
Edge Architecture
Edge architecture is built on two core principles:
Bring your own storage: All sensitive data and processing results stay in object storage you own. Edge currently uses AWS S3.
Bring your own cloud: Your organization provides the AWS account and retains full ownership of the underlying infrastructure. Processing components are deployed there — by Ataccama for managed deployments, by you for self-managed.
Architecture overview
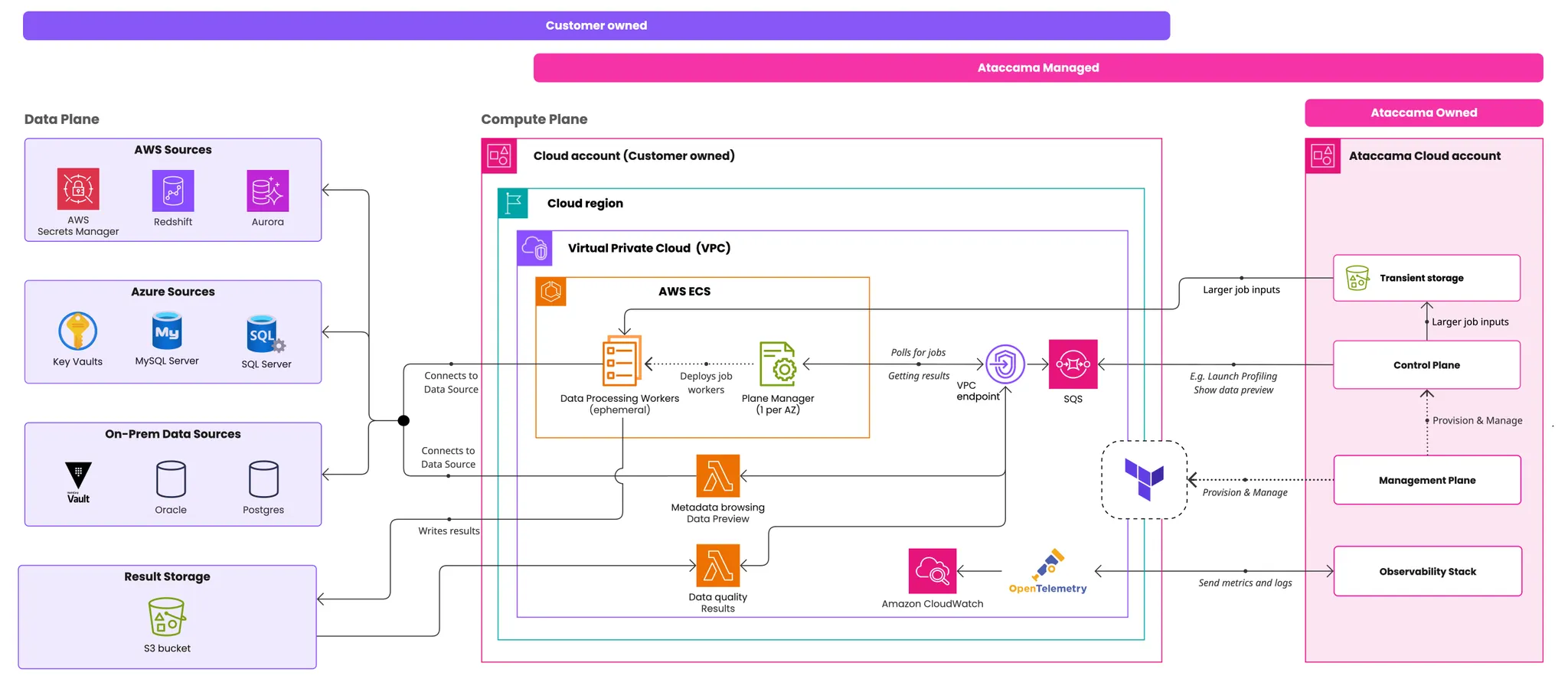
Edge architecture separates processing and data management across four functional areas.

This structure is the same for both deployment options. The deployed components differ; see the following diagrams for details.
Ataccama-managed deployment
Components shown here are deployed by Ataccama through CloudFormation and Terraform Cloud automation.
Self-managed deployment
The edge runs as a set of containerized workloads on AWS ECS with Fargate runners inside your virtual private cloud (VPC). Interactive work (testing a connection, browsing schemas) is handled by AWS Lambda functions.
All communication is outbound from your account to Ataccama; no inbound connections are required.
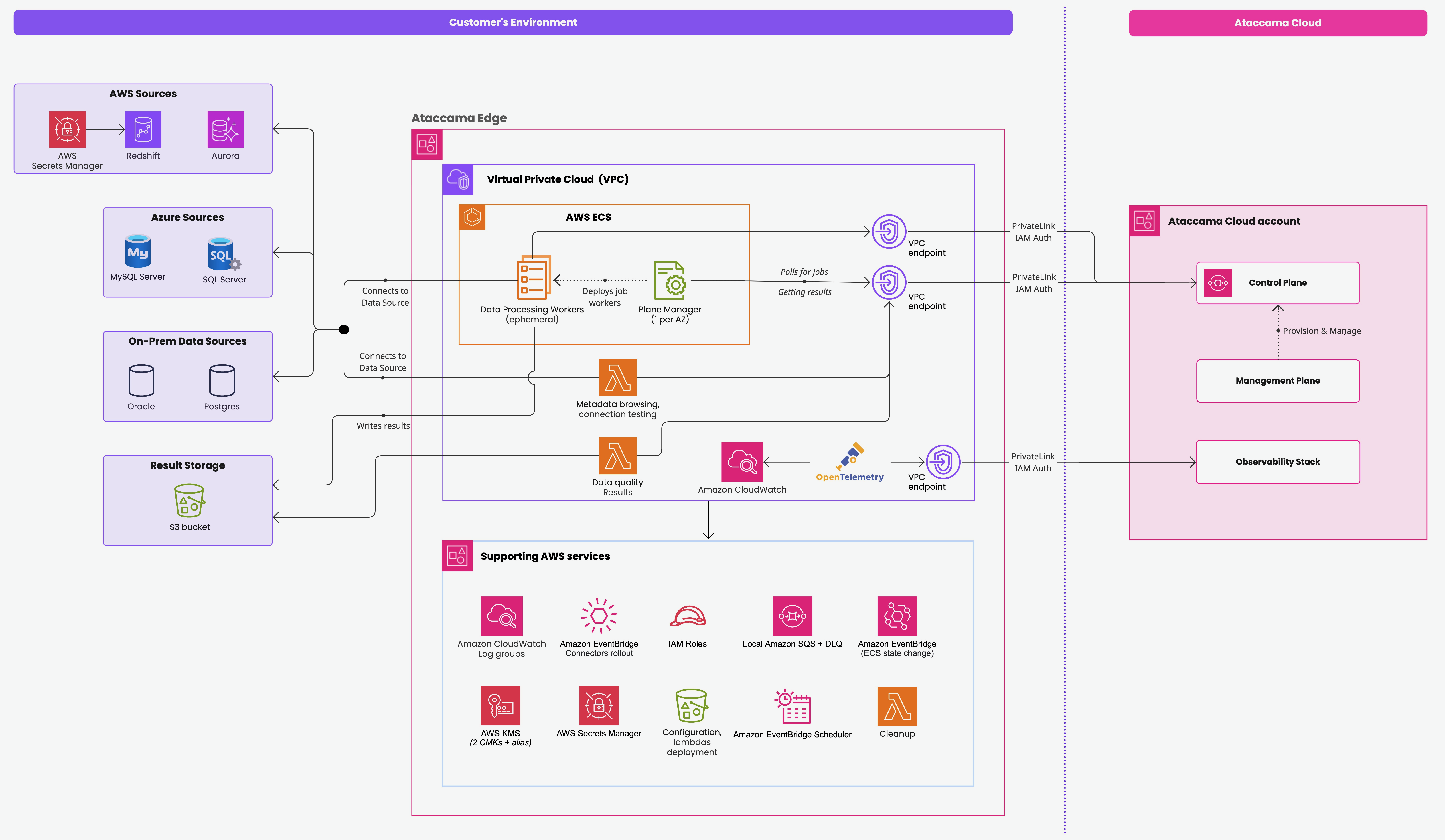
For the full list of AWS resources deployed by Terraform, see Appendix: AWS resources deployed by Terraform.
Edge compute
| Location | Description | Management |
|---|---|---|
Your AWS account. |
Runs the components that process data from the data sources. The edge compute doesn’t directly store primary data or processing results. |
Ataccama-managed software running on customer-owned infrastructure. |
Data sources
| Location | Description | Management |
|---|---|---|
Your environment. |
Holds your primary data and the sensitive results produced by the edge compute. Primary data is retrieved by the edge compute on demand for processing and viewing; the only data that crosses components persistently is reference data you explicitly import. |
Customer-owned and managed. |
Control plane
| Location | Description | Management |
|---|---|---|
Ataccama infrastructure (Ataccama ONE). |
Lets you browse metadata, set up DQ rules, and view processing results. The control plane has no direct access to your data: sensitive data is loaded from your storage on demand when you view or work with it in Ataccama ONE, and isn’t stored, derived, or cached. |
Ataccama-owned and managed. |
Ataccama Cloud Portal
| Location | Description | Management |
|---|---|---|
Ataccama infrastructure. |
The admin and configuration console where you manage edge instances and access deployment artifacts and upgrades. How the edge compute is run depends on the deployment option:
|
Ataccama-owned and managed. |
Security and communication
All communication between components uses TLS 1.3. Sensitive data and processing results are encrypted at the application level both in transit and at rest.
Key communication patterns are as follows:
-
Cloud Portal to edge compute: No direct access. Configuration is delivered through Terraform-based automation: ArgoCD and Terraform Cloud for Ataccama-managed deployments, Terraform bundles applied by your team for self-managed.
-
Control plane to edge compute: Communication goes through message queues, with pre-signed URLs used for transient storage.
-
Edge compute to Ataccama: All cross-account traffic is initiated outbound by the edge compute: pulling container images from an Ataccama-managed registry, exchanging control plane messages over SQS, and assuming roles via STS. No inbound connections to your environment are required.
-
Job execution flow:
-
The control plane sends a job request via the message queue.
-
The edge compute retrieves the job image from the OCI registry.
-
The job processes data and writes results to your storage.
-
Metadata returns to the control plane.
-
|
For a detailed breakdown of which data types are stored where and how each is protected, contact your Customer Success Manager.
The edge compute retrieves credentials from a provided secrets store and writes results to your storage using the IAM role you supplied during edge instance setup.
Private and public connectivity
All cross-account traffic is initiated outbound by the edge compute — no inbound access to your network is required. The following table shows which connections stay on private AWS networking and which leave your VPC through your NAT gateway.
| Connection | Network path |
|---|---|
Control plane to edge: task exchange via message queues (SQS) |
Private AWS networking, secured by cross-account IAM. |
Edge to the Ataccama-managed cloud bucket: data exchange via presigned URLs (job data, displayed values, reference data import) |
Private AWS networking when the edge runs in the same AWS region as the control plane. For other regions, contact your Ataccama CSM. |
Edge to your data sources and your result storage |
Remains within your network boundary, subject to the routing and firewall rules you configure. |
Container image and OCI artifact pulls from the Ataccama-managed registry |
Public internet through your NAT gateway, TLS-encrypted. |
AWS service API calls for the services listed under VPC endpoints |
Private AWS networking via VPC endpoints. For Ataccama-managed edges, the endpoints are created as part of the edge deployment. For self-managed edges, you should provision them in your own VPC; otherwise this traffic uses your NAT gateway. |
AWS service API calls for ECS, IAM, and Lambda |
Public internet through your NAT gateway, TLS-encrypted. |
|
If you’re considering a different AWS region for the edge than your Ataccama control plane, see VPC endpoints. |
Encryption and key management
All edge data at rest is encrypted with AWS KMS, using three keys: two provisioned in your AWS account and one held in Ataccama’s control-plane account (see Queue payload encryption).
In your account, Terraform provisions two customer-managed keys (CMKs):
-
A general key backing server-side encryption for the edge-account resources (S3, Secrets Manager, SQS, and EFS).
-
A DQ-encryption key protecting DQ results.
The KMS key policies are the authoritative access control for these keys: an IAM grant cannot exceed what the key policy permits.
Queue payload encryption
The task-message payloads exchanged with the control plane over SQS are encrypted with a key held in Ataccama’s control-plane account, not with the CMKs provisioned in your account.
The two SQS-triggered Lambda functions reach the keys as follows:
-
Metadata Browsing and DQ Results Reader both use the Ataccama control-plane key to decrypt the SQS message payloads they receive.
-
DQ Results Reader additionally uses the customer-provisioned DQ-encryption key to read DQ results.
Because these Lambdas are invoked directly by their SQS event sources, they are granted access to the control-plane key directly rather than through the Plane Manager’s sts:AssumeRole flow, which keeps their access narrower than a full role assumption.
Was this page useful?