
AWS Glue Lineage Scanner
The Amazon Web Services (AWS) Glue lineage scanner is designed to retrieve AWS Glue metadata along with job details from the Spline API.
By leveraging the AWS SDK, it collects information about databases and tables in AWS Glue and combines this with detailed execution plans from the Spline API to deliver attribute-level lineage tracking. AWS Glue metadata scanning is optional but can enhance the mapping of Iceberg files to the Ataccama Data Catalog.
What is extracted from AWS Glue?
Lineage information is captured and aggregated from two primary sources:
- Metadata extracted from AWS
-
This ensures precise identification of paths and destinations within the AWS Cloud, ensuring improved mapping to the Ataccama Data Catalog. The metadata includes:
-
Databases: Metadata related to logical databases.
-
Tables: Information regarding tables associated with databases in AWS Glue.
-
- Metadata extracted from the Spline API
-
Each execution plan consists of multiple operations that provide a traceable lineage of source and target attributes, ensuring comprehensive lineage tracking. The metadata includes:
-
Execution Eeents: Detailed records of operational events during data workflows.
-
Operations: Information about transformations and processes applied to data.
-
Input and output attributes of operations: Attribute-level lineage tracking for data transformations.
-
Tables: Additional table-specific metadata.
-
Permissions and security
To access metadata from AWS Glue and interact with the Spline API, the necessary credentials must either be provided explicitly or configured via the AWS SDK for secure access.
If an entity is already authenticated in AWS, the awsKey and awsSecret properties can be omitted as they will automatically be sourced from the SDK configuration.
AWS Glue jobs configuration
As a prerequisite for running the scanner (namely, to be able to initiate AWS Glue ETL jobs scanning and lineage extraction), AWS Glue jobs need to be configured as described in the following sections.
-
Setup of Spline backend
-
Configuration of ETL jobs
Spline server setup
The Spline server must be hosted in an Amazon Elastic Compute Cloud (EC2) instance. This EC2 instance must have Docker and Docker Compose installed.
Once these prerequisites are in place, installing the Spline server consists of starting the ArrangoDB container and the Spline REST Server container.
The attached spline-poc-compose.yaml file contains a Docker Compose definition you can use to start both Spline services with the following command:
docker compose -f spline-poc-compose.yaml upAWS Glue and ETL jobs configuration
Once the Spline server is installed and running, you need to configure ETL jobs in AWG Glue so that the Spline agent is active during job execution and can send SQL lineage intermediary data to the Spline server.
| The configuration and setup described here were tested with Glue 4.0, which supports Spark 3.3, Scala 2, Python 3 ETL jobs. |
Connection between AWS Glue and EC2
The port 8080 of the EC2 instance must be accessible to AWS Glue ETL jobs.
How this is configured depends on the virtual port channel (vPC) topology within the AWS account used to perform lineage scanning.
When EC2 instances are hosted in a private VPC subnet, AWS Glue network connection must be configured to use the appropriate security groups settings.
This is because the Spline agent will be sending intermediary lineage information to the port 8080 for further processing.
Libraries for ETL jobs
Two JAR files must be uploaded to an S3 bucket and then added to the classpath of ETL jobs. These are:
- Spark 3 3 Spline Agent Bundle, version 2.1.0
-
Contains the Spark query execution listener that gathers information about SQL transforms which happen during job execution.
Download the JAR (6 MB) from the following link: Spark 3 3 Spline Agent Bundle » 2.1.0.
- SnakeYAML, version 2.2
-
A YAML parsing library the Spline agent uses to parse its configuration.
Download the JAR (326 kB) from the following link: SnakeYAML » 2.2.
Before you can reference these files in the ETL job configuration (Dependent JARs path), you need to upload them to an S3 bucket. Make sure the ETL job has access to the given S3 bucket.
ETL job configuration
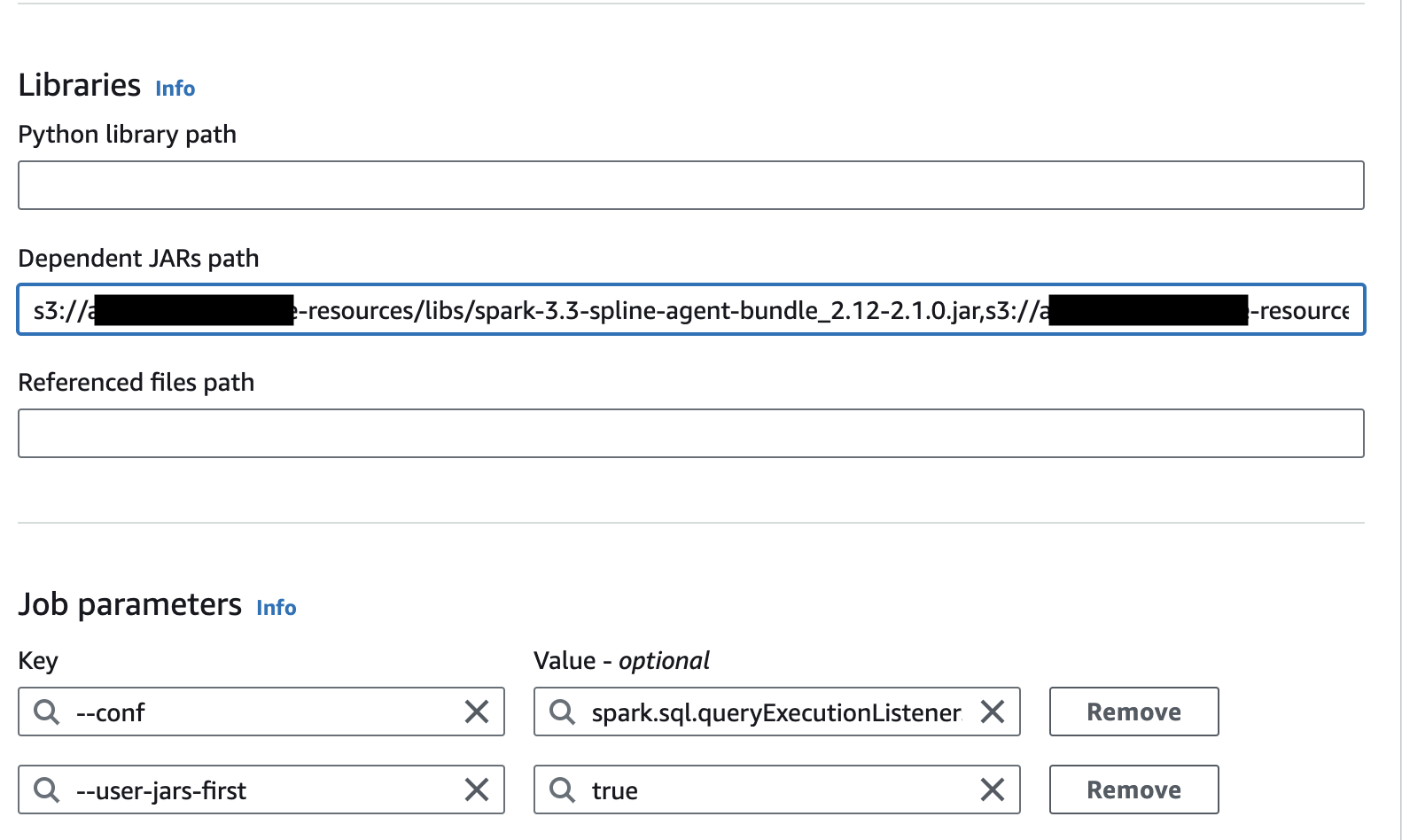
-
Dependent JARs path - URIs of both jar files uploaded to S3 have to be added
-
job parameter "--user-jars-first" with value
true -
job parameter "--conf" with value
spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener --conf spark.spline.lineageDispatcher.http.producer.url=http://<EC2 instance IP>:8080/producer -
Connections - attach connection enabling communication with EC2 instance created above (if needed)
Scanner configuration
All fields marked with an asterisk (*) are mandatory.
You can use the scanner without AWS credentials provided that your AWS environment is already authenticated via the SDK.
In that case, you can omit the awsKey and awsSecret properties.
The executionPlansSince and xecutionPlansUntil properties let you define a time window for scanning execution plans.
This gives you more control over which lineage data is retrieved.
| Property | Description |
|---|---|
|
Unique name for the scanner job. |
|
Specifies the source type to be scanned. |
|
A human-readable description of the scan. |
|
The REST API endpoint for data retrieval. |
|
List of execution plan IDs to be scanned. |
|
Date and time from which execution plans should be scanned.
Example: |
|
Date and time until which execution plans should be scanned.
Example: |
|
AWS SDK access key.
Example: Must be provided unless AWS authentication is already configured. |
|
AWS SDK secret key.
Example: |
|
AWS region for API interaction.
Example: Must be provided unless AWS authentication is already configured. |
{
"scannerConfigs":[
{
"name":"SplineScan",
"sourceType":"AWS_GLUE",
"description":"Scan SPLINE jobs",
"apiUrl":"http://xyz.eu-central-1.compute.amazonaws.com:8080/consumer/",
"executionPlansSince":"2024-08-01T00:00:00Z",
"executionPlansUntil":"2024-09-01T00:00:00Z",
"awsKey":"",
"awsSecret":"",
"awsRegion":"eu-central-1"
}
]
}Supported AWS Glue and Spline source technologies
The scanner supports processing the following file formats located in S3 within AWS:
-
CSV (comma-separated files)
-
JSON
-
Parquet
-
Iceberg
Limitations
- Complex workflows
-
Some data transformations or complex workflows might not be fully captured. This depends on how the operations are defined in AWS Glue or Spline.
- Edge cases
-
If you data involves unsupported file formats or unusual operations, the scanned lineage information might be incomplete.
Was this page useful?