
Melissa Integration
Melissa is an external address standardization and verification service provider. The vendor provides online API (and batch) access to the system with a pay per request business model.
Integration with Melissa can be utilized for Data Verification and Data Enrichment. For a detailed description of the system interface, see the Melissa documentation.
MDM supports various options on how to utilize the standardized address values from Melissa. In this article we will describe two approaches, Asynchronous and Synchronous.
Asynchronous
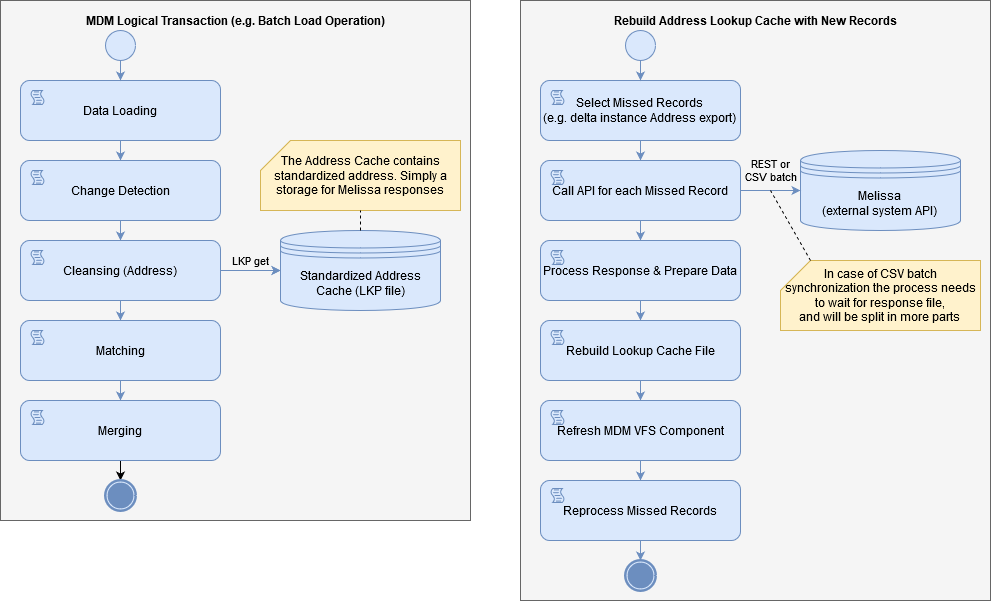
The first approach leverages the Ataccama proprietary binary lookup format. There are two lookups - one that stores all the original address attributes (in the form of a hash) and a reference to the Melissa record primary key (PK), and another that stores the Melissa PK and the cleansed, enriched values. The lookups can be used during data processing in MDM (online, batch, stream) or even to build custom address suggestions or a Data Quality Firewall.
The Address Lookup Cache needs to be asynchronously rebuilt in order to update the missed records (new addresses that were not found in the LKP Cache). The rebuilding process can either synchronously call the Melissa API (via REST API) or use a batch interface (potentially via CSV file) to get the missed records and update the LKP Cache.
| Rebuilding should ideally be carried out on a daily basis. |
To apply the cleansed values on the missed records a partial reprocess operation is needed.
The following is a sample schema showing the standard operations and the rebuilding process.
Advantages
-
The MDM system is decoupled from the Melissa system; loose dependency.
-
Address Lookup Cache can be further utilized to expose a custom service (for example, a client-specific database of “known” addresses).
-
Good performance (throughput) of the address cleansing solution.
-
The same address can be reused without the need to call Melissa (cost saving, data reusability).
-
The asynchronous nature of this pattern allows to shift the communication to Melissa to off-peak hours synchronization (for example, during the night).
Disadvantages
-
The MDM system needs to reprocess “missed” records.
-
Missed records represent temporary unverified data with a potentially low quality, and these records are available for consumption by downstream systems and used in their processes.
-
Higher design and orchestration complexity compared to alternative integration options.
Detailed integration design
The following is an example design based on Asynchronous approach. The solution uses several workflows, components, files and database tables that roughly map to the activity diagram of the proposed approach.
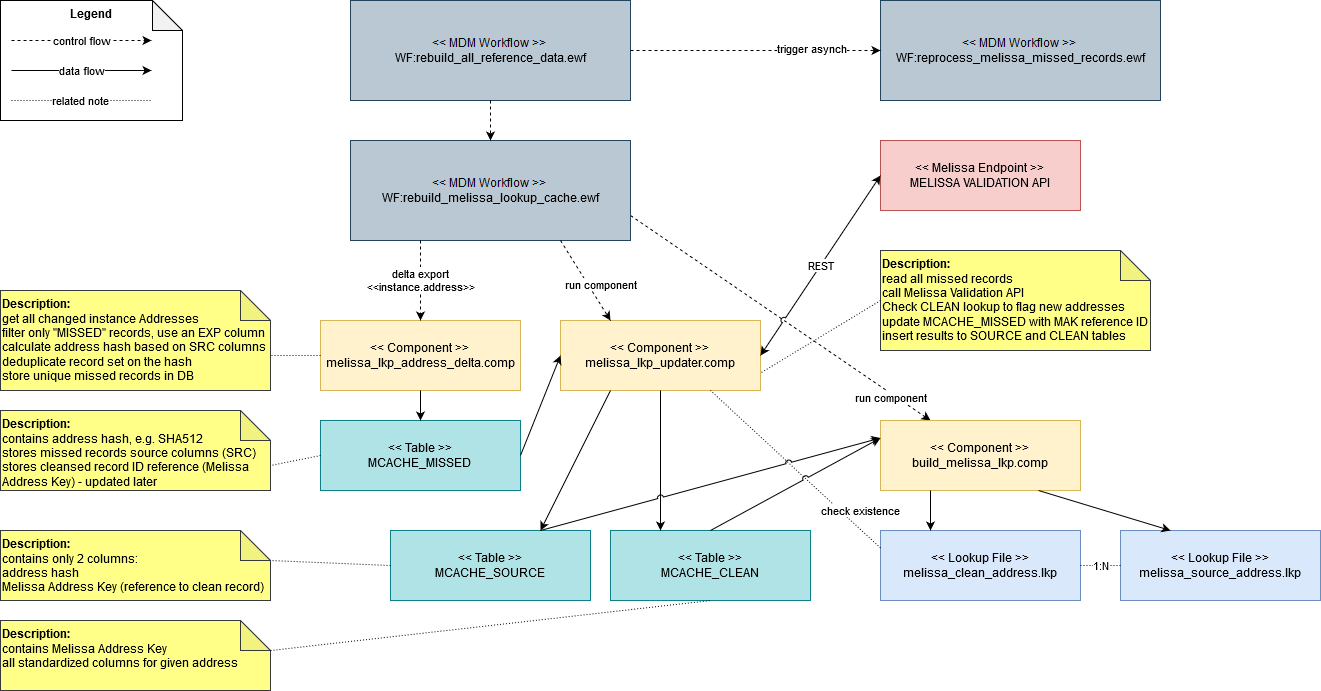
See the individual components and how they relate to the steps in the activity diagram.
Workflows
Rebuild all reference data
This is a wrapper workflow allowing flexibility for potential future orchestration of other MDM reference data.
The logic here initiates refreshing of a given logical group or set of lookups defined in the solution, for example, hub_reference_data.comp can be considered as one group of lookups (core validation and translation lookups in MDM) and the Melissa lookup cache as another.
The workflow directly initiates (synchronously) the Rebuild Melissa Lookup Cache.
Rebuild Melissa lookup cache
This is the main workflow responsible for orchestration of the background rebuild process of the Melissa Lookup Cache for the missed records. It allows only one running instance at the same time to avoid conflicts in data processing. The workflow always clears the table with missed records before it calls the delta export in order to have a clean (and smaller) data set.
At the end, it directly initiates the Reprocess Melissa Missed Records workflow (asynchronously).
This relates to step Reprocess Missed Records.
Components
Melissa lookup address delta
The component reads all changed instance Address records since the last export (using delta export) operation. It calculates an address hash column that represents an identifier for a given address including its state of completeness.
The hash algorithm, for example, SHA512, should ideally ignore some minor, non-relevant data characteristics like case-sensitivity, repeated spaces, accented letters, to avoid repeated calls for a semantically matching address.
coding.HMacSHA512("hash",
squeezeSpaces(
upper(
removeAccents(
src_address_line_1 + '☃' +
src_city + '☃' +
src_zip
)
)
)
)This relates to step Select Missed Records.
Melissa lookup updater
The component reads prepared missed records from the MCACHE_MISSED table and builds a JSON request using the SRC columns and the API mapping.
Then it calls the Melissa address validation API.
For identified addresses parses, the Melissa Address Key (MAK, see the Address Object Reference Guide) is used to check for new vs. existing records against the melissa_clean_address.lkp file.
The component finally updates the MCACHE_SOURCE records by their address hash and populates the MAK attribute for further processing.
Also, it populates the MCACHE_CLEAN table with records that are recognized as new additions to the cache.
This relates to step Call API for each Missed Record, Process Response & Prepare Data.
Build Melissa lookup
The component reads lookup source data from the MCACHE_SOURCE and MCACHE_CLEAN and fully rebuilds the target lookup files--melissa_clean_address.lkp and melissa_source_address.lkp.
The lookups need to be rebuilt in a different location (using Path Variable redirection) than the monitored folder under the Version File System. It is up to the Rebuild Melissa Lookup Cache workflow to properly move the complete lookups to the correct location and refresh the VFS.
This relates to step Rebuild Lookup Cache File.
Tables
The Melissa lookup cache uses the following tables as the data store for the lookup building process.
MCACHE_MISSED-
The structure of the table mostly corresponds to the instance Address entity in the MDM hub model - all the SRC columns should be there, additionally, it contains an address hash column, and a column for the Melissa Address Key identifier. The respective data types are subject to implementation detail with specific MDM model and Melissa Reference Documentation.
The table is periodically truncated at the beginning of each rebuild process to work with current data.
MCACHE_SOURCE-
The table holds the address hash column and a corresponding reference to the MAK column. The table is never truncated, and contains unique hash values.
Optionally, the table can include additional audit columns such as created date, or list of Melissa cleansing result codes.
MCACHE_CLEAN-
The table holds the validated, clean address as received from the Melissa API call. It contains all the cleansed data attributes, and the MAK identifier. The table is never truncated and contains unique records based on MAK identifier.
Files
The following Ataccama binary lookup files are produced for fast check against the cache.
- Melissa Clean Address Lookup (
melissa_clean_address.lkp) -
The lookup structure corresponds to the Melissa Address Object, excluding the cleansing result codes. It contains clean, validated addresses, and it’s stored in the MDM lookup folder (typically the folder path is
Files/data/ext/lkp).All references to the lookup file should be through path variables, either EXT or LKP.
- Melissa Source Address Lookup (
melissa_source_address.lkp) -
The lookup structure is very simple as it can only contain the two identifiers - the address hash and the MAK. It is also stored in the MDM lookup folder (typically the folder path is
Files/data/ext/lkp).All references to the lookup file should be through path variables, either EXT or LKP.
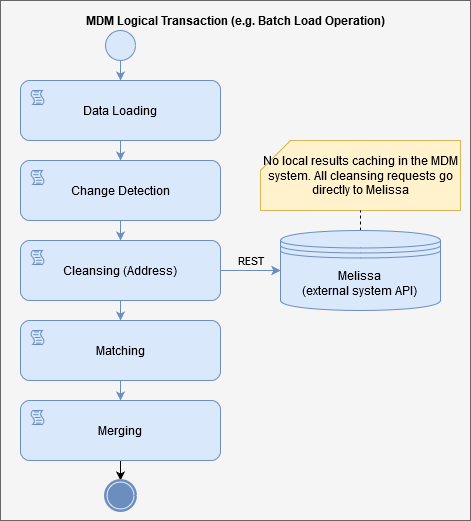
Synchronous
In this scenario we present an approach that uses direct API calls to the Melissa system without any local record caching. The MDM system calls Melissa’s API whenever a record is being cleansed. The response is immediately processed, and attributes are mapped to the record on the fly.
Was this page useful?