
Snowflake Pushdown Processing
Processing for your Snowflake connection can be handled in two ways:
-
Use Ataccama ONE Data Processing Engines (DPEs) for all data quality processing (DQ evaluation jobs, profiling, monitoring projects, and data observability), which may require multiple engines and data transfer depending on the project scale.
-
Run processing directly in Snowflake by enabling pushdown.
This article outlines the benefits and limitations of Snowflake pushdown processing in ONE and provides setup instructions.
| Get in touch with your Customer Success Manager to enable this feature. |
| Pushdown processing is not available in ONE Desktop. |
Why use pushdown processing?
Using pushdown processing can lead to improvements in performance, security and infrastructure, and subsequently, scalability.
-
Performance. Evaluate millions of records in seconds.
-
Security. Data processing is executed directly in Snowflake, and results (and invalid samples, if configured) are returned. This means there is no transfer of data required or any external services or servers; all processes run on secured and governed Snowflake warehouses.
From a user perspective, the results are stored and appear the same as when DPE handles processing. -
Infrastructure. Utilize your existing infrastructure to evaluate data—no need to set up and manage new processing servers.
Prerequisites
There are two key parts when it comes to enabling pushdown processing. You must:
-
Configure Snowflake to allow Ataccama to transfer functions. Snowflake configuration is via worksheet which defines the working database and grants access to defined user roles.
-
Enable pushdown processing on the connection.
It is also necessary to make sure that DPE allows for automatic synchronization of user-defined functions. See DPE Configuration.
Configure Snowflake pushdown processing
Pushdown processing is enabled on the connection level.
To create a new Snowflake connection, follow the instructions in Snowflake Connection. To enable pushdown processing on an existing connection:
-
In Knowledge Catalog > Sources, select your Snowflake source.
-
Select the Connections tab.
-
For the required connection, use the three dots menu and select Edit.
-
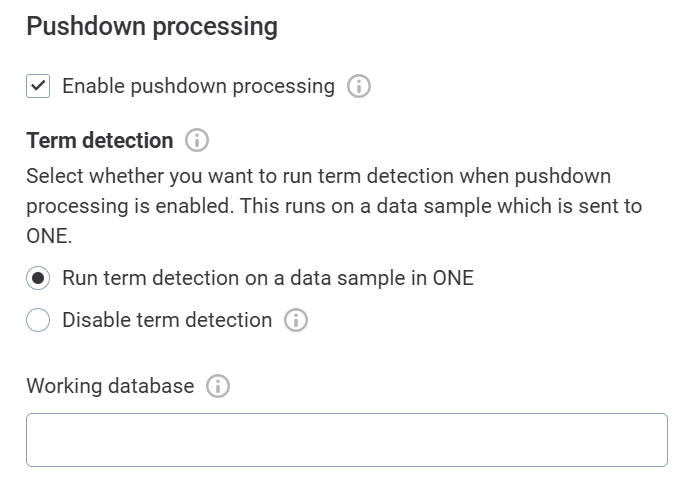
In the Pushdown processing section, select Enable pushdown processing.
-
Select whether you want to use Legacy pushdown.
Before selecting, verify that all DQ rules applied to catalog items and in monitoring projects on this connection are supported. See Supported rules.
To see all differences between the pushdown implementations, see Which pushdown processing to choose.
-
Choose whether you want to run term detection when pushdown processing is enabled, or disable term detection.
Term detection jobs (domain detection and fingerprints for AI term suggestions) can’t run in pushdown, so if you run term detection with pushdown enabled it runs on a data sample which is sent to ONE. -
Select Run term detection on a data sample in ONE to trigger detection jobs alongside profiling. Otherwise, select Disable term detection.
If you disable term detection, no terms are applied during profiling or documentation flows, and no term suggestions are shown for assets from this connection.
-
After enabling pushdown processing on a new or existing source:
-
In Working database, provide the name of the database you want to use for storing the stage, functions, and temporary tables created during profiling. You have two options:
-
Use the database that is being processed (default).
-
Create a custom database (recommended).
Additional setup in Snowflake is required. See Create the working database in Snowflake.
-
-
In Working schema, optionally specify a schema of your choice. If you use a custom schema, change the schema name in Step 6 of Create the working database in Snowflake. If you leave this blank, the
publicschema is used as default. -
Select Add JDBC role to add a JDBC role if you need to share the Snowflake pushdown setting across different credentials (for example, to a common underlying role).
Which pushdown processing to choose
Snowflake pushdown processing offers two implementations, controlled by the Legacy pushdown setting in the connection’s Pushdown processing section.
Disabling Legacy pushdown on a connection changes which capabilities, functions, and behaviors are supported in pushdown:
-
Capabilities gained: export invalid records from monitoring projects, run aggregation rules, and use lookups in DQ rules processed in pushdown.
-
Rule and function support differs: some rules and functions are supported only with Legacy pushdown enabled, others only when disabled. See Supported rules.
-
Additional limitations apply: custom DQC functions and lambdas, regex behavior, geospatial caveats. See Limitations when Legacy pushdown is turned off.
-
Performance improvement: DQ jobs that use lookups run faster.
To verify which pushdown implementation ran a specific job, see DPM Admin Console.
Create the working database in Snowflake
In Snowflake, you need to execute the following SQL commands to create a working database and grant access to defined user roles.
Make sure you run these commands from a SYSADMIN or ACCOUNTADMIN Snowflake account.
You can change role using, for example, USE ROLE ACCOUNTADMIN; or in the user interface, by selecting your profile name in the upper-right corner and choosing ACCOUNTADMIN from the role dropdown.
|
In Snowflake, select + Worksheet, and follow these instructions.
Step 1: Create a database
To create a new database, execute the following SQL command. Use the name you provided in the connection settings.
CREATE DATABASE IF NOT EXISTS <working_db>;
| The database can be deleted if you no longer want to use pushdown in ONE. Multiple users can reuse the same database if they have access to it. |
Step 2: Create a stage
Using the following command, create a stage called _ATC_ONE_STAGE.
CREATE STAGE IF NOT EXISTS _ATC_ONE_STAGE;
It is possible to use a custom stage name, but if you do you need to additionally run GRANT CREATE STAGE ON SCHEMA public TO ROLE <pushdown_role>; in step 6, and use your custom name rather than _ATC_ONE_STAGE in step 7.
|
Step 3: Create a role for Ataccama
This role gives ONE permission to load data into your database: this role needs to have read permissions on your data, and write permissions for the working database. We don’t recommend reusing this role for other operations.
CREATE ROLE IF NOT EXISTS <pushdown_role>; GRANT ROLE <read_data_role> TO ROLE <pushdown_role>;
|
This role needs to be specified in the JDBC connection string, for example: |
Step 4: Assign role to users
Assign your newly-created role to the relevant Snowflake users.
GRANT ROLE <pushdown_role> TO USER <sample_user>; GRANT ROLE <pushdown_role> TO USER <another_user>;
Step 5: Grant access to database
Grant access on the database you created in step 1 to the role you created in step 3. If no roles are specified here, all users have the access to the database.
GRANT USAGE ON DATABASE <working_db> TO ROLE <pushdown_role>;
Step 6: Grant access to schema
Grant access on the public schema of the database to the role you created in step 3.
GRANT USAGE ON SCHEMA public TO ROLE <pushdown_role>; GRANT CREATE TABLE ON SCHEMA public TO ROLE <pushdown_role>; GRANT CREATE SEQUENCE ON SCHEMA public TO ROLE <pushdown_role>; GRANT CREATE FUNCTION ON SCHEMA public TO ROLE <pushdown_role>;
If you specified a schema in Working schema, make sure to update the schema name here accordingly.
If you left it blank, public is used by default and no changes are required.
|
Step 7: Grant access to stage
Grant access on the stage of the database to the role you created in step 3.
GRANT READ ON STAGE _ATC_ONE_STAGE TO ROLE <pushdown_role>; GRANT WRITE ON STAGE _ATC_ONE_STAGE TO ROLE <pushdown_role>;
If you are using a custom stage name and not _ATC_ONE_STAGE, make sure to modify these commands accordingly.
|
Processing in Snowflake
The data quality processing configurations available in ONE are translated to Snowflake SQL language, either by utilizing native SQL functions or creating new functions. This is done by DPE so at least one DPE is still required to handle the translation of these configurations to Snowflake functions.
Pushdown uses Snowflake warehouse for computation, giving you easy control of resources used for computation. The size of Snowflake warehouse used determines the performance, so processing could be impacted if a small warehouse is used.
When can you use pushdown?
Pushdown processing in Snowflake can be used when running:
-
Profiling.
To optimize performance, some of the most infrequently used profiling stats such as frequency groups and quantiles for non-numeric attributes aren’t calculated. -
DQ evaluation using supported rules.
-
Monitoring projects.
-
Data observability (excluding term detection and AI-powered anomaly detection).
| For optimized performance and better cost efficiency, sample profiling always runs on Ataccama DPEs. Processing of very small data sets is better suited for non-pushdown operations because of SQL overhead. |
Processing is typically executed externally without a visual indication on the platform, except when an unsupported configuration is used. In such cases you see the following information: This condition can’t be applied on Snowflake with enabled pushdown. Similarly, in monitoring projects, if you try and apply an incompatible rule to a catalog item, you see a warning.
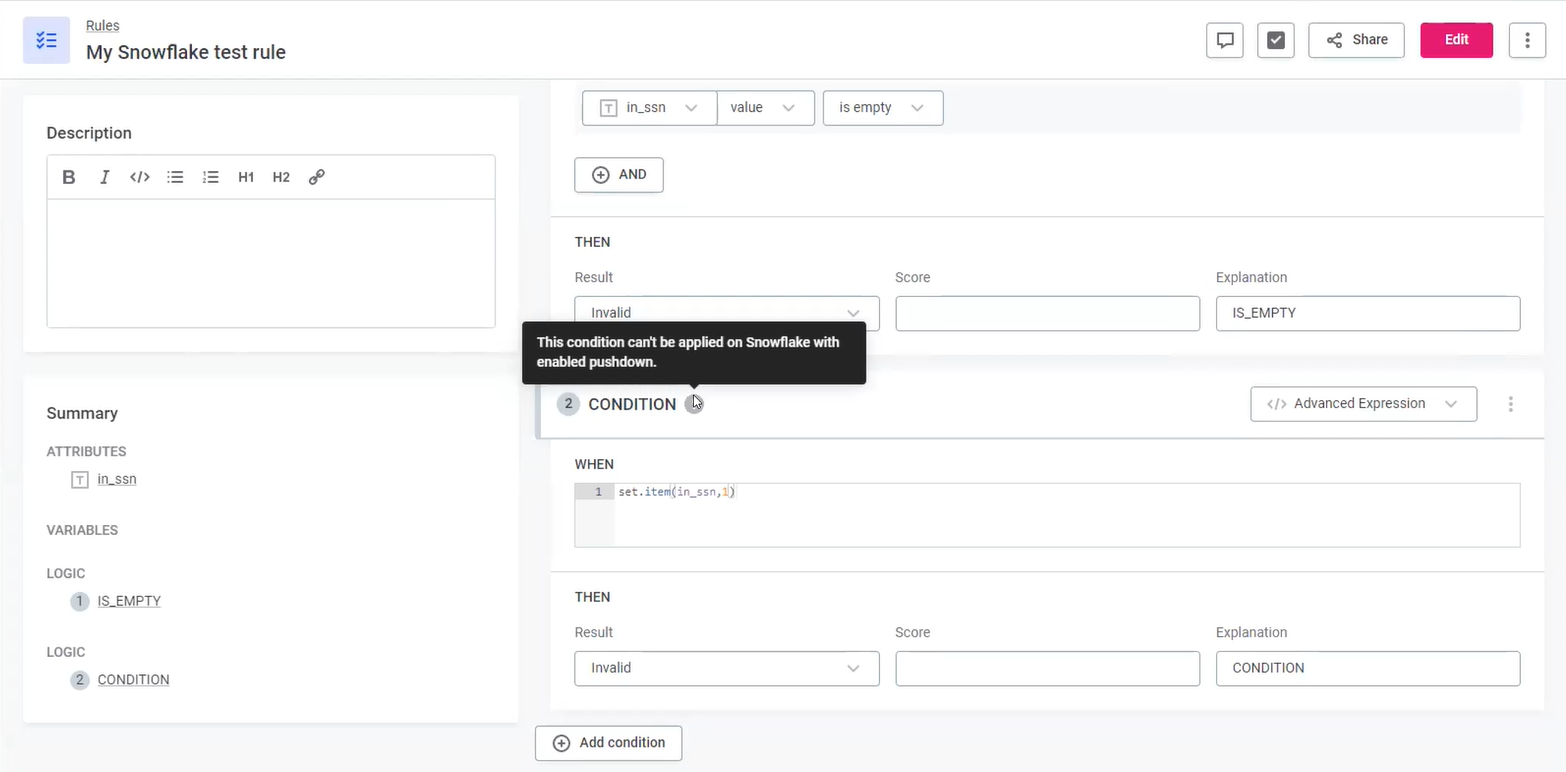
To use pushdown processing, you need to remove the rule or define an alternative configuration. For more information, see Supported rules.
Supported rules
The following rules are supported in Snowflake pushdown:
-
Rules created using the Condition Builder, as expression functions available in the condition builder are supported by pushdown.
-
Parametric rules.
-
Advanced Expression rules and rules using variables, as long as they include only Supported functions and operators.
-
Aggregation rules, when Legacy pushdown is disabled on the connection.
| Component rules are not currently supported. |
Verify rule support
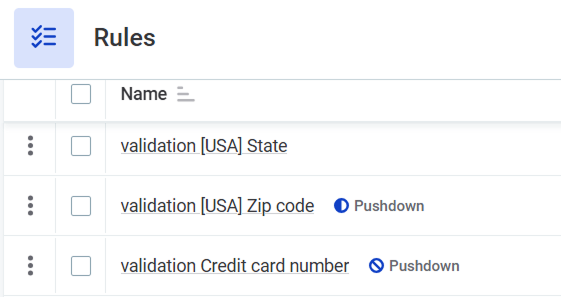
Rule support in pushdown is shown in two places, with different scopes:
Rule library (Data Quality > Rules): The pushdown support of a rule across all engines (independent of any specific connection) is shown by an icon next to each rule name.
-
No icon: The rule is supported in all pushdown engines.
-
Half-filled circle: The rule is supported in at least one pushdown engine. Hover over the icon for details.
-
No-entry sign: The rule is not supported in any pushdown engine.
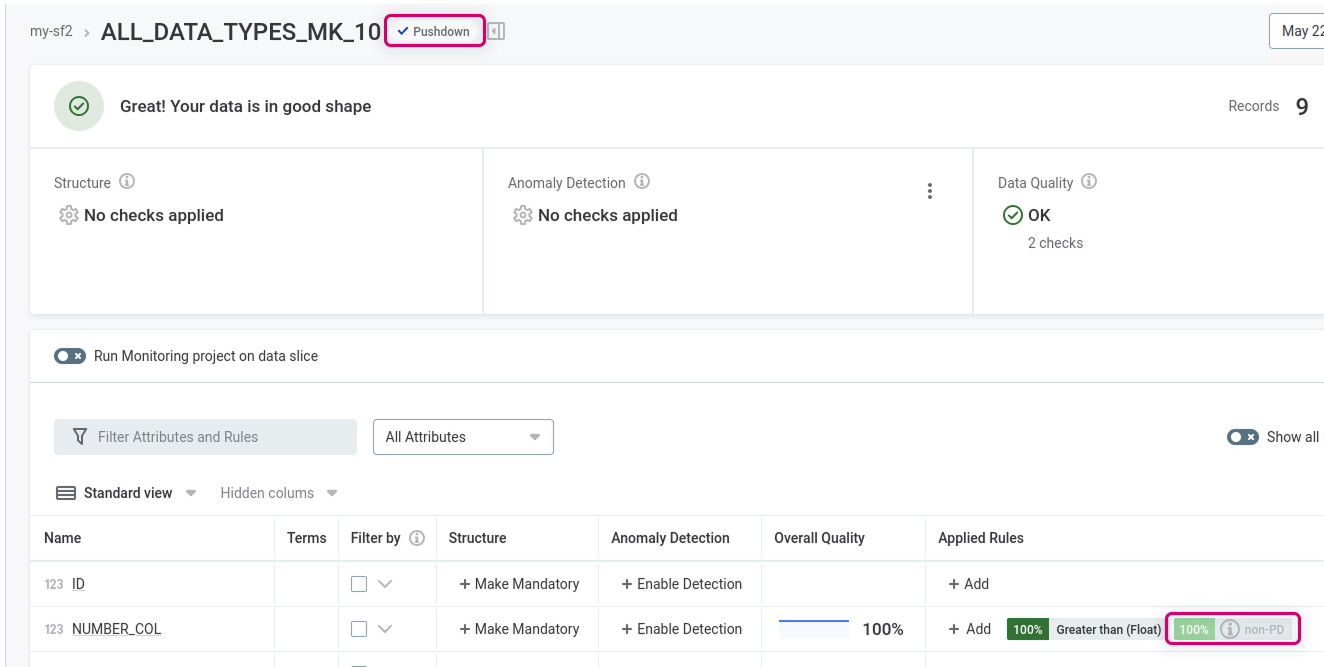
Monitoring projects: Unsupported rules for the specific connection are grayed out and shown with an info icon next to the rule name on the Configuration & Results tab. Such rules are ignored during monitoring project execution and excluded from data quality results. They do not prevent the monitoring project from running.
Supported functions and operators
Supported operators
-
+(concatenate for string, addition for numeric values) -
-(subtraction) -
*(multiplication) -
/(division) -
%(modulo) -
div(division of integer values without a remainder) -
AND -
NOT -
OR -
XOR -
< -
⇐ -
<>,!= -
=,== -
> -
>= -
case -
in -
is -
is in -
is not -
is not in -
is not null -
is null
Functions supported in both pushdown implementations
The following functions are supported whether Legacy pushdown is enabled or not.
-
containsWord -
dateAdd -
dateDiff -
datePart -
dateTrunc -
eraseSpacesInNames. See also Limitations. -
find -
getDate -
iif -
indexOf -
isInFile -
isNumber -
lastIndexOf -
left -
length -
like -
log10 -
lower -
matches -
math.abs -
math.acos -
math.asin -
math.atan -
math.ceil,math.ceiling -
math.cos -
math.e -
math.exp -
math.floor -
math.log -
math.log10 -
math.longCeil,math.longCeiling -
math.longFloor -
math.pi -
math.pow -
math.round -
math.sin -
math.sqr -
math.sqrt -
math.tan -
now -
removeAccents -
replace -
right -
squeezeSpaces -
substituteAll -
substr -
toDate -
toDateTime -
today -
toFloat -
toInteger -
toLong -
toString -
trashNonDigits -
trashNonLetters -
trim -
trimLeft -
trimRight -
upper
Functions supported only when Legacy pushdown is turned off
The following functions are supported only when Legacy pushdown is disabled:
-
avg -
avgif -
count -
countDistinct -
maximum -
maximumif -
minimum -
minimumif -
sum -
sumif
Functions supported only in Legacy pushdown
The following functions are supported only when Legacy pushdown is enabled. Review and adjust any rules that rely on them before turning off Legacy pushdown.
-
bitand -
bitneg -
bitor -
bitxor -
capitalize -
capitalizeWithException -
case -
coding.fromBase64 -
coding.md5 -
coding.toBase64 -
countNonAsciiLetters -
cpConvert -
decode -
diceCoefficient -
distinct -
doubleMetaphone -
editDistance -
encode.base64 -
encode.md5 -
geoDistance -
getMilliseconds -
getParameterValue -
getRequestTime -
getRuntimeVersion -
hamming -
jaccardCoefficient -
jaroWinkler -
levenshtein -
max -
metaphone -
min -
ngram -
nvl -
preserveCase -
random -
randomUUID -
replicate -
safeMax -
safeMin -
set.approxSymmetricDifference -
set.contains -
set.difference -
set.differenceResult -
set.intersection -
set.intersectionResult -
set.lcsDifference -
set.lcsDifferenceResult -
set.lcsIntersection -
set.lcsIntersectionResult -
set.lcsSymmetricDifference -
set.lcsSymmetricDifferenceResult -
set.symmetricDifference -
set.symmetricDifferenceResult -
set.union -
set.unionResult -
sortWords -
soundex -
substituteMany -
transliterate -
trashConsonants -
trashDiacritics -
trashVowels -
word -
wordCombinations -
wordCount
Permissions for exporting invalid records
| Invalid records export is supported only when Legacy pushdown is turned off. |
When exporting invalid records, Ataccama ONE automatically creates the export table in Snowflake if not present. To enable this, the Snowflake role configured in your connection credentials must have the following permissions:
-- Grant database and schema access
GRANT USAGE ON DATABASE <database>.<schema>.<table> TO ROLE <role>;
GRANT USAGE ON SCHEMA <database>.<schema> TO ROLE <role>;
-- Grant INSERT privilege on the table
GRANT INSERT, DELETE ON TABLE <database>.<schema>.<table> TO ROLE <role>;
-- (Optional) Grant SELECT privilege on the table
GRANT SELECT ON TABLE <database>.<schema>.<table> TO ROLE <role>;
-- Allow users to create tables in the schema
GRANT CREATE TABLE ON SCHEMA <database>.<schema> TO ROLE <role>;Where:
-
<database>is the Snowflake database where the invalid records table is stored. -
<schema>is the schema where the invalid records table exists or will be created. -
<table>is the name of the table used for storing invalid records. -
<role>is the Snowflake role configured in your connection credentials.
Limitations
-
Profiling is not optimized to run against complicated Snowflake views built with large tables that are not materialized. Data quality computation should not be affected as much by this.
-
Post-processing plans and load components are not supported.
-
Not all rules are supported. For full details, see Supported rules.
Limitations when Legacy pushdown is turned off
Because pushdown translates DQC expressions to Snowflake SQL and relies on native Snowflake support, the following limitations apply when Legacy pushdown is disabled:
-
Custom DQC functions and lambdas aren’t supported.
-
Regular expression and pattern support match the capabilities of Snowflake.
-
The function
eraseSpacesInNameswithminLengthof 4 or higher is reported as not supported in pushdown. The full signature isstring eraseSpacesInNames(string srcStr, integer minLength, boolean onlyUpper).
Geospatial functions
-
Geospatial functions work on values of the
GEOGRAPHYnative type or on text representations of the same meaning. For supported text formats, see Snowflake documentation. -
On values of
GEOMETRYtype, geospatial functions might run but return different results. -
The text-to-
GEOGRAPHYconversion relies on Snowflake support, which might produce runtime errors and incurs a performance penalty.
Troubleshooting
Processing fails with message Processing aborted due to error 300010:2765523699
- Problem
-
Snowflake pushdown processing fails with the following error
Processing aborted due to error 300010:2765523699; incident [incident_number]. - Cause
-
This issue has to do with internal Snowflake processing and typically occurs when the table contains a column of type
MAP(STRING, OBJECT). Some other complex object types might also result in the same error. - Possible solution
-
Such columns cannot be detected in advance as all
MAPandOBJECTtypes are reported as the generalOBJECTtype. As a workaround, the following options are available:-
Process the table in DPE instead of using pushdown processing.
-
Exclude all OBJECT types from pushdown processing.
To do this, set the JDBC driver property
ata.pushdown.ignore.object.typetotrueand remove any DQ rules from columns ofOBJECTtype. With this setting, only non-OBJECTtypes will be processed.The property is configured on the source connection. For details, see Add Driver Properties.
-
Was this page useful?