
Snowflake Pushdown Processing
There are two options regarding the processing of data quality in ONE.
-
The first option is for all data quality processing (DQ evaluation jobs and, during profiling, monitoring projects, and data observability) to be handled by Ataccama ONE Data Processing Engines (DPEs). Depending on the scale of the project, you might need multiple DPEs, and some transfer between your data source and DPE is required.
-
The second option is to use pushdown processing: this is supported for big data sources when Spark is enabled or using Snowflake.
This article outlines the benefits and limitations of using pushdown processing in ONE and provides instructions to enable it.
| This page is relevant for DQ processing configured and run from ONE, not ONE Desktop. Snowflake pushdown is not supported for plans. |
Why use pushdown processing?
Using pushdown profiling can lead to improvements in performance, security and infrastructure, and subsequently, scalability.
-
Performance. Evaluate millions of records in seconds.
-
Security. Data processing is executed directly in Snowflake, and results (and invalid samples, if configured) are returned. This means there is no transfer of data required or any external services or servers; all processes run on secured and governed Snowflake warehouses.
From the user perspective, the results are stored and appear the same as when DPE handles processing. -
Infrastructure. Utilize your existing infrastructure to evaluate data—no need to set up and manage new processing servers.
Processing in Spark
To work with pushdown profiling in Spark, there is no user action needed after the Spark cluster has been successfully connected (see step Add a connection in Relational Database Connection).
When this is enabled, processing is executed in Spark for all items in the connected source. There is nothing that would visually inform the user that processing is executed in Spark and not DPE.
Processing in Snowflake
Some limitations exist when working with pushdown processing in Snowflake, and some user actions are required.
| The data quality processing configurations available in ONE are translated to Snowflake SQL language, either by utilizing native SQL functions or creating new functions. This is done by DPE so at least one DPE is still required to handle the translation of these configurations to Snowflake functions. |
Where is it used?
Pushdown processing in Snowflake can be utilized for the following data quality functions:
-
Profiling
-
Data observability (excluding term detection and AI-powered anomaly detection)
-
DQ evaluation
-
Monitoring projects
A number of limitations apply (see Current limitations).
How does it compare to processing in ONE?
There is mostly no visual indication in ONE that processing is executed externally.
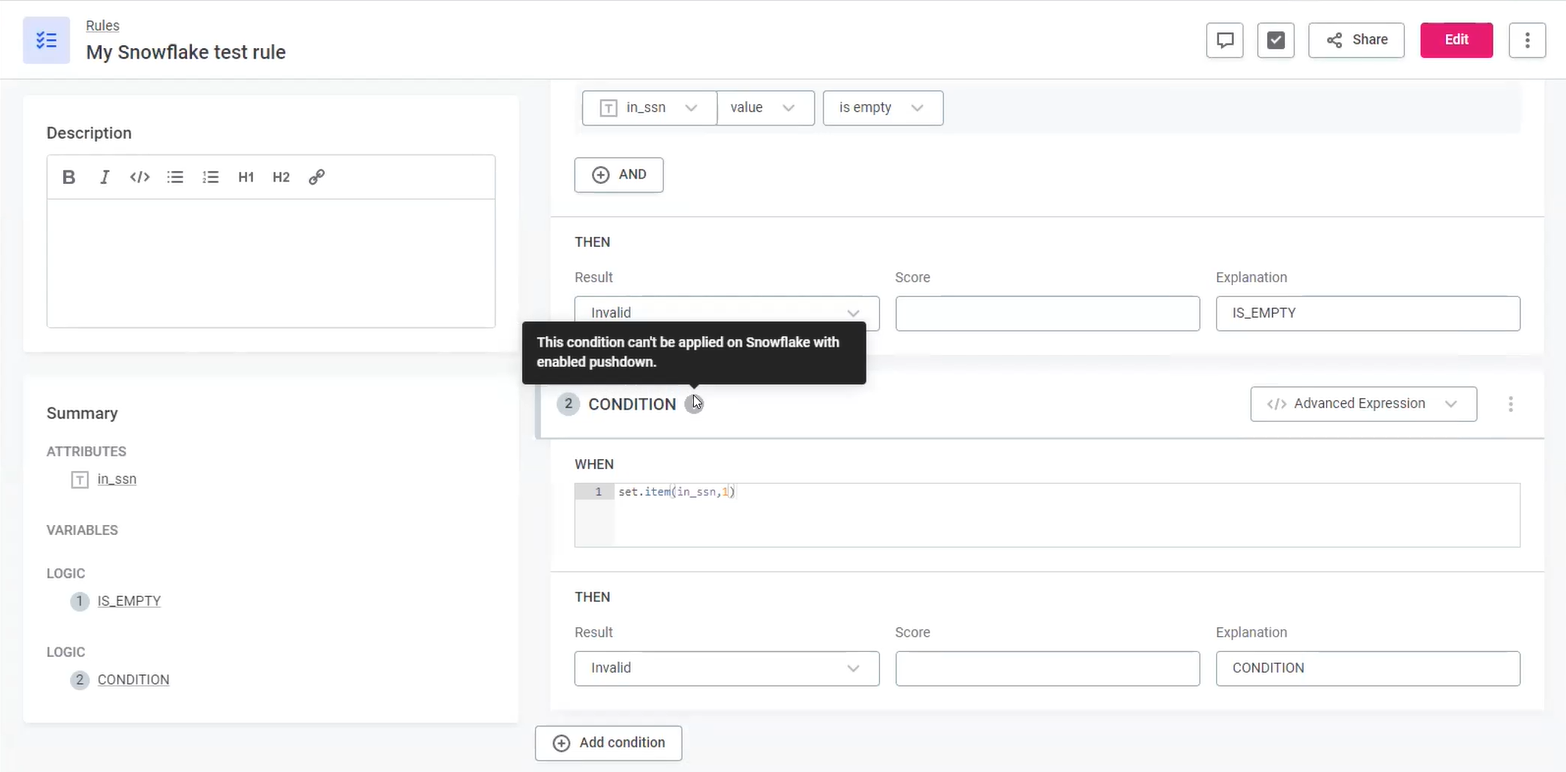
The exception is when you use a configuration that is not supported. In this instance you see the following warning: This condition can’t be applied on Snowflake with enabled pushdown.
If you want to use the Snowflake processing, you need to define an alternative configuration. For full details of functions which are not yet supported, see Current limitations.
Equally, in monitoring projects, if you try and apply an incompatible rule to a catalog item, you see a warning.
Prerequisites
There are two key parts when it comes to enabling pushdown processing. You must:
-
Configure Snowflake to allow Ataccama to transfer functions. Snowflake configuration is via worksheet which defines the working database and grants access to defined user roles. For instructions, see Relational Database Connection.
-
Enable pushdown profiling on the connection. Instructions can be found in Relational Database Connection. It is also necessary to make sure that DPE allows for automatic synchronization of user-defined functions. See fixme.adoc DPE Configuration.
Current limitations
Listed in this section are the known limitations when working with pushdown processing.
-
Post-processing plans are not supported.
-
Only simple rules are supported. Component and aggregation rules are not supported.
-
Even when working with simple rules, some rule expressions are not supported. You are notified about this in the web application if you use an expression which is not supported.
-
The size of Snowflake warehouse used determines the performance, so processing could be impacted if a small warehouse is used.
-
Load components are not supported.
-
Snowflake pushdown processing can’t be used for sample profiling. Sample profiling runs on Ataccama DPEs.
-
DQ filters in monitoring projects can’t be used when pushdown is enabled.
-
When profiling:
-
Quantiles are calculated only for numeric (integer, long, float), date and datetime attribute types.
-
Frequency groups are not calculated.
-
Was this page useful?