
Data Freshness Custom Configuration
| For information about how to use the Freshness feature in Data Observability, see Data Observability. |
| This is an experimental feature and as such upgradability cannot be guaranteed. Connection methods for unsupported data sources and custom configurations might change with later releases. |
For the sources that support freshness by default (Snowflake, PostgreSQL, BiqQuery, and Oracle), it is not necessary to modify connection settings unless you want to: for example, if you have a custom definition for freshness within the database.
If you do have a custom freshness definition, or want to check freshness on items in databases which are not supported, it is possible to add additional configuration by selecting Modify connections settings.
Freshness checks are implemented using SQL to query database metadata tables or user tables. When database metadata tables are being queried, the required info is already exposed by database engines, as is the case with the data sources that support data freshness by default. Querying user tables means users can mimic freshness arbitrarily, using queries which produce predefined results.
Both options share the same configuration structure. The default per database engine is configured in driver properties and is used as fallback when user configuration is not supplied with the job data.
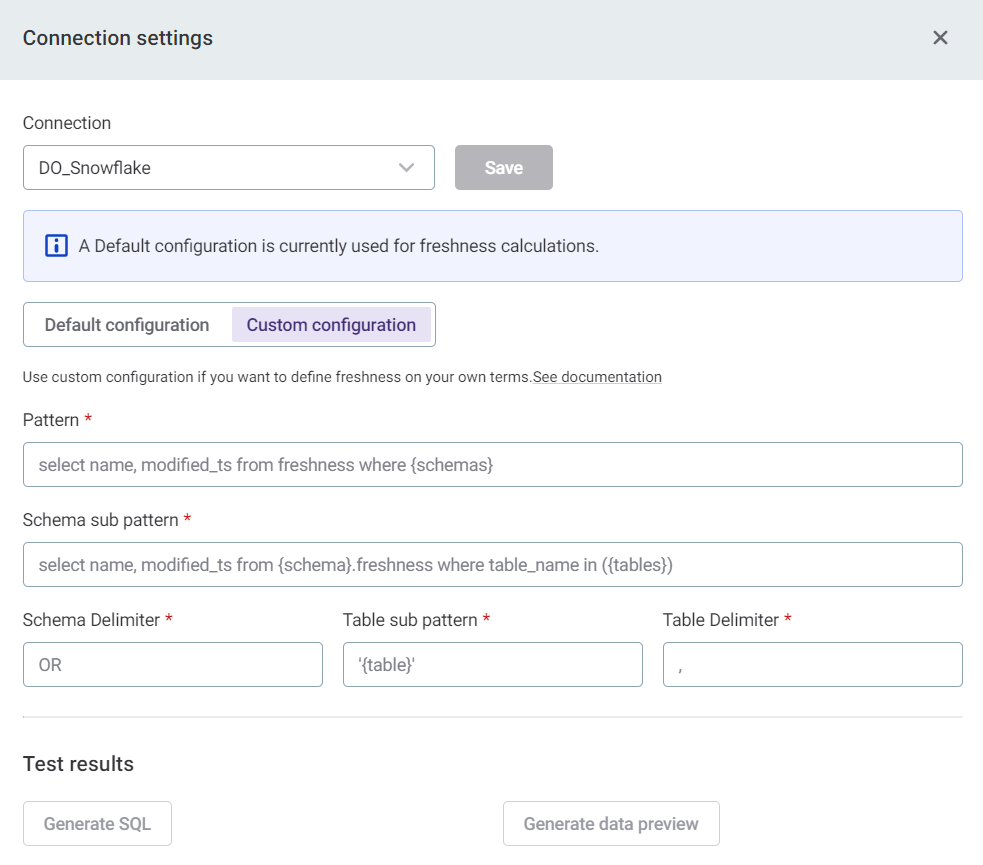
Freshness configuration
Driver level configuration is present for database engines supporting table modification timestamp natively where supported drivers are:
-
PostgreSQL
-
MS SQL
-
Oracle
-
Snowflake
-
BigQuery
-
Azure Synapse
Remaining drivers do not support it natively.
| PostgreSQL implementation is based on commit timestamps which is row level data. Thus deleting rows in fact doesn’t contribute to freshness, it might even distort it if applied on most recently changed rows. |
Driver level
This configuration is part of DPE properties and available for customization in the DPM Admin Console.
It is expressed with the following properties:
| Property | Description | ||
|---|---|---|---|
|
|||
|
Size of catalog item batch sent in single freshness query.
Default value: |
||
|
SQL query returning
|
||
|
SQL statement without result, prepares the database session for freshness query. |
||
|
SQL statement without result, counterpart for actions in |
||
|
Property defining custom freshness query (see Custom freshness). |
||
|
Property defining custom freshness query (see Custom freshness). |
||
|
Property defining custom freshness query (see Custom freshness). |
||
|
Property defining custom freshness query (see Custom freshness). |
||
|
Property defining custom freshness query (see Custom freshness). |
The freshness query is composed from list of schema.table paths (originPath in MMM) so that:
-
Tables are grouped by schema.
-
table-sub-patternwith{table}and{schema}placeholders is applied for all tables in group, result joined by table-delimiter and used further for{tables}placeholder. -
schema-sub-patternwith{tables}and{schema}placeholders is applied for all groups, result joined by schema-delimiter and used further for{schemas}placeholder. -
patternwith{schemas}placeholder is substituted and used as final query.
The query returns the columns:
-
nameas varchar, containing theschema.tableto match with catalog item. -
modified_tsas timestamp with timezone - the last modification on table.
Job level configuration
The configuration is analogous using following gRPC properties of ataccama.dppapi.freshness.FreshnessConfig:
-
enabled -
chunkSize -
supportedQuery -
prepareQuery -
cleanQuery -
checkQueryPattern -
checkQuerySchemaSubPattern -
checkQuerySchemaDelimiter -
checkQueryTableSubPattern -
checkQueryTableDelimiter
Custom freshness
This option is for when you want to define freshness in your own terms (that is, query user tables). You need to create a custom freshness configuration, with the following properties defined.
Example 1: Where clause per schema
A simple freshness setup based on table holding name and modified_ts, with input {schema1}.{table11},{schema1}.{table12}, … ,{schema2}.{table21},{schema2}.{table22}, ….
select name, modified_ts from freshness
where
-- schema 1
(table_schema='{schema1}' and table_name in ('{table11}','{table12}',...)) OR
-- schema 2
(table_schema='{schema2}' and table_name in ('{table21}','{table22}',...))Would be configured as:
-
pattern=select name, modified_ts from freshness where {schemas} -
schema-sub-pattern:(table_schema='{schema}' and table_name in ({tables})) -
schema-delimiter:\\ OR\\ -
table-sub-pattern:'{table}' -
table-delimiter:,
| Provide these properties either to DPE or in ONE after selecting Modify connection settings. |
Example 2: Query per schema
-- schema 1
select name, modified_ts from {schema1}.freshness
where table_name in ('{table11}','{table12}',...)) UNION ALL
-- schema 2
select name, modified_ts from {schema2}.freshness
where table_name in ('{table21}','{table22}',...))select * from
where table_schema='{schema2}' and table_name in ('{table21}','{table22}',...)Would be configured as:
-
pattern={schemas} -
schema-sub-pattern:schema-sub-pattern=select name, modified_ts from {schema}.freshness where table_name in ({tables}) -
schema-delimiter:\ UNION ALL\ -
table-sub-pattern:'{table}' -
table-delimiter:,
Example 3: Per table freshness
This example is adapted for PostgreSQL.
| This example has the same drawback as PostgreSQL commit timestamps: it’s based on rows and as such doesn’t capture deletes (unless we employ soft-delete, that is, keeping rows just marked as deleted). |
-- table 1
select '{schema1}.{table11}' as name, max(timestamp_ts) as modified_ts
from "{schema1}"."{table11}" UNION ALL
-- table 2
select '{schema1}.{table12}' as name, max(timestamp_ts) as modified_ts
from "{schema1}"."{table12}" UNION ALL
...Would be configured as:
-
pattern={schemas} -
schema-sub-pattern:{tables} -
schema-delimiter:\ UNION ALL\ -
table-sub-pattern:select '{schema}.{table}' as name, max(timestamp_ts) as modified_ts from "{schema}"."{table}" -
table-delimiter:\ UNION ALL\
When the tables don’t have uniform structure, you can create views that provide it and reference them in from clause using, for example, "{schema1}"."{table11}_freshness_view".
|
Was this page useful?