
How the Matching Step Works
The Matching step is a key component of the matching plan which finds records that refer to the same real-world entity, such as party, product, mailing address. This article gives you an overview of how the Matching step behaves and explains the essential concepts behind it.
How the Matching step works
The Matching step processes incoming records through a series of steps to identify which records represent the same real-world entity.
The matching process flow goes through the following stages:
-
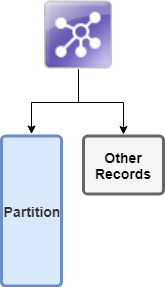
Partition assignment: Data is divided into partitions to prevent inappropriate matches (for example, separating person records from company records).
-
Key grouping: Within each partition, records are grouped based on shared characteristics.
-
Detailed matching: Within each key group, records are compared using matching rules to determine final groupings.
-
Master ID assignment: Records that belong to the same matching group receive the same master ID, indicating they represent the same real-world entity.
This staged approach improves both performance and accuracy by reducing unnecessary comparisons while ensuring precise matching decisions.
The following sections detail what happens in each stage of this process.
Partition assignment
Records are first divided to prevent inappropriate matches (like mixing person and company records). Each record is evaluated against partition conditions sequentially and assigned to the first partition it matches:
-
If a record matches the first partition’s conditions, it’s assigned there and evaluation stops.
-
If it doesn’t belong in the first partition, it’s checked against the second partition.
-
If it matches the second partition, it’s assigned there and evaluation stops.
-
This process continues until the record matches a partition or has been evaluated against all partitions.
Records that fall outside all defined partitions are excluded from matching entirely but they are still assigned a master ID.
Boolean conditions are evaluated from top to bottom and if no expression is given, TRUE is implied.
If you need a catch-all partition (matching without partitioning, where a partition should contain all records in the data flow), that partition should be last in the list of partitions.
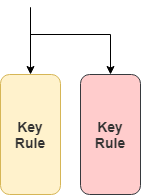
Key grouping
Records with shared characteristics are clustered into candidate groups for efficient comparison. Unlike partitions, records can belong to multiple groups simultaneously.
Key rules require exact matches, which means that records must have identical attribute values to be grouped together.
-
Records are evaluated against all key rules independently.
-
If a record satisfies multiple key rules, it joins multiple key groups.
Records that meet no key rule criteria within their partition are excluded from matching but they are still assigned a group ID.
|
For performance optimization with exact equality matches (such as technical key matching), you can configure partitions and key rules without any matching rules. In this setup, records that match a key rule are automatically assigned the same master ID without additional comparison logic, eliminating unnecessary processing overhead. |
Detailed matching
Records in each key rule group are compared using optimized, each-to-each record comparisons based on matching rules. You can apply exact or approximative rules (matching functions).
Pairs that satisfy no matching rules remain ungrouped.
After all matching rules have been evaluated, any remaining unmatched records are processed by proposal rules.
How matching results are computed
After all comparisons are complete, the Matching step creates final matching groups and assigns master IDs. This happens automatically and requires no configuration.
|
By default, all processing happens sequentially. For better performance with large datasets, see Matching step performance tuning. Parallelism is controlled by parallelism settings on multiple levels (partition, key rule, matching rule). |
Matching processes all discovered relationships through three stages:
-
Graph creation - All connections between records (from matching rules, proposal rules, and constraint rules) are mapped into a comprehensive relationship graph.
If multiple key rules are configured, their individual graphs are combined into a single union graph. Each link in the graph captures the relationship type (matching vs proposal rule), rule name, and quality score.
-
Group creation - These relationships are then used to form actual matching groups, specifically:
-
Links based on matching rules: Used to create master groups automatically with assigned master IDs.
-
Links based on proposal rules: Generate matching proposals for manual review, which are then sent to the Matching step Proposals output.
-
Constraint rule violations: Used to prevent inappropriate record connections within groups.
If a record or group already has a master ID, it’s preserved; otherwise a new ID is assigned.
-
-
Quality-based prioritization - When multiple grouping options exist, the best option is selected based on (in the order given):
-
Rule quality: Average of all test scores for the matching rule (normalized to 0-1 scale).
-
Rule order: Position of matching, proposal, and key rules in the configuration.
-
Record ID: Ensures consistent results (deterministic selection) when other factors are equal.
-
| Confidence scores from proposal rules don’t affect automatic grouping decisions, they only help prioritize manual reviews. |
Quality scoring
Each test within a matching rule produces either a 0 (no match) or 1 (match) score. For fair comparison across different test types (Boolean tests, match functions), all scores are normalized to a 0-1 scale.
For approximative, distance-based tests (like edit distance), we recommend setting a limit parameter even though it’s optional, as this ensures proper normalization to the same scale.
Matching step example
Let’s walk through how the Matching step works using a concrete example.
Setting up the partitions
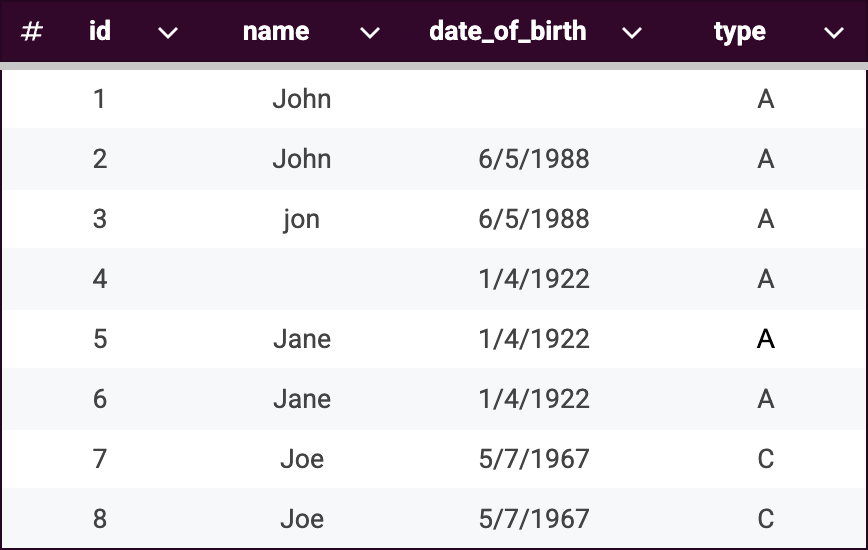
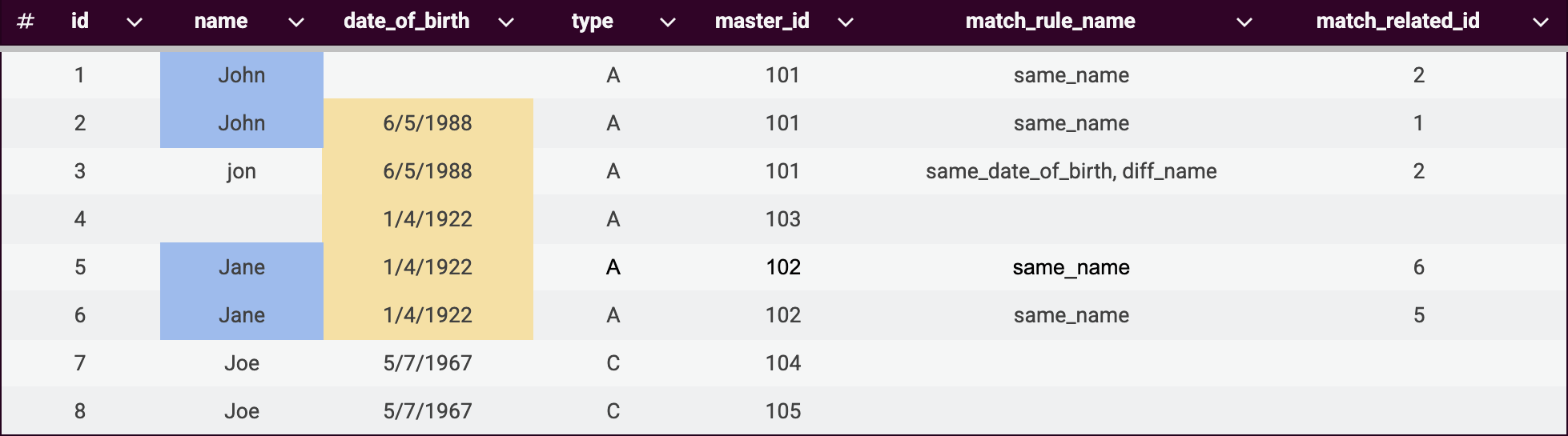
We start with one partition based on the column 'type' where 'type' equals A. In our sample dataset:
-
Records 1-6 qualify for this partition and will be processed further.
-
Records 7-8 are excluded because they belong to the partition C (column 'type'), not partition A.
Organizing by key rules
Within this partition, we define two key rules to group records efficiently:
-
Key rule 1:
same_name(highlighted in blue) -
Key rule 2:
same_date_of_birth(highlighted in yellow)
Once these key rules are applied, records are distributed into the following groups to optimize matching rules performance.
Note that records can belong to multiple key rule groups. This overlap is intentional and helps ensure comprehensive matching.
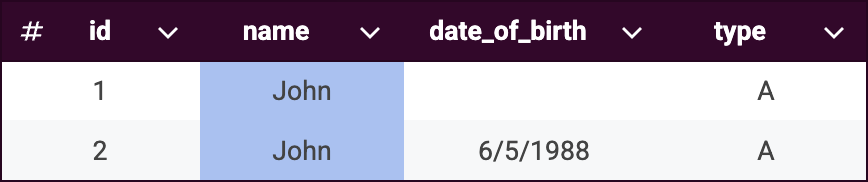
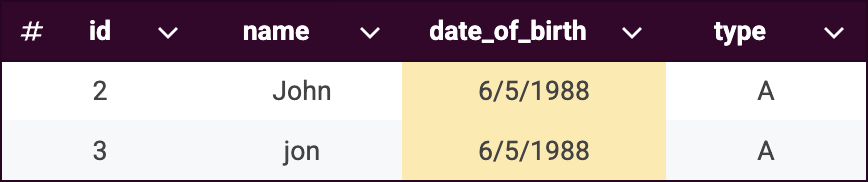
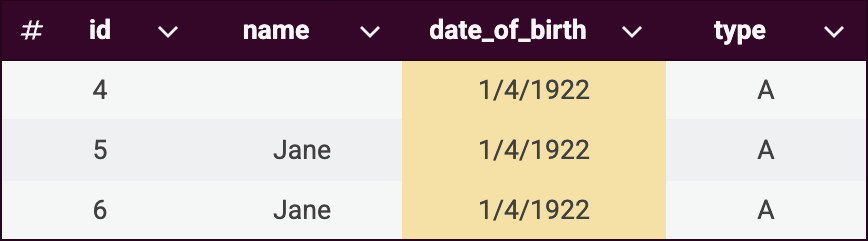
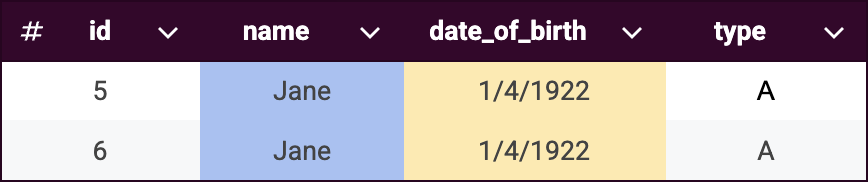
Applying matching rules
Next, we add specific matching rules to each key rule:
-
Key rule 1:
-
Matching rule 1:
same_name
-
-
Key rule 2:
-
Matching rule 2:
same_date_of_birthANDdiff_name -
diff_nameuses Levenshtein distance ≤ 1 (strings can be transformed into each other with a single character edit: insertion, deletion, or substitution)
-
Results
The matching process produces three new columns:
-
master_id: Unique identifier for each matching group. -
match_rule_name: The specific rule that connected this record to its group. -
match_related_id: The ID of the other record this record was directly matched to.
What happened:
-
Record 2 matched to record 1 using the
same_namerule within key rule 1 group. -
Record 3 matched to record 2 using
same_date_of_birthanddiff_namerules within key rule 2 group (demonstrating transitivity). -
Since record 2 belongs to both key rule groups, the matching process connected records 1, 2, and 3 into the same group (
master_id = 1). -
Record 4 received its own
master_idsince it didn’t match records 5 and 6 due to insufficient matching data. -
Records 7-8 were assigned
master_idvalues even though they were excluded from partition matching.
Key concepts and terms
The matching process involves several important concepts. The following glossary defines these terms in detail.
Partitions
A partition is a user-defined division that splits input records into separate groups to prevent certain types of records from being matched together. For example, partitions are commonly used to separate person records from company records in a 'party' entity.
Records can only be matched to other records within the same partition: records from different partitions are never compared.
Key rules
Key rules define which attributes are used to create initial groups of potentially matching records within each partition. These groups (called key groups) help optimize performance by clustering records that share common attribute values before detailed matching evaluation.
Records are grouped together when their key rule attributes have exactly matching values, creating candidate groups for further evaluation. Unlike matching rules, key rules require exact matches—there is no way to group records based on similarity (approximative or relative matching).
In other words, the goal is to create many small clusters where records have a reasonable likelihood of representing the same entity. For example, a key rule might group all records with the same full phone number, exact email address, or complete date of birth.
Matching rules
Matching rules perform the detailed record-to-record comparison within key groups to determine which records should receive the same master ID.
While key rules create candidate groups for evaluation, matching rules make the final decisions about which records actually represent the same entity. Multiple matching rules can be applied to the same key group, and records are assigned to the same matching group if they are connected through any combination of these rules.
For example, within a key group containing records A, B, and C:
-
Matching rule 1 determines that records A and B should be grouped together.
-
Matching rule 2 determines that records A and C should be grouped together.
-
Due to transitivity, all three records (A, B, and C) are assigned to the same matching group with the same master ID.
| Key takeaway: Matching rules create the final master ID assignments, while key rules only create candidate groups for evaluation. |
Tests and match functions
Tests are measurable checks that determine whether two specific records should be considered a match.
They work in conjunction with matching rules. For two records to be grouped together, they must be connected by a matching rule AND pass all the tests defined within that rule.
There are two types of tests:
-
Predefined tests: Built-in algorithms such as
equality,editDistance, andjaroWinkler. -
Custom tests: Created using match functions that you define in the Match Functions section of the Matching step.
|
How match functions work
Match functions allow you to create custom comparison logic using Match functions must be symmetric, meaning they should produce the same result regardless of which record is assigned to For example, a custom match function called Or, if you want to check whether the first character in two strings is the same, you could use the following logic: |
Matching measures and match functions
While matching measures are still available in the application to support migration from legacy configurations, they should not be used in new implementations.
Both approaches produce the same results, but tests and match functions offer better performance when evaluating matching rules.
| For matching measures, see also Pivot and candidate. |
ID keeper record
| Available if Keeper Selection Rule naming is used in the Matching step. |
The ID keeper record is the specific record within a matching group that carries the group’s master ID and ensures ID stability when the entire group is rematched.
The ID keeper is a temporary designation made during processing: it is not saved in the MDM database. Keeper selection rules only apply when the full master ID group is being rematched.
If only some records from a group are rematched while others remain unchanged, any non-rematched record automatically becomes the keeper, regardless of your Matching step configuration.
When PRESERVE_MANUAL rematch strategy is used, records with manual overrides are treated as non-rematched for keeper selection purposes.
As new records are added to the system or existing records are updated, matching groups can change composition. To maintain consistent master IDs for downstream systems, MDM designates one record in each group as the ID keeper.
ID keeper selection is critical in these scenarios:
-
Group merging: When two separate matching groups are merged into one, keeper selection rules determine which group’s master ID survives and which gets discarded
-
Group splitting: When a matching group gets divided (disbanded), the subgroup containing the original ID keeper record retains the original master ID, while other subgroups receive new master IDs
ID keeper selection can be configured either globally for the entire Matching step or individually within each key rule configuration, allowing for different selection criteria based on your data characteristics.
Constraint rules
Constraint rules act as additional filters that can prevent records from being grouped together, even when key rules and matching rules would otherwise group them. They ensure that all records within a matching group share the same value for specified constraint attributes.
When a constraint rule is applied to an attribute, all records in the same matching group must have either:
-
The same non-null value for that attribute, OR
-
Null values for that attribute.
Records with different non-null values for a constraint attribute are separated into different matching groups (regardless of what key rules and matching rules determine).
Records with null constraint rule values can be matched to any other record (whether that other record has a null or non-null constraint value) as long as the key rules and matching rules are satisfied.
|
Impact on existing groups
Constraint rules can force the splitting of existing matching groups when new records are added or when constraint rule values change. When this happens, matching proposals are automatically created for data stewards to review the group split, since some records from the original group might need to be reassigned to maintain constraint compliance. |
Proposal rules
Proposal rules identify potential matches that require manual review rather than automatic grouping. Unlike matching rules that automatically assign records to the same master ID, proposal rules flag uncertain matches for data steward evaluation.
When records meet the criteria defined in proposal rules, the application creates matching proposals instead of automatically grouping the records. Data stewards can review these proposals from the Matching proposals screen in the MDM Web App and decide whether to accept or reject the match (and in turn group or keep records separate, respectively).
|
Even when proposal rules are triggered, the application still assigns master IDs and creates golden records through the usual merging process. Generating proposals doesn’t interfere with the standard data processing pipeline. Implementations that need to postpone creating golden records until after proposals are manually resolved are technically possible but require specialized setup beyond standard configuration. |
|
Confidence scoring
Proposal rules are the only place in the matching process where confidence information (defined in proposal rules) is utilized.
This score helps data stewards prioritize which proposals to review first and make informed decisions about uncertain matches.
|
Isolate flag
The isolate flag is a Boolean column that provides a manual override to prevent specific records from participating in any matching process.
When set to true, the record will not match with any other records, regardless of how well it meets key rules, matching rules, or any other matching criteria.
For details, see Configure Advanced Matching.
It is particularly well suited for:
-
Records with known data quality issues that would create false matches.
-
Records requiring manual review before they can be safely matched.
-
Special cases where business rules dictate a record should remain standalone.
Pivot and candidate
Pivot and candidate are the technical names assigned to records during the matching evaluation process when two records are being compared against each other.
They are used only when writing expressions in matching rules or when defining matching measures, where you can reference specific attributes from each record using dot notation:
-
pivot.attribute_name- Accesses an attribute from the pivot record. -
candidate.attribute_name- Accesses the same attribute from the candidate record.
When this approach is used in detailed matching:
-
The first record in the key rule group becomes the pivot record.
-
Each subsequent record becomes a candidate record for comparison.
-
The pivot and candidate are evaluated against matching rules sequentially.
| Matching tests and related functions don’t use the pivot and candidate convention. |
Standalone bindings
Standalone bindings are configuration settings required when the Matching step is used outside of the standard matching plans.
That is, they’re mandatory when the step is run in a plan file that is not part of an entity_match.comp component.
These bindings ensure that the Matching step has access to all necessary data connections and configuration parameters when it’s not inheriting them from the broader MDM Engine context. Typically, they are needed when testing matching logic in a ONE plan or for match rule sandboxing.
For details, see Configure standalone bindings.
Was this page useful?