
BigQuery Pushdown Processing
Pushdown processing in BigQuery can be utilized both for profiling and for data quality evaluation.
Once pushdown is enabled for profiling, all catalog items under that connection are profiled using pushdown. For more information about pushdown profiling, see Pushdown profiling.
For DQ evaluation using pushdown, it is possible to exclude selected catalog items, in the case that any rules used in the catalog item are not supported in pushdown. You can disable pushdown for DQ evaluation at a catalog item level or for individual monitoring projects. For more information about DQ evaluation in pushdown, see Pushdown for DQ evaluation.
| Get in touch with your Customer Success Manager if you want to use this feature. |
Pushdown profiling
How to enable pushdown profiling on BigQuery connections
This section covers how to enable pushdown profiling. Pushdown profiling is enabled at the data source Connection level.
-
Enable pushdown processing on a BigQuery connection via the connection configuration details. Add a connection according to the instructions found in BigQuery Connection, or edit an existing connection.
-
In the Pushdown processing section, enable Profile data using pushdown processing.
-
You now need to choose whether you want to run term detection when pushdown processing is enabled, or disable term detection.
Term detection jobs (domain detection and fingerprints for AI term suggestions) can’t run in pushdown. If you run term detection with pushdown enabled, it runs on a data sample which is sent to ONE. -
Select Run term detection on a data sample in ONE to trigger detection jobs alongside profiling. Otherwise, select Disable term detection.
If you disable term detection, no terms are applied during profiling or documentation flows, and no term suggestions are shown for assets from this connection.
-
How does it work?
After enabling pushdown profiling for your BigQuery connection, profiling for all catalog items under that connection is processed in pushdown.
Standard profiling fetches all catalog item data to Ataccama Data Processing Engine (DPE), iterates rows, and executes the profiling locally. Pushdown profiling instead creates complex specialized database-specific SQL queries that are executed inside BigQuery, and only the profiling results are returned to Ataccama DPE.
Additionally, Ataccama utilizes the columnar storage provided by BigQuery and uses highly optimized queries. By default, when you start profiling, a single SQL query is generated per column that combines all the statistics Ataccama requires for that column.
The total number of queries for the table is determined by the number of columns in the table: it is possible to minimize the number of queries by merging queries for multiple columns into a single, bigger SQL query. See Pushdown profiling configuration.
| Pushdown profiling only applies to full profiling. Sample profiling always runs on Ataccama DPEs. |
Pushdown profiling configuration
The default pushdown configuration creates one SQL query for each table column and retrieves all supported statistics at once. It is possible to modify the number of DPE threads and the number of columns processed by a single query and to split standard and frequency analysis.
Pushdown profiling also retries transient query failures.
In self-managed deployments, pushdown profiling is configured in dpe/etc/application.properties.
For Ataccama Cloud deployments, configuration is handled by Ataccama: get in touch with your Ataccama Customer Success Manager if required.
For more information, see Query pushdown processing and Pushdown profiling retry configuration respectively.
Pushdown for DQ evaluation
After enabling DQ evaluation in pushdown for your BigQuery connection, processing of all supported rules on catalog items under that connection runs in pushdown. Only the DQ results and invalid samples, if configured, are returned to ONE.
To enable pushdown for DQ evaluation, see How to enable pushdown for DQ evaluation on BigQuery connections.
However, there are limitations to the type of rules which can be processed in pushdown.
For this reason, it is possible to turn off pushdown for DQ evaluation at both the catalog item level and the monitoring project level.
See Enable and disable pushdown on the catalog item level and Enable and disable pushdown on the monitoring project level, respectively.
How to enable pushdown for DQ evaluation on BigQuery connections
-
Enable pushdown processing on a BigQuery connection via the connection configuration details. Add a connection according to the instructions found in BigQuery Connection, or edit an existing connection.
-
In the Pushdown processing section, enable Profile data using pushdown processing and Evaluate Data Quality using pushdown processing.
It is not possible to enable pushdown for DQ evaluation without first enabling pushdown profiling. -
You now need to choose whether you want to run term detection when pushdown processing is enabled, or disable term detection.
Term detection jobs (domain detection and fingerprints for AI term suggestions) can’t run in pushdown. If you run term detection with pushdown enabled, it runs on a data sample which is sent to ONE. -
Select Run term detection on a data sample in ONE to trigger detection jobs alongside profiling. Otherwise, select Disable term detection.
If you disable term detection, no terms are applied during profiling or documentation flows, and no term suggestions are shown for assets from this connection.
-
-
Create a dataset in BigQuery for temporary storage of lookup data:
In order to use pushdown capabilities a dataset must be created in BigQuery for temporary storage of Ataccama data required for processing. This is used for caching lookup keys only. -
In BigQuery, select your project and using the three dots menu, select Create dataset.
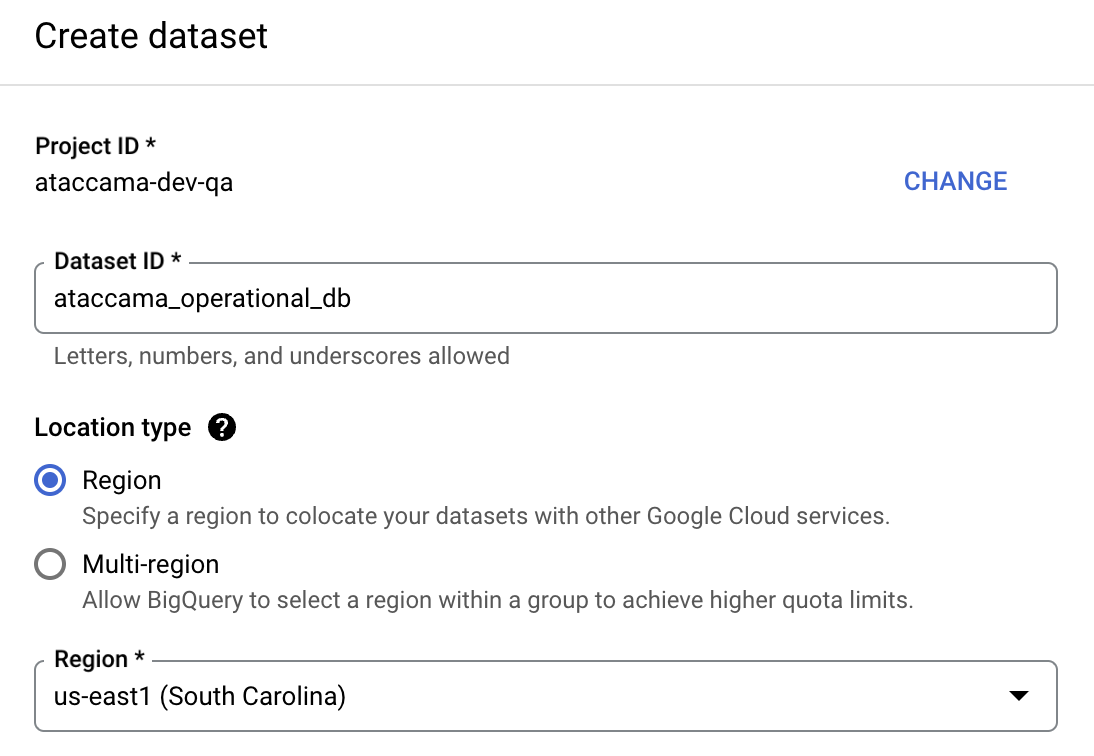
-
Provide the following:
-
Dataset ID: Provide a unique name for the dataset.
-
Location type: Choose between Region and Multi-region (for more information, see the official BigQuery documentation) and select your region using the dropdown.
The region specified for this dataset needs to match the region specified for the dataset of the source data. 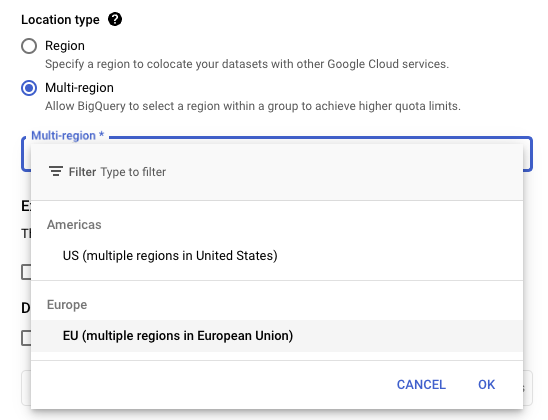
-
All following fields can be left as default. You only need to alter or provide details if you want a custom configuration.
-
-
Provide the following information:
-
Project name: The name of your project in BigQuery (also known as
Project ID). This value is prefilled using information from the JDBC string provided in the connection. Enter a different name to override this value. -
Dataset name: The name of the database created in BigQuery for temporary storage of lookup data.
-
Use operational credentials for uploading files: For added security, you can provide credentials specifically for updating the lookup information in the operational database defined in step 4. If this option is not selected, the credentials associated with the connection will be used to update the lookups within the operational database.
-
-
Permissions for exporting invalid records
When exporting invalid records, Ataccama ONE automatically creates the export table in BigQuery if not present. To enable this, the service account or user configured in your connection must have the following permissions, which are granted through IAM:
-- Create table on schema
GRANT `roles/bigquery.dataEditor` ON SCHEMA <project>.<dataset> TO '<principal>';
-- Insert and select on table
GRANT `roles/bigquery.dataEditor` ON TABLE <project>.<dataset>.<table> TO '<principal>';Where:
-
<project>is the name of your BigQuery project (Project ID). -
<dataset>is the dataset where the invalid records table will be created. -
<table>is the name of the table used for storing invalid records. -
<principal>is the service account or user configured in your BigQuery connection credentials.
How does it work?
Ataccama Data Quality Pushdown translates Ataccama Expressions into native SQL queries. For each individual catalog item, Ataccama Data Processing Engine (DPE) generates a single SQL query that incorporates all the rules applied to the item, converted to SQL.
If you use lookup data in the rules, Ataccama DPE uploads those lookups into operational databases and performs a JOIN operation between the lookup table and the processed catalog item in order to match the values. For small lookups (where the lookup key column is less than 100 kB after values have been normalized), the lookup data is embedded directly into the SQL instead of performing a JOIN operation, which optimizes the processing.
The complexity of the generated query might vary significantly based on the DQ rules assigned to the catalog item. If your monitoring project has invalid samples enabled, Ataccama DPE generates and runs another SQL query that returns a sample of invalid records to be stored in ONE.
Enable and disable pushdown on the catalog item level
The following information is relevant for catalog items and DQ evaluation in the Data Catalog.
Once pushdown for DQ evaluation has been enabled at the connection level, it is possible to turn this off on the catalog item level. This is useful if you have rules applied to the catalog item which are not supported in pushdown.
To turn off pushdown processing for DQ evaluation:
-
In Knowledge Catalog > Catalog Items, select your catalog item.
-
Select the three dots menu and then select Edit.
-
Clear Enable Data Quality evaluation using pushdown.
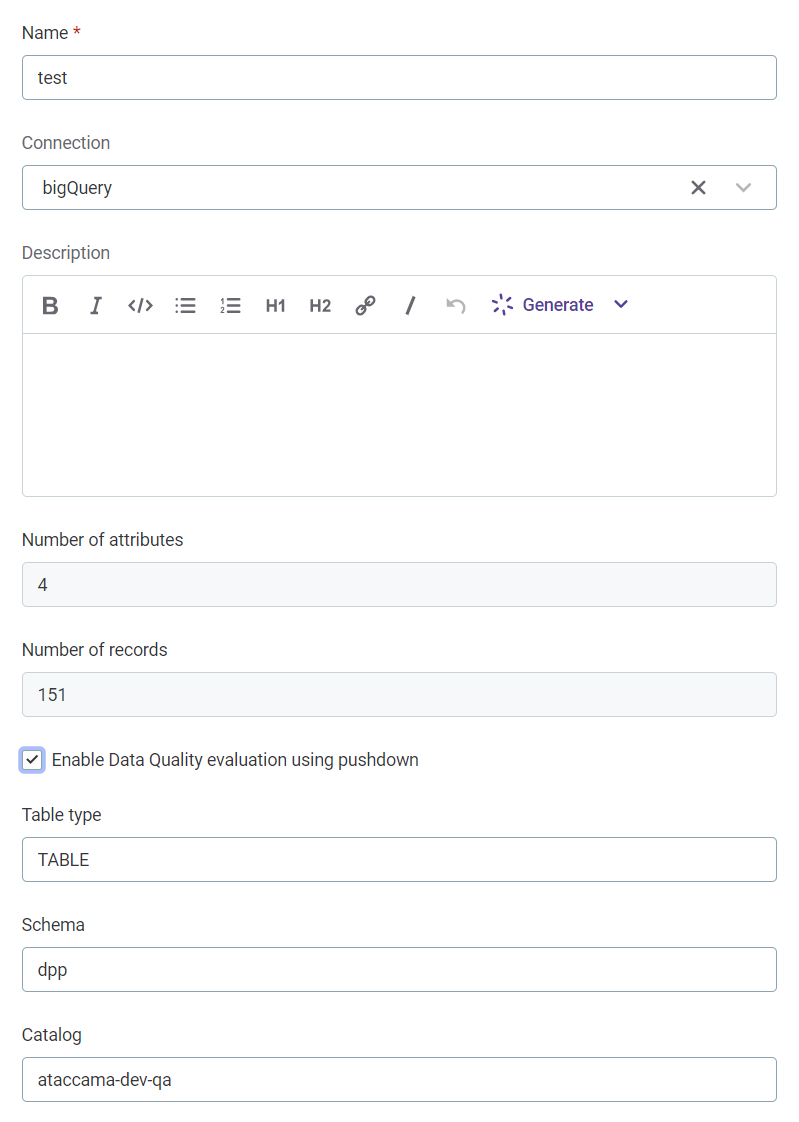
|
If rules not supported in pushdown are applied to items in the catalog, these rules are skipped during DQ evaluation. For more information, see Supported rules. 
|
Enable and disable pushdown on the monitoring project level
The following information is relevant for Monitoring Projects and the catalog items added to those projects.
Once pushdown for DQ evaluation has been enabled at the connection level, it is possible to turn this off on the monitoring project level. This is useful if you have rules which are not supported in pushdown applied to items in the monitoring projects.
To turn off pushdown processing for monitoring projects:
-
In Data Quality > Monitoring Projects, select your monitoring project.
-
Select the three dots menu and then Advanced settings.
-
In Pushdown processing, use the toggles to disable pushdown processing for any catalog items containing unsupported rules.
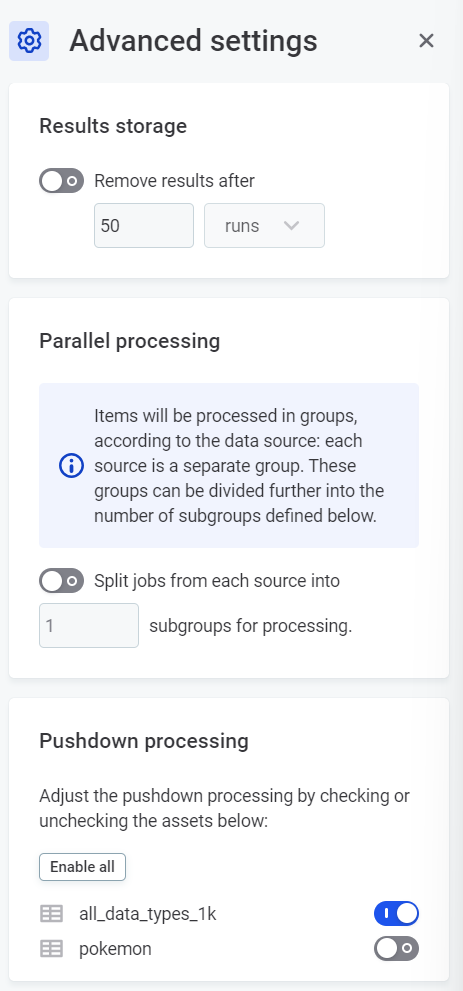
|
If rules not supported in pushdown are applied to items in the monitoring project, the monitoring project can’t be run until the rule has been removed or pushdown processing has been disabled for the affected catalog items. 
|
Supported rules
The following rules are supported in BigQuery pushdown:
-
All rules created using the Condition Builder, as all expression functions available in the condition builder are supported by pushdown. This includes aggregation rules built using the condition builder.
-
Parametric rules.
-
Advanced Expression rules, rules generated using the Ask AI feature, and rules using variables, as long as they include only Supported functions and operators.
Supported functions and operators
| The data quality processing configurations available in ONE are translated to BigQuery SQL language, either by utilizing native SQL functions or creating new functions. For this reason, there are some rule functions which are not supported. |
You are notified about rules not supported in pushdown either during rule creation or when trying to add rules to attributes.
Examples
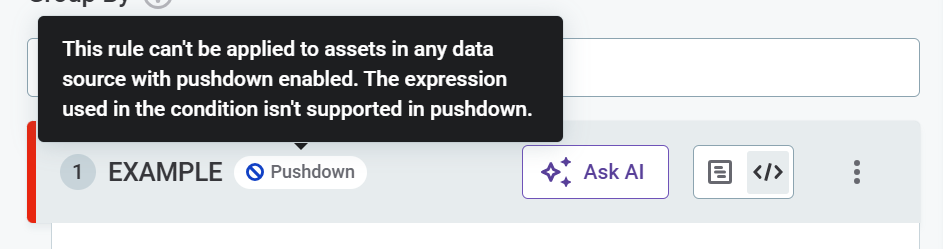
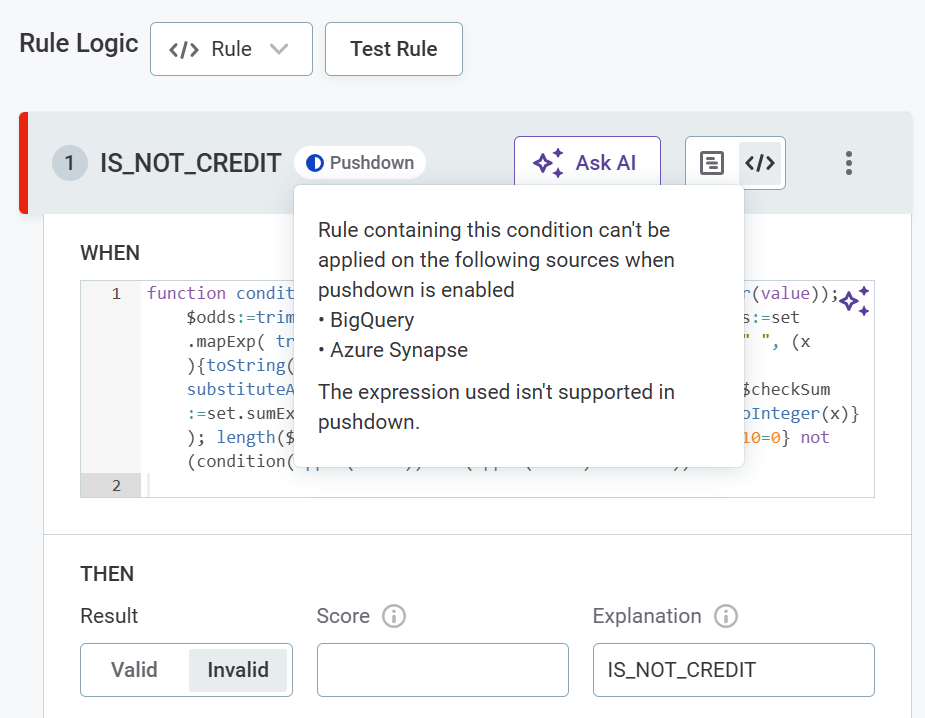
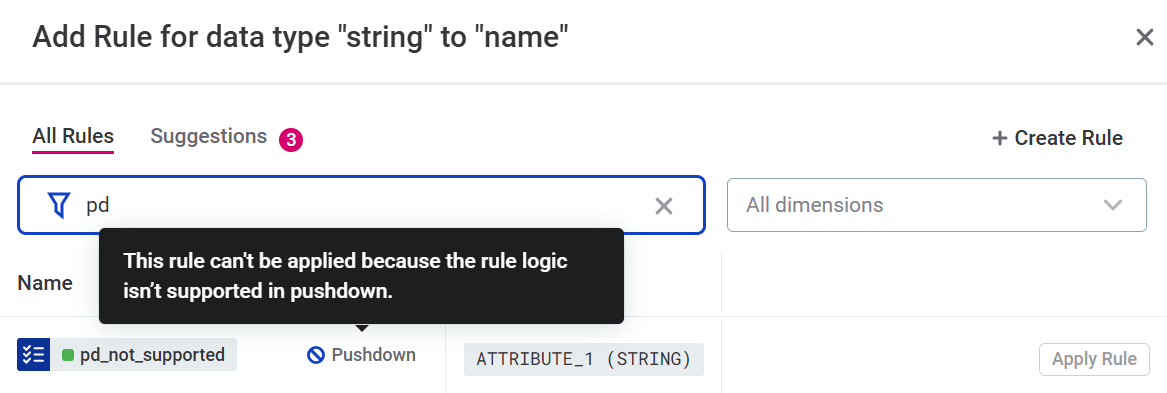
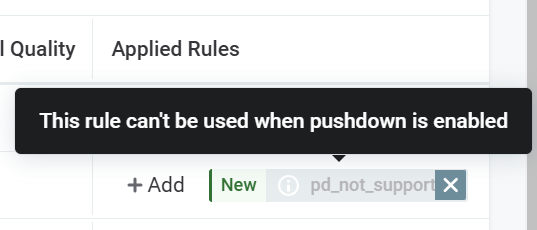
The full list of supported functions can be found here.
Expand to see list
-
+(concatenate for string, addition for numeric values) -
-(subtraction) -
*(multiplication) -
/(division) -
%(modulo) -
div(division of integer values without a remainder) -
< -
< = -
<>,!= -
=,== -
> -
> = -
AND -
OR -
avg -
avgif -
containsWord -
count -
countDistinct -
dateAdd -
dateDiff -
datePart -
dateTrunc -
eraseSpacesInNames -
getDate -
iif -
in -
indexOf -
is -
is in -
is not -
is not in -
is not null -
is null -
isInFile -
isNumber -
lastIndexOf -
left -
length -
like -
lower -
math.abs -
math.acos -
math.asin -
math.atan -
math.ceil, math.ceiling -
math.e -
math.exp -
math.floor -
math.log10 -
math.log -
math.longCiel,math.longCeiling -
math.longFloor -
math.pi -
math.pow -
math.round -
math.sin -
math.sqrt -
math.srq -
math.tan -
matches -
maximum -
maximumif -
minimum -
minimumif -
not in -
now -
removeAccents -
replace -
right -
squeezeSpaces -
substr -
substituteAll -
sum -
sumif -
toDate -
toDateTime -
toFloat -
toInteger -
toLong -
toString -
today -
trashNonDigits -
trashNonLetters -
trim -
trimLeft -
trimRight -
upper
Ataccama DPEs handle the translation of these configurations to BigQuery functions.
Limitations and known issues
-
Pushdown profiling:
-
Pushdown profiling is not supported for virtual catalog items (VCIs).
-
Frequency group analysis statistics cannot be returned when pushdown profiling is used.
-
-
Pushdown for DQ evaluation:
-
Pushdown for DQ evaluation is not supported for VCIs or post-processing components.
-
Some rule types and functions are not supported, these are:
-
Component rules
-
Rules containing unsupported expression functions. A full list of supported expressions can be seen in Supported functions and operators.
-
-
| If rules not supported in pushdown are applied to items in the data catalog, these rules are skipped during DQ evaluation. If rules not supported in pushdown are applied to items in a monitoring project, the monitoring project can’t be run until the rule has been removed or pushdown processing has been disabled for the affected catalog items. |
Was this page useful?