
Databricks Integration Overview
About Databricks integration
Databricks integration enables Ataccama ONE to connect to Databricks, offering multiple integration approaches to suit different use cases and requirements:
-
Spark processing integration leverages Spark pushdown capabilities to execute processing directly on Databricks clusters, making it the optimal choice for high-volume data scenarios with billions of records that require distributed computing power.
-
JDBC connection integration provides standard database connectivity with optional pushdown capabilities, making it suitable for moderate-scale data operations.
Both approaches allow you to browse and work with Databricks tables directly from ONE. The Spark integration additionally enables complex data processing workflows to execute on Databricks infrastructure with full cluster scaling benefits.
The choice between integration types depends on your data volume requirements, processing complexity, licensing considerations, and operational needs. Each approach uses a distinct architecture - Spark integration requires multiple connections and operational storage for distributed processing, while JDBC integration uses a direct connection model. See Spark processing capabilities and JDBC connection capabilities respectively.
Spark processing capabilities
Architecture
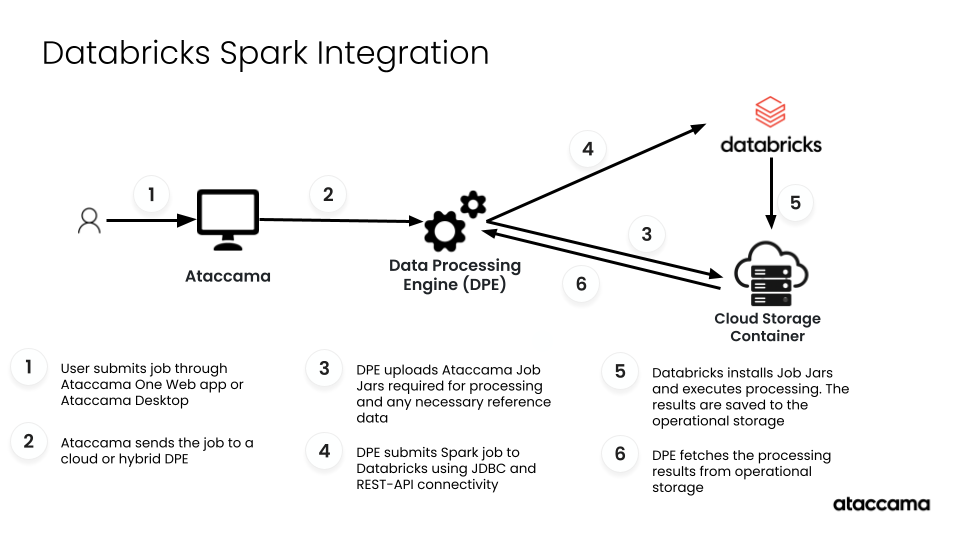
The Spark integration establishes multiple connections to enable distributed data processing:
Connection requirements
-
Data Processing Engine (DPE) to Databricks
-
Job Submission Connection (Databricks REST API): For submitting and monitoring Spark processing jobs.
-
JDBC connection: For browsing tables, importing metadata, and running processing jobs.
-
-
DPE to Operational Storage
-
Purpose: Stores Ataccama processing files (JARs, lookup tables, temporary data).
-
Options:
-
ADLS Gen2 Container for Azure Databricks.
-
AWS S3 Bucket for Databricks on AWS.
You can optionally configure Databricks volume storage, which is an alternative configuration approach that provides an abstraction layer over your existing ADLS or S3 storage, eliminating the need for direct storage mounting. Additional properties are required for volume storage, see Databricks volume storage for more information.
-
-
What you can do with Spark processing
-
Large-scale distributed data processing using Databricks Spark clusters.
-
Scalable data transformations and DQ rules processing.
Data transformation plans don’t support Databricks metastore connections, only Databricks JDBC. -
Complex data processing plans execution on Databricks infrastructure.
-
Processing scales automatically with cluster size.
Licensing requirements
A Spark processing license is required to enable distributed data processing using Ataccama’s Spark processing engine. This means that a Spark license is required for the following integrations:
| JDBC connection setup (Databricks JDBC) supports both platforms without requiring Spark licensing. |
JDBC connection capabilities
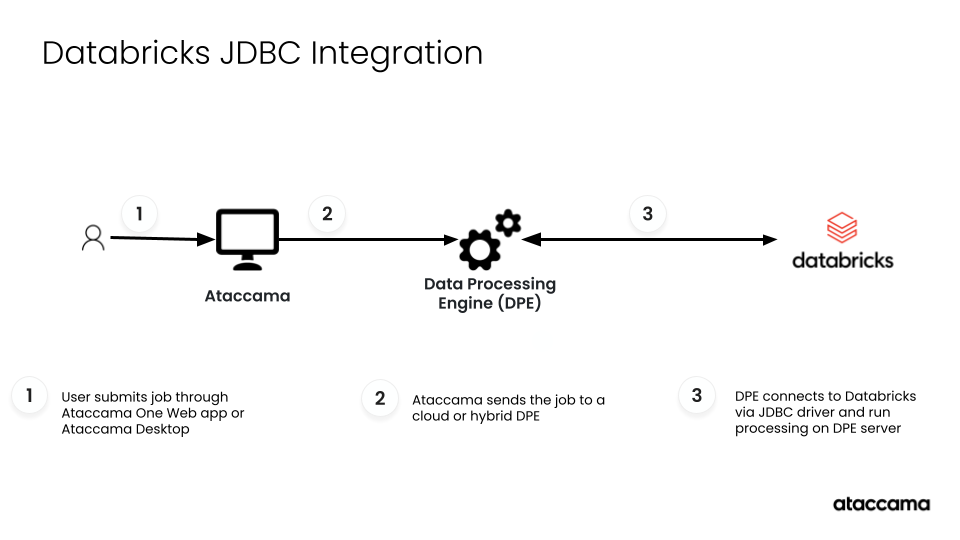
What you can do with JDBC connections
JDBC connections provide full database functionality equivalent to other standard database integrations, such as:
-
Browse and explore Databricks tables and metadata.
-
Import table schemas and metadata into ONE.
-
Run data processing jobs such as profiling and DQ evaluation.
-
Write data to Databricks tables (for example, when exporting invalid records via post-processing plans).
Processing can be configured to leverage Databricks cluster scaling capabilities; see Databricks SQL Pushdown Processing.
Licensing requirements
No Spark processing license required for JDBC-only operations.
| For cataloging and profiling use cases, the JDBC-only approach eliminates Spark licensing requirements. However, since processing is limited to DPE server capabilities without cluster scaling, consider Spark integration for large-volume scenarios that exceed DPE capacity. |
Unity Catalog support
Unity Catalog integration is available as an optional enhancement for both Azure and AWS deployments. It is accessible through both Spark processing and JDBC connections, with some specific limitations and requirements for each approach:
Unity Catalog with Spark integration
When using Spark integration with Unity Catalog enabled, Ataccama ONE supports only Dedicated access mode, not Standard access mode.
Unity Catalog with Databricks JDBC connection:
-
JDBC connections point to the legacy metastore by default, not the Unity Catalog. You can specify a maximum of 1 catalog using
ConnCatalog=<name>. -
When using an all-purpose cluster, it must be a single-user cluster owned by the service principal you’re authenticating as.
Was this page useful?