
Batch Interface
MDM supports several input and output interfaces.
The configured operations are generated into the Files/etc/nme-batch.gen.xml configuration file.
For the input interface, you can define the following modes:
-
Direct load
-
Initial load
-
Full load
-
Incremental load
Similarly, for the output interface, you can define the following modes:
-
Full export
-
Incremental export
Input interfaces
Input interfaces consist of two elements: the data provider (usually a plan file whose Integration Output steps are used as an interface to the entities, see Data providers) and the actual load operation. There are also some special operations designed to reprocess data already stored in the MDM database without having input data (see Special interfaces)
Concepts and settings
Delta detection process
When loading data, MDM always performs a Delta detection process to compare all incoming data (columns) with the data (columns) already stored in the database, and then it processes only those which differ. You can omit some columns from the comparison using the Ignore column functionality when defining the load operation.
By default, all attributes with SOURCE origin are used for delta detection.
Some of them can be removed from the comparison process using the following construct (applies to all load operations).
See the ignoredComparisonColumns element.
<op name="full_load_s1" class="com.ataccama.nme.engine.batch.FullLoadBatchOperation">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../batch/load.plan" />
<sourceSystem>s1</sourceSystem>
<importAllEntities>true</importAllEntities>
<ignoredComparisonColumns>
<column names="src_system_change_date" entities="*" />
<column names="src_aud_*" entities="Address,Contact" />
</ignoredComparisonColumns>
</op>The <code>names</code> and <code>entities</code> attributes are comma-separated lists of names and name patterns (with * wildcard for matching any number of characters).
Deletion strategy
There are two strategies available for a load operation to handle deletion: deactivate (default) and delete.
Each strategy has the following effect on the columns eng_active and eng_existing:
-
deactivate:
eng_active=falsewhileeng_existing=true. -
delete:
eng_active=falseandeng_existing=false.
Deactivated records will still be part of processing and matching, and will be visible on the front-end (MDM Web App), but marked as deactivated. Deactivated records are available in export interface (see Export scope setting).
Deleted records are no longer available to any MDM hub processes, and will not be visible in MDM Web App. To remove a deleted record from the repository, either run the Process Purge Service immediately (for more information, see Read-Write Services > Process Purge Service), or remove it by using the housekeeping request (for more information, see REST API > Purge).
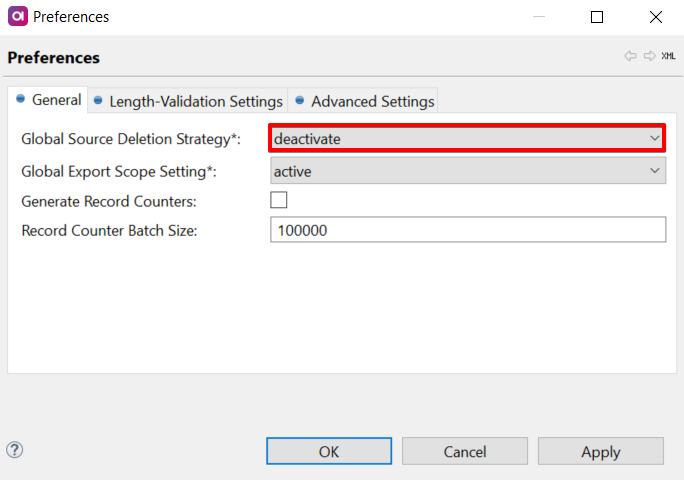
The strategy is configured by the sourceDeletionStrategy attribute:
<op name="direct_load" class="com.ataccama.nme.engine.batch.DirectLoadBatchOperation" sourceDeletionStrategy="deactivate">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../batch/load.plan" />
</op>Data providers
PlanBatchDataSource provider executes a ONE plan and maps its Integration Output steps to entity names.
For example, Integration Output step named party receives records and provides them to further processing as records of entity party.
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../batch/load.plan" />Direct load operation
The simplest batch load operation. This operation reads the data from the source and upserts all the records it finds. It can be used across multiple systems and is especially useful for performing initial loads.
The direct load operation is capable of loading already "deleted" data, which it stores with eng_active = false .
These "deleted" instances must have change_type = D when being loaded.
However, this operation does Change Detection.
<op name="direct_load" class="com.ataccama.nme.engine.batch.DirectLoadBatchOperation">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../batch/load.plan" />
</op>Initial load operation
Performs an initial load of all entities from a defined system. The only prerequisite is that there must be no records of that system in MDM storage. If records from other systems appear in the input, the plan fails.
This operation should be used in the following scenarios:
-
Initial load to an empty solution; use MultiLoad of InitialLoads of all source systems.
-
After adding new source system to the solution to load its records.
-
Migration; use full instance export to load all data from all source systems, omit
sourceSystemattribute (a record from any system can be loaded but storage must be empty and cannot be run in MultiLoad).
<op class="com.ataccama.nme.engine.batch.InitialLoadBatchOperation" name="life_initial" sourceSystem="life">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../engine/load/life_initial.comp"/>
</op>Only records of a configured source system can be loaded into the hub using this load operation and thus more of such initial load operations can be executed in a single MultiLoad (and reuse load plans for FullLoad).
This operation has the following features:
-
Performance optimization.
-
Skips Change Detection (always).
-
If there are no records in the MDM storage, optimized MDM processing (no records are read from the persistence) is used.
-
-
Loads inactive records (input records with
change_type = D), stores them witheng_active = false. -
Possibility to load history collectors.
-
Possibility to load record metadata.
When using the initial load to populate an empty database, be sure to use the default nme.parallel.strategy=NONE.
|
Resumable initial load checkpoints
Initial Load Checkpoints can be activated so that if the Load Operation fails you can rerun from the last successful consolidation action, rather than from the beginning.
To activate this functionality, run the initial load with the parameter checkPointName defined.
MDM will save the first checkpoint at the start of Master Data Consolidation and then after every consolidation action (Clean, Match, Merge and others).
The checkpoint is a directory with files containing records - by default the directory is named as a value of checkPointName parameter (passed to the batch load operation), and is in the temporary folder (this can be changed by runtime parameter nme.checkPoint.directory).
If the batch load fails, run it again with same value of checkPointName parameter, MDM will detect it and skip Data Acquisition, Change Detection (or Data Preparation) and any consolidation actions finished in the previous run.
It is possible to fail and rerun multiple times, each time moving further to end.
| Do not edit data between fails and reruns as Change Detection is skipped and loss of updates can occur. |
Optimized MDM processing
Optimized MDM processing means that the engine does not read any records from the persistence. This is applied automatically if there are no instance records in the MDM persistence. If there are instance records (obviously of another source system), this optimization is not used.
Automatic decision can be overridden by setting the attribute ignorePersistence (see the following example) to true.
This is an expert setting - there is no need to override to false in case of empty persistence and overriding to true might lead to wrongly computed data.
Imagine there is already one source system loaded and InitialLoad is used to load a new one - new records will not be joined (CopyColumns) nor matched (Match) with the first source system.
Loading history collectors
InitialLoad can load historical values - the content of history collector columns. Just provide values in records sent to IntegrationOutput in the column with the same name as history collector.
Values will be combined from provided historical values and current value.
Loading record metadata
InitialLoad can be configured to load record metadata (eng_last_update_date, eng_creation_tid among others). To do so:
-
Set the value of
preserveMetadataColumnsto true. -
Provide metadata in records sent to IntegrationOutput in columns with names as described below:
| Input column name | Must be always filled | Must be filled for inactive records |
|---|---|---|
source_timestamp |
||
eng_creation_tid |
X |
|
eng_creation_date |
X |
|
eng_deletion_tid |
||
eng_deletion_date |
||
eng_last_update_tid |
X |
|
eng_last_update_date |
X |
|
eng_last_source_update_tid |
||
eng_last_source_update_date |
||
eng_activation_tid |
X |
|
eng_activation_date |
X |
|
eng_deactivation_tid |
X |
|
eng_deactivation_date |
X |
Notes:
-
Record metadata must be set consistently - see second and third columns (inactive records are records with change_type = "D").
-
When providing *_tid value, be sure to have a safe number, such that will not be reused by the engine later or that has already been used.
-
Source timestamp can be loaded as usual even if
preserveMetadataColumnsis not enabled. -
You cannot load a <null> source timestamp; if you provide null timestamp, start time of the initial load’s transaction will be used.
Load record IDs
Initial load can be configured to load records IDs - so records will have given IDs instead of engine generating them automatically. To do so:
-
Set the value of
preserveIdsto true. -
Provide an id in records sent to IntegrationOutput in the column named
id.
Notes:
-
IDs must be unique for one entity, ideally across all entities.
-
For further loads, the engine will generate IDs automatically by a sequence - that sequence must be manually set to be higher than any input record ID.
Load other columns
Initial load can be configured to load any other column (not just of origin MATCH).
To do so, list those columns in attribute preserveColumns - see the example below.
The values of these columns are available as previous values (old values).
In matching, they can be accessed as is because columns of origin MATCH are input and output.
Values of columns of other origins can be accessed by configuring oldValueProvider.
master_id column can be loaded as well.
Match migration options
There are the following exclusive options to influence the migration of matching IDs:
-
PRESERVE_AND_MATCH- All provided group IDs to be preserved as they are. New rules are applied and therefore matching ID is only assigned if the group ID is empty on the migration load input. Relationship is defined across more Connected Systems. This is the suggested option for Reference data, dictionaries or manual Matching Exceptions. -
RELOAD- All provided group IDs are both re-computed and re-used, that is, previous matching result is preserved only if it is proofed by the new rules. -
PRESERVE_AND_ASSIGN- Matching is not performed at all. Records without group IDs are considered as having no key, and a unique group ID is assigned to each record. It is recommended to perform reprocess and rematch right after the migration to correctly match the records without previous result (with unique group ID assigned during the migration process).
If no option is provided, the behavior is the following: all provided IDs are preserved, missing IDs are matched (that is, Preserve and Match mode is used).
Fully configured example
<op name="initial" class="com.ataccama.nme.engine.batch.InitialLoadBatchOperation">
<sourceSystem>life</sourceSystem>
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../batch/load.comp"/>
<ignorePersistence>true</ignorePersistence> <!-- default is automatic decision based on presence or records in persistence -->
<matchingMode>PRESERVE_AND_MATCH</matchingMode> OR <matchingMode>PRESERVE_AND_ASSIGN</matchingMode> OR <matchingMode>RELOAD</matchingMode><!-- matching ids migration - additional options -->
<preserveMetadataColumns>true</preserveMetadataColumns> <!-- default is false -->
<preserveIds>true</preserveIds> <!-- default is false -->
<preserveColumns>
<column entities="*" names="mat_*" /> <!-- Similar concept as in ignoredComparisonColumns -->
</preserveColumns>
</op>Full load operation
Performs a full load of selected entities from a defined system.
Entities not mentioned in the definition will not be imported, even though the corresponding IntegrationOutput is present in the plan.
If records from other systems appear, the plan fails.
<op name="full_load_s1" class="com.ataccama.nme.engine.batch.FullLoadBatchOperation">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../batch/load.plan" />
<sourceSystem>s1</sourceSystem>
<importedEntities>
<entity name="Party" />
<entity name="Address" />
</importedEntities>
</op>One can either specify the list of imported entities in <importedEntities> element or choose all entities by specifying <importAllEntities>true</importAllEntities>.
Delta load operation
Delta load definition consists of a data source and several entity descriptors that define how each imported entity should be dealt with.
Entities without descriptors will not be imported regardless if the corresponding IntegrationOutput is present in the plan or not.
Each entity type can have a columns element listing only the columns that are loaded and affected by the operation.
<op name="delta_load" class="com.ataccama.nme.engine.batch.DeltaLoadBatchOperation">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../batch/load.plan" />
<descriptors>
<descriptor class="com.ataccama.nme.engine.batch.load.AutonomousEntity" name="GenderLookup" />
<descriptor class="com.ataccama.nme.engine.batch.load.CentralEntity" name="Party" keyColumn="source_id"/>
<columns>
<column>src_birth_date</column>
</columns>
<descriptor class="com.ataccama.nme.engine.batch.load.CentralEntity" name="Contract" keyColumn="source_id"/>
<descriptor class="com.ataccama.nme.engine.batch.load.DependentEntity" name="AkaName" keyColumn="party_source_id" centralEntity="Party"/>
<descriptor class="com.ataccama.nme.engine.batch.load.PartitionedDependentEntity" name="Address" >
<partitions>
<partition originId="sys1#PartyAddress" keyColumn="party_source_id" centralEntity="Party" />
<partition originId="sys1#ContractAddress" keyColumn="contract_source_id" centralEntity="Contract" />
</partitions>
</descriptor>
</descriptors>
</op>AutonomousEntity
This is the simplest case. The entity is processed independently from the rest of the entities.
The change is determined by input column change_type (I,U,D), the data is matched with the hub using (origin, source_id) combination.
The only parameter is name, the name of the entity from model.xml.
CentralEntity
Similar to AutonomousEntity, however, it also defines change processing for the corresponding DependentEntity descriptors.
The change is again determined by the change_type column, and the data is matched with the hub using (origin, source_id) combination.
The corresponding dependent entities are identified by the value of the column whose name is given in keyColumn.
The value must be unique for all records in AutonomousEntity.
Usually, it will be source_id.
DependentEntity
An entity depending directly on a CentralEntity, that is, it has no change indication on the input, and if a central record entity appears in the load, all its dependent records will be there as well.
The change is determined by the change_type on the corresponding central entity and locating all the dependent records in the hub; the two lists are compared using source_id, and the changes are processed accordingly.
The central entity record is obtained using the value of keyColumn column in the entity given in centralEntity.
An error will occur (and load will fail) if the load contains a dependent entity record without its central entity record.
A good example of the dependent entity is a subelement in an XML file.
For example, the top element of the XML file holds the client data and has the change_type column.
A subelement like address or contact is dependent because all occurrences of mentioned entities are involved in the incoming data.
Output interfaces
Export operations are used to export data from MDM hub.
<op class="com.ataccama.nme.engine.batch.StandardBatchExportOperation" name="batch_export">
<dataProviders>
<dataProvider prefix="inst_" class="com.ataccama.nme.engine.batch.InstanceLayerDataSource" scope="ACTIVE"/>
<dataProvider viewName="dst" prefix="dst_" class="com.ataccama.nme.engine.batch.MasterLayerDataSource" scope="EXISTING"/>
<dataProvider prefix="instInc_" class="com.ataccama.nme.engine.batch.InstanceLayerDeltaDataSource" scope="EXISTING"/>
</dataProviders>
<publisher class="com.ataccama.nme.dqc.batch.PlanBatchExportPublisher" planFileName="../batch/batch_export.plan">
<pathVariables>
<pv name="BATCH_OUT" value="/mdc/data/out"/>
</pathVariables>
</publisher>
</op>Parameters:
-
scope:-
ACTIVE: Exports only active records.
-
EXISTING (default)
-
-
prefix: Prefix of integration inputs using this provider. -
viewName(master only): Name of the master layer from which to provide data. -
sourceSystem(instance only, optional): If defined, only data from the specified source system will be exported.
Output interfaces with conditions
There are 4 more data providers that allows advanced filtering:
-
MasterEntityDataSourcefor master entity -
MasterEntityDeltaDataSourcefor incremental master entity -
InstanceEntityDataSourcefor instance entity -
InstanceEntityDeltaDataSourcefor incremental instance entity
These data providers exports records of only one entity but user can configure record filtering. In addition to the parameters defined:
-
Set parameter
entity -
You can specify conditions (more conditions are evaluated as AND) but there can be only one condition per column:
<conditions>
<condition column="src_gender" value="M" operator="EQ" />
...
</conditions>Possible values for parameter operator:
Value |
EQ |
GT |
LT |
GE |
LE |
NE |
LIKE |
IS_NULL |
IS_NOT_NULL |
Meaning |
= |
> |
< |
>= |
⇐ |
<> |
LIKE |
IS NULL |
IS NOT NULL |
The LIKE operator syntax uses wildcard * (meaning any characters).
See example below.
If the IS_NULL and IS_NOT_NULL operators are used, value should be empty.
Full example:
<dataProvider prefix="mas_party_" class="com.ataccama.nme.engine.batch.export.MasterEntityDataSource" scope="ACTIVE" entity="party" viewName="mas">
<conditions>
<condition column="cio_gender" value="M" operator="EQ" />
<condition column="score_instance" value="1000" operator="LT" />
<condition column="cio_first_name" value="John*" operator="LIKE" />
<condition column="cio_last_name" operator="IS_NOT_NULL" />
<conditions>
</dataProvider>Special interfaces
Partial reprocess operation
Partial reprocess operation is a special type of a load operation. Its purpose is to reprocess selected instance records stored in MDM storage: selected records are read from the MDM storage and sent to the MD Consolidation process.
Records of various origins (different entities and records from different source systems) can be reprocessed together in one load operation.
<op name="reprocess" class="com.ataccama.nme.engine.batch.ReprocessBatchOperation" reprocessFromAction="CLEANSE">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../batch/reprocess.plan" />
<recordIdentification>SOURCE_ID</recordIdentification>
</op>Parameters:
-
dataProvider- Same as in other load operations, see Data providers. -
recordIdentification:SOURCE_ID(default) orID. Specifies how the records are identified - whether the (origin,source_id) pair or the id column is used. -
reprocessFromAction: The starting point in the consolidation plan. Possible values areCLEANSE(default),MATCH,AGGREGATE,MERGE.CLEANSEruns the standard processing of the entire consolidation plan. The other values skip preceding actions and start from the selected one. -
rematchStrategy: Controls how records are rematched during reprocessing. Possible values:-
NO_REMATCH(default): Records are reprocessed but not rematched. -
PRESERVE_MANUAL: Records are rematched, but existing manual matches, splits, and resolved matching proposals are kept in place. -
REMOVE_MANUAL: Records are rematched and any existing manual decisions are discarded.For more details, see Rematch strategy.
-
The partial reprocess operation reads the record identifiers from the correctly named Integration Outputs and reprocesses the corresponding records that have been found in the MDM storage.
-
Record identifiers not corresponding to any record will be reported as ", nnn request(s) ignored" in Data loading phase.
-
Unmodified records will not be written and will be reported as ", nnn record(s) ignored" during the Committing step.
The partial reprocess operation can force rematching as well - Integration Output together with record identifier expect rematch_type (rematchTypeColumns of all matchings of entity corresponding to Integration Output).
Example input with recordIdentification set to SOURCE_ID for Integration Output of entity party having two matchings with rematchTypeColumns rematch_type and rematch_type_mkt:
| source_id | origin | rematch_type | rematch_type_mkt |
|---|---|---|---|
P854637 |
crm#party#party |
true |
false |
P216584 |
crm#party#party |
true |
false |
C68125 |
crm#party#party |
false |
false |
For details about each consolidation action, see Model.
Full reprocess operation
Similar to the partial reprocess operation but processes all instance records of the selected entities; useful during migrations. There is no data provider nor plan file for this operation.
In this operation, all data from the selected entities are read, so data in the MDM storage and input data are matched. Similarly to the partial reprocess operation, unmodified records are reported as ", nnn record(s) ignored" during the Committing phase.
<op name="full_rematch" class="com.ataccama.nme.engine.batch.FullReprocessBatchOperation" description="Reprocess party starting with matching" processAllEntities="false" reprocessFromAction="MATCH">
<processedEntities>
<entity name="Party"/>
</processedEntities>
</op>Parameters:
| Parameter | Description |
|---|---|
processAllEntities |
If |
processedEntities |
List of selected entities if |
reprocessFromAction |
The starting point in the consolidation plan. Possible values:
|
rematchStrategy |
Controls how records are rematched during reprocessing.
Replaces the former Possible values:
For more details, see Rematch strategy. |
preserveMetadataColumns |
Expert setting - if |
ignorePersistence |
Full reprocess operation has performance optimization.
If
You can turn off this optimization by setting this to |
Partial master reprocess operation
Partial master reprocess operation reprocesses selected master records stored in MDM storage. It is similar to the instance-level partial reprocess operation but operates on master records read from a configured master view.
<op name="mas_remerge" class="com.ataccama.nme.engine.batch.MasterReprocessBatchOperation"
description="Remerge selected masters"
masterView="masters" reprocessFromAction="MERGE">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource"
planFileName="../engine/load/reprocess/mas_remerge.comp"/>
</op>Parameters:
-
masterView: Name of the master view to which the master entities belong. -
dataProvider: Same as in other load operations, see Data providers. -
reprocessFromAction: The starting point in the consolidation plan. Possible values:-
VALIDATE: Validates master data, if validation is configured in the model. -
MERGE: Recreates master records according to the merging plan configured in the model, then performs validation.
-
Full master reprocess operation
Similar to the partial master reprocess operation but processes all master records of the selected entities. There is no data provider nor plan file for this operation.
<op name="full_mas_revalidate" class="com.ataccama.nme.engine.batch.FullMasterReprocessBatchOperation"
description="Revalidate of whole master party data"
masterView="masters" processAllEntities="false" reprocessFromAction="VALIDATE">
<processedEntities>
<entity name="party"/>
</processedEntities>
</op>Parameters:
| Parameter | Description |
|---|---|
masterView |
Name of the master view to which the master entities belong. |
processAllEntities |
If |
processedEntities |
List of selected entities if |
reprocessFromAction |
The starting point in the consolidation plan. Possible values:
|
Manual match operation
ManualMatch is a special type of load operation that can load manual match operation requests.
<op name="manual_match" class="com.ataccama.nme.engine.batch.ManualMatchBatchOperation">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../batch/manual_match.plan" />
</op>Operation by default expects input for all Matching steps (that is, matchings configured in matchingOperation). That can be optionally limited to only some matchings:
<op name="manual_match" class="com.ataccama.nme.engine.batch.ManualMatchBatchOperation">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../batch/manual_match.plan" />
<matchings>
<matching>sin</matching> <!-- "sin" is name of matching in matchingOperation in model configuration file -->
<!-- more -->
</matchings>
</op>Expected input columns are:
| Column name | Type | Description |
|---|---|---|
|
STRING |
Possible values are:
|
|
LONG |
Instance record id to be merged or split (required for |
|
LONG |
To isolate several instance records together to the same master group, set the same value in this column (optional in |
|
LONG |
Target master id to be set on selected instance records (required for Column name is prefix "target_" plus the name configured in matchingOperation in model configuration file, default is |
* In case of multiple Matching steps, there is a pair of <master_id_column> , target_<master_id_column> for every Matching step (names are taken from configuration of matching operation in model configuration file).
Task status export
Task Status is a special type of export operation.
The information about the MDM executor tasks is internally stored as a CLOB in table <prefix>_TASKS.
Similar status information is also available for Event Handlers (internally stored as a CLOB in the <prefix>_EH_TASKS table).
To get the status information, you can use the standard batch export with special data providers:
<op name="task_info" class="com.ataccama.nme.engine.batch.StandardBatchExportOperation">
<dataProviders>
<dataProvider class="com.ataccama.nme.engine.batch.TaskInfoDataSource" prefix="te_"/>
<dataProvider class="com.ataccama.nme.engine.batch.TaskEventHandlerInfoDataSource" prefix="eh_" />
</dataProviders>
<publisher class="com.ataccama.nme.dqc.batch.PlanBatchExportPublisher" planFileName="../export/task_info.comp"/>
</op>Parameters:
-
dataProvider
class:-
TaskInfoDataSourcefor executor task info (batch load, batch export, RW service). -
TaskEventHandlerInfoDataSourcefor event handler task information.-
prefix: Prefix of integration inputs using this provider.
-
-
Both `dataProvider`s provide two inputs in the export plan:
-
tasks - One record per tasks.
-
subtasks - Detailed information; each task can have 0 or more subtasks.
Because both providers have the same name of entities (see below) for their inputs, it is recommended to prefix event handler inputs with, for example, eh_.
Task executor can be prefixed as well.
|
Input tasks
Input tasks slightly differ for executor tasks and event handler tasks.
| Column name | Column type | Description |
|---|---|---|
id |
LONG |
Task ID |
task_id |
LONG |
Available only for event handler tasks - task id (batch load execution or RW service call) that triggered the event handler task |
name |
STRING |
Operation name |
result |
STRING |
Not available for event handler tasks |
enqueued |
DATETIME |
Not available for event handler tasks |
started |
DATETIME |
Start timestamp |
finished |
DATETIME |
Finished timestamp |
duration |
LONG |
Duration in milliseconds |
Input subtasks
Input subtasks are the same for executor tasks and event handler tasks.
| Column name | Column type | Description |
|---|---|---|
task_id |
LONG |
Link to the Task table above |
name |
STRING |
Sub-operation name |
started |
DATETIME |
Start timestamp |
finished |
DATETIME |
Finished timestamp |
duration |
LONG |
Duration in milliseconds |
detail |
STRING |
|
volume |
LONG |
Number of records (if it makes sense) |
parents |
STRING |
List of parents' names, concatenated by semi-colon |
Task migration load operation
Task migration load operation allows migrating tasks and drafts.
<op class="com.ataccama.nme.internal.engine.tasks.batch.AppendTaskLoadBatchOperation" description="" name="migration_load_task">
<applyDefaultValues>false</applyDefaultValues>
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../engine/migration/migration_load_task.comp"/>
</op>Parameters:
-
<applyDefaultValues>: If set totrue,nulland empty input values are overridden by task template defaults. -
dataProvider: Same as in other load operations, see Data providers.
The following table shows the columns in the task step, which records the data to the table tasks_tasks.
| Column name | Column type | Description |
|---|---|---|
id |
LONG |
Task identifier (will be regenerated by the database). |
type |
STRING |
Task type.
Possible values are: |
name |
STRING |
Name of the task. |
description |
STRING |
Task description. |
status |
STRING |
Task status.
Possible values are: |
entity_id |
STRING |
Entity identifier. |
workflow_name |
STRING |
Name of the workflow, for example, |
workflow_step |
STRING |
Name of the workflow step. |
user_assignee |
STRING |
Name of the user to whom the task is assigned. |
group_assignee |
STRING |
Name of the group to which the task is assigned. |
severity |
STRING |
Severity of the issue.
Possible values are: |
comments |
STRING |
Comments made about the task, in serialized JSON format. |
history |
STRING |
List of operations performed within the task, in serialized JSON format. |
created |
DATETIME |
Date and time when the task was created. |
created_by |
STRING |
Name of the person that created the task. |
last_edited |
DATETIME |
Date and time when the task was last edited. |
last_edited_by |
STRING |
Name of the person that last edited the task. |
The following table shows the columns in the task_record step, which records the data to the table tasks_tasks_rec_ids.
| Column name | Column type | Description |
|---|---|---|
record_id |
LONG |
Record identifier. |
task_id |
LONG |
Task identifier. |
entity_id |
STRING |
Entity identifier. |
The following table shows the columns in the draft step, which records the data to the table tasks_drafts.
| Column name | Column type | Description |
|---|---|---|
id |
LONG |
Draft identifier. |
task_id |
LONG |
Identifier of the task that the draft belongs to. |
status |
STRING |
Status of the draft.
Possible values are: |
operations |
STRING |
Operations that were performed on the draft. |
created |
DATETIME |
Date and time when the draft was created. |
created_by |
STRING |
Name of the person that created the draft. |
last_edited |
DATETIME |
Date and time when the draft was last edited. |
last_edited_by |
STRING |
Name of the person that last edited the draft. |
publishId |
LONG |
Identifier of the publish operation. |
The following table shows the columns in the draft_record step, which records the data to the table tasks_drafts_rec_ids.
| Column name | Column type | Description |
|---|---|---|
record_id |
LONG |
Record identifier. |
draft_id |
LONG |
Draft identifier. |
entity_id |
STRING |
Entity identifier. |
Manual match decision load operation
Manual match migration load operation allows migrating manual match decisions.
<op class="com.ataccama.nme.engine.batch.AppendManualMatchDecisionLoadBatchOperation" description="" name="migration_load_mmd">
<preserveMetadataColumns>true</preserveMetadataColumns>
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../engine/migration/migration_load_mmd.comp"/>
</op>Parameters:
-
<preserveMetadataColumns>: If set totrue, theeng_columns are not overridden. -
dataProvider: Same as in other load operations, see Data providers.
Expected input columns are:
| Column name | Column type | Description |
|---|---|---|
instance_entity |
STRING |
Name of the instance entity. |
operation_type |
STRING |
Type of the operation, for example, |
instance1_id |
LONG |
Identifier of the first merged or split instance. |
instance1_master_id |
LONG |
Identifier of the master record that was merged or split. |
instance1_data |
STRING |
Definition of the operation in JSON format. |
instance2_id |
LONG |
Identifier of the second merged or split instance. |
instance2_master_id |
LONG |
Identifier of the master record that was merged or split. |
instance2_data |
STRING |
Definition of the operation in JSON format. |
eng_creation_date |
DATE |
Date when the match or split was done. |
Advanced features for input and output interfaces
Path variables and additional parameters
Both load and export operations have the ability to define their path variables. They can be either constant or supplied as a parameter from a workflow. The same applies to additional parameters.
...
<loadOperations>
<op class="com.ataccama.nme.engine.batch.DeltaLoadBatchOperation" name="crm_delta" sourceSystem="crm" sourceDeletionStrategy="deactivate">
<dataProvider class="com.ataccama.nme.dqc.batch.PlanBatchDataSource" planFileName="../engine/load/crm_delta.comp">
<pathVariables>
<pathVariable name="PATH" value="${PATH|XXXXINSTALL_DIRXXX/cdi_hub/data/ext}"/>
</pathVariables>
<additionalParameters>
<additionalParameter name="in_param_name" value="'CRM'"/>
</additionalParameters>
</dataProvider>
<descriptors>
<descriptor class="com.ataccama.nme.engine.batch.load.CentralEntity" keyColumn="source_id" name="party"/>
<descriptor centralEntity="party" class="com.ataccama.nme.engine.batch.load.DependentEntity" keyColumn="party_source_id" name="address"/>
<descriptor centralEntity="party" class="com.ataccama.nme.engine.batch.load.DependentEntity" keyColumn="party_source_id" name="contact"/>
<descriptor centralEntity="party" class="com.ataccama.nme.engine.batch.load.DependentEntity" keyColumn="parent_source_id" name="rel_party2party"/>
<descriptor centralEntity="party" class="com.ataccama.nme.engine.batch.load.DependentEntity" keyColumn="party_source_id" name="id_document"/>
</descriptors>
</op>
</loadOperations>
<exportOperations>
<op class="com.ataccama.nme.engine.batch.StandardBatchExportOperation" name="full_instance_export">
<dataProviders>
<dataProvider class="com.ataccama.nme.engine.batch.InstanceLayerDataSource" scope="ACTIVE"/>
</dataProviders>
<publisher class="com.ataccama.nme.dqc.batch.PlanBatchExportPublisher" planFileName="../engine/export/full_instance_export.comp">
<pathVariables>
<pv name="BATCH_OUT" value="${pathVar_BATCH_OUT|XXXXINSTALL_DIRXXXX/cdi_hub/data/out}"/>
</pathVariables>
<additionalParameters>
<additionalParameter name="fileName" value="'FULL_INSTANCE_'+${v_today}+'.xml'"/>
<additionalParameter name="fileType" value="56"/>
</additionalParameters>
</publisher>
</op>
</exportOperations>
...Was this page useful?