
Relational Database Connection
Follow this guide if you want to connect to Amazon Aurora MySQL, Amazon Aurora PostgreSQL, Amazon Redshift, CData Salesforce, Dremio, INFORMIX, MariaDB, Redis, Sqlite3, Sybase, Oracle, PostgreSQL, MS SQL (jTDS), or MySQL.
The following databases have their own connection pages:
For a full list of supported relational databases, see Supported Data Sources.
Create a source
To connect to a relational database:
-
Navigate to Data Catalog > Sources.
-
Select Create.
-
Provide the following:
-
Name: The source name.
-
Description: A description of the source.
-
Deployment (Optional): Choose the deployment type.
You can add new values if needed. See Lists of Values. -
Stewardship: The source owner and roles. For more information, see Stewardship.
-
| Alternatively, add a connection to an existing data source. See Connect to a Source. |
Add a connection
-
Select Add Connection.
-
In Select connection type, choose Relational Database > [your database type].
-
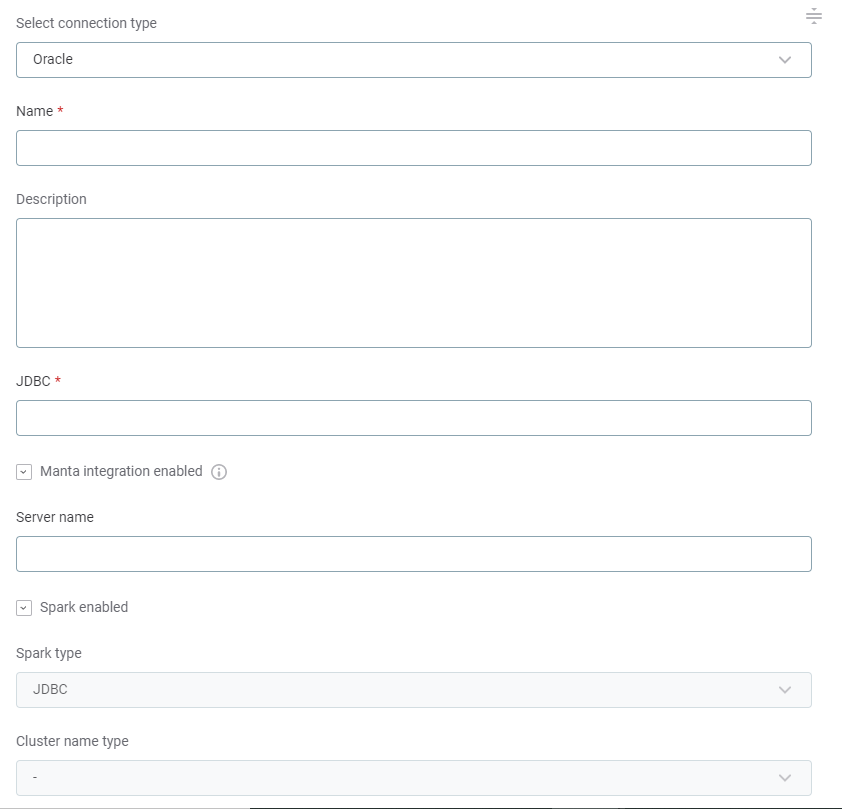
Provide the following:
-
Name: A meaningful name for your connection. This is used to indicate the location of catalog items.
-
Description (Optional): A short description of the connection.
-
Dpe label (Optional): Assign the processing of a data source to a particular data processing engine (DPE) by entering the DPE label assigned to the engine. For more information, see DPM and DPE Configuration in DPM Admin Console.
-
Override catalog item name: Select this option if you want metadata imports to overwrite the names of existing catalog items with the latest names from the data source.
If the option is not selected, catalog item names you set in ONE are preserved when metadata is reimported. See Edit catalog item metadata.
-
JDBC: A JDBC connection string pointing to the IP address or the URL where the data source can be reached. For a list of supported sources and JDBC drivers, see Supported Data Sources.
Depending on the data source and the authentication method used, additional properties might be required for successful connection. See Add Driver Properties.
-
-
In Additional settings:
-
Select Enable exporting and loading of data if you want to export data from this connection and use it in ONE Data or outside of ONE.
If you want to export data to this source, you also need to configure write credentials. See Connection credentials.
Consider the security and privacy risks of allowing the export of data to other locations. -
Select Enable analytical queries if you want to create data visualizations in Data Stories based on catalog items from this connection.
This feature is available only for Snowflake, ONE Data, PostgreSQL, and Amazon Aurora PostgreSQL sources.
-
-
Proceed to Add credentials.
Add credentials
Different sets of credentials can be used for different tasks. One set of credentials must be set as default for each connection.
To determine whether you need to configure more than a single set of credentials, see Connection credentials.
-
Select Add Credentials.
-
Choose an authentication method and proceed with the corresponding step:
-
Username and password: Basic authentication using your username and a password.
Select this method if you are connecting to an MS SQL data source using Kerberos authentication to Azure Active Directory (AD). For further instructions, see Connect to MS SQL Using Kerberos Authentication to Windows Active Directory. -
Integrated credentials: For some data sources, you can use, for example, Azure AD or Azure Key Vault.
Integrated credentials are not a fixed credential type but a way to use authentication options which are not natively supported. Generally, this involves the configuration of driver properties. See Add Driver Properties. -
OAuth credentials: Use OAuth 2.0 tokens to provide secure delegated access. Available only for some data sources.
-
OAuth user SSO credentials: Use an external identity provider Single Sign-On (SSO). Available only for some data sources.
-
Username and password
-
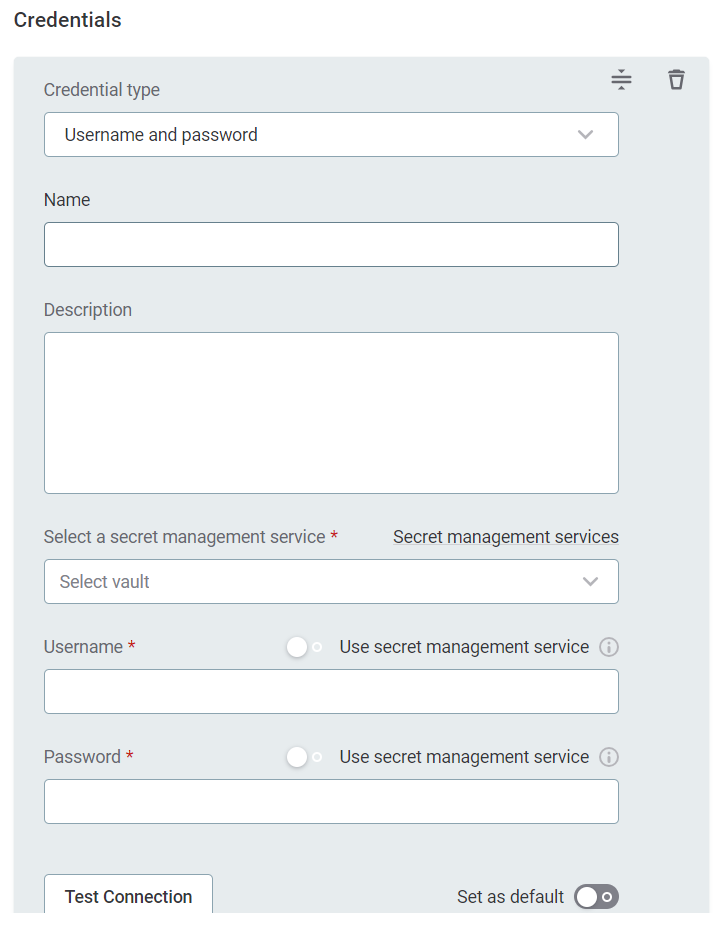
Provide the following:
-
Name (Optional): A name for this set of credentials.
-
Description (Optional): A description for this set of credentials.
-
Select a secret management service (optional): If you want to use a secret management service to provide values for the following fields, specify which secret management service should be used. After you select the service, you can enable the Use secret management service toggle and provide instead the names the values are stored under in your key vault. For more information, see Secret Management Service.
-
Username: The username for the data source. Alternatively, enable Use secret management service and provide the name this value is stored under in your selected secret management service.
-
Password: The password for the data source. Alternatively, enable Use secret management service and provide the name this value is stored under in your selected secret management service.
-
-
If you want to use this set of credentials by default when connecting to the data source, select Set as default.
See also Connection credentials.
-
Proceed with Test the connection.
Integrated credentials
| As a prerequisite, you need to set up additional driver properties. See Add Driver Properties. |
-
Provide the following:
-
Name (Optional): A name for this set of credentials.
-
Description (Optional): A description for this set of credentials.
-
-
If you want to use this set of credentials by default when connecting to the data source, select Set as default.
See also Connection credentials.
-
Proceed with Test the connection.
OAuth credentials
| If you are using OAuth 2.0 tokens, you also need to supply the Redirect URL to the data source you’re connecting to. This information is available when configuring the connection. |
-
Provide the following:
-
Name (Optional): A name for this set of credentials.
-
Description (Optional): A description for this set of credentials.
-
Select a secret management service (optional): If you want to use a secret management service to provide values for the following fields, specify which secret management service should be used. After you select the service, you can enable the Use secret management service toggle and provide instead the names the values are stored under in your key vault. For more information, see Secret Management Service.
-
Redirect URL: This field is predefined and read-only. This URL is required to receive the refresh token and must be provided to the data source you’re integrating with.
-
Client ID: The OAuth 2.0 client ID.
-
Client secret: The client secret used to authenticate to the authorization server. Alternatively, enable Use secret management service and provide the name this value is stored under in your selected secret management service.
-
Authorization endpoint: The OAuth 2.0 authorization endpoint of the data source. It is required only if you need to generate a new refresh token.
-
Token endpoint: The OAuth 2.0 token endpoint of the data source. Used to get access to a token or a refresh token.
-
Refresh token: The OAuth 2.0 refresh token. Allows the application to authenticate after the access token has expired without having to prompt the user for credentials.
Select Generate to create a new token. Once you do this, the expiration date of the refresh token is updated in Refresh token valid till.
-
-
If you want to use this set of credentials by default when connecting to the data source, select Set as default.
See also Connection credentials.
-
Proceed with Test the connection.
OAuth user SSO credentials
Authenticating through an external identity provider SSO involves users logging into ONE through an external OIDC identity provider (for example, Okta) and using their identity when accessing a data source.
| As a prerequisite, you need to set up the integration with the external identity provider. See Okta OIDC Integration with Impersonation. |
-
Provide the following:
-
Name (Optional): A name for this set of credentials.
-
Description (Optional): A description for this set of credentials.
-
-
If you want to use this set of credentials by default when connecting to the data source, select Set as default.
See also Connection credentials.
-
Proceed with Test the connection.
Test the connection
To test and verify whether the data source connection has been correctly configured, select Test Connection.
If the connection is successful, continue with the following step. Otherwise, verify that your configuration is correct and that the data source is running.
Save and publish
Once you have configured your connection, save and publish your changes. If you provided all the required information, the connection is now available for other users in the application.
In case your configuration is missing required fields, you can view a list of detected errors instead. Review your configuration and resolve the issues before continuing.
Next steps
You can now browse and profile assets from your connection.
In Data Catalog > Sources, find and open the source you just configured. Switch to the Connections tab and select Document. Alternatively, opt for Import or Discover documentation flow.
Or, to import or profile only some assets, select Browse on the Connections tab. Choose the assets you want to analyze and then the appropriate profiling option.
Was this page useful?