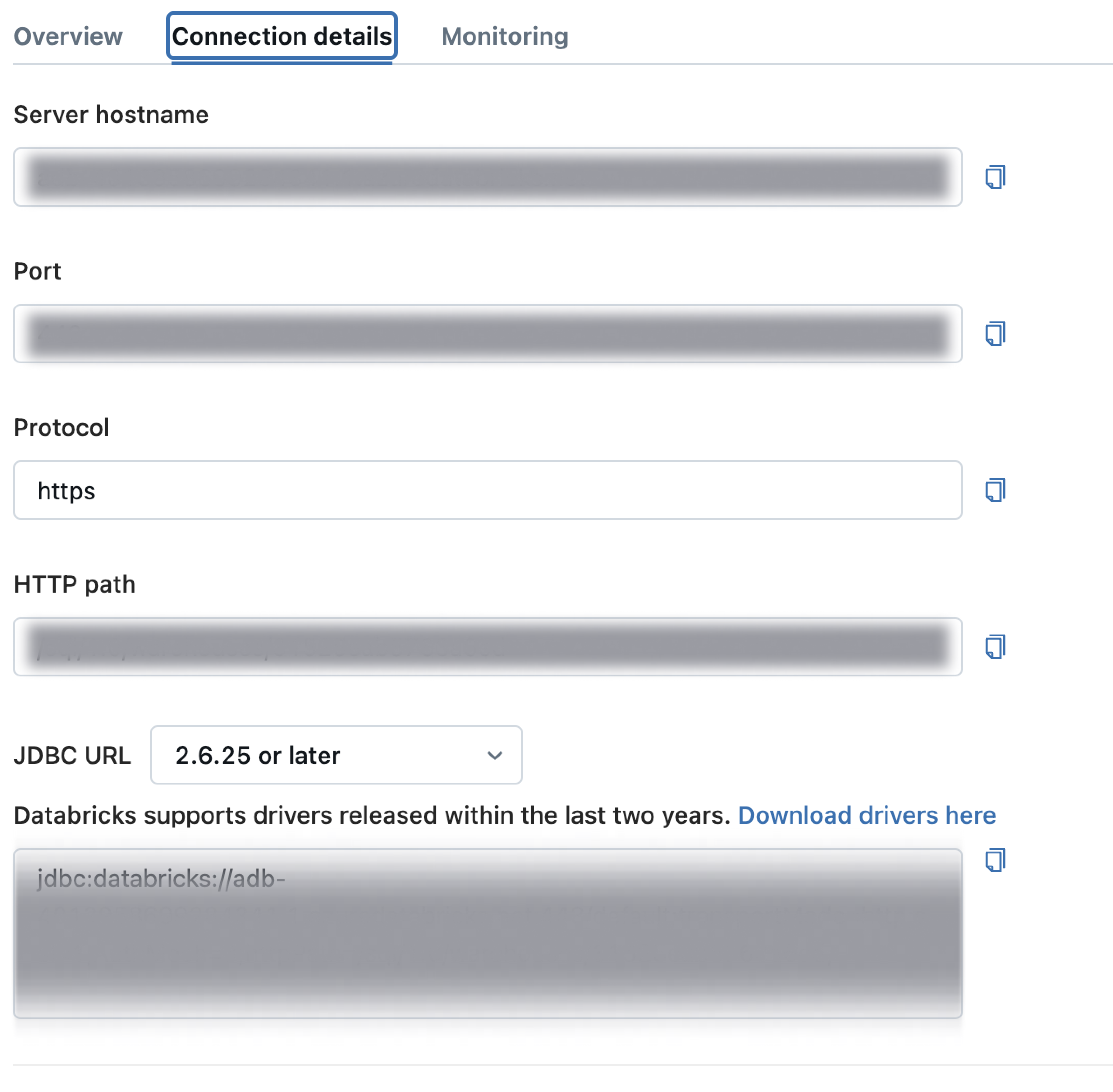
For the next step, contact Ataccama Support.
-
In
dpe/etc/application.properties, provide this URL as the value for `plugin.metastoredatasource.ataccama.one.cluster.[cluster_name].url. For more information, see configuration-reference-metastore-data-source-configuration.adoc.
Was this page useful?