
Data Quality
There is no single definition of what makes data high quality: data quality is a measure of the condition of your data according to your needs. Evaluating data quality helps you identify issues in your dataset that need to be resolved.
In Ataccama ONE, you can define your needs and evaluate the data quality accordingly, using DQ evaluation rules.
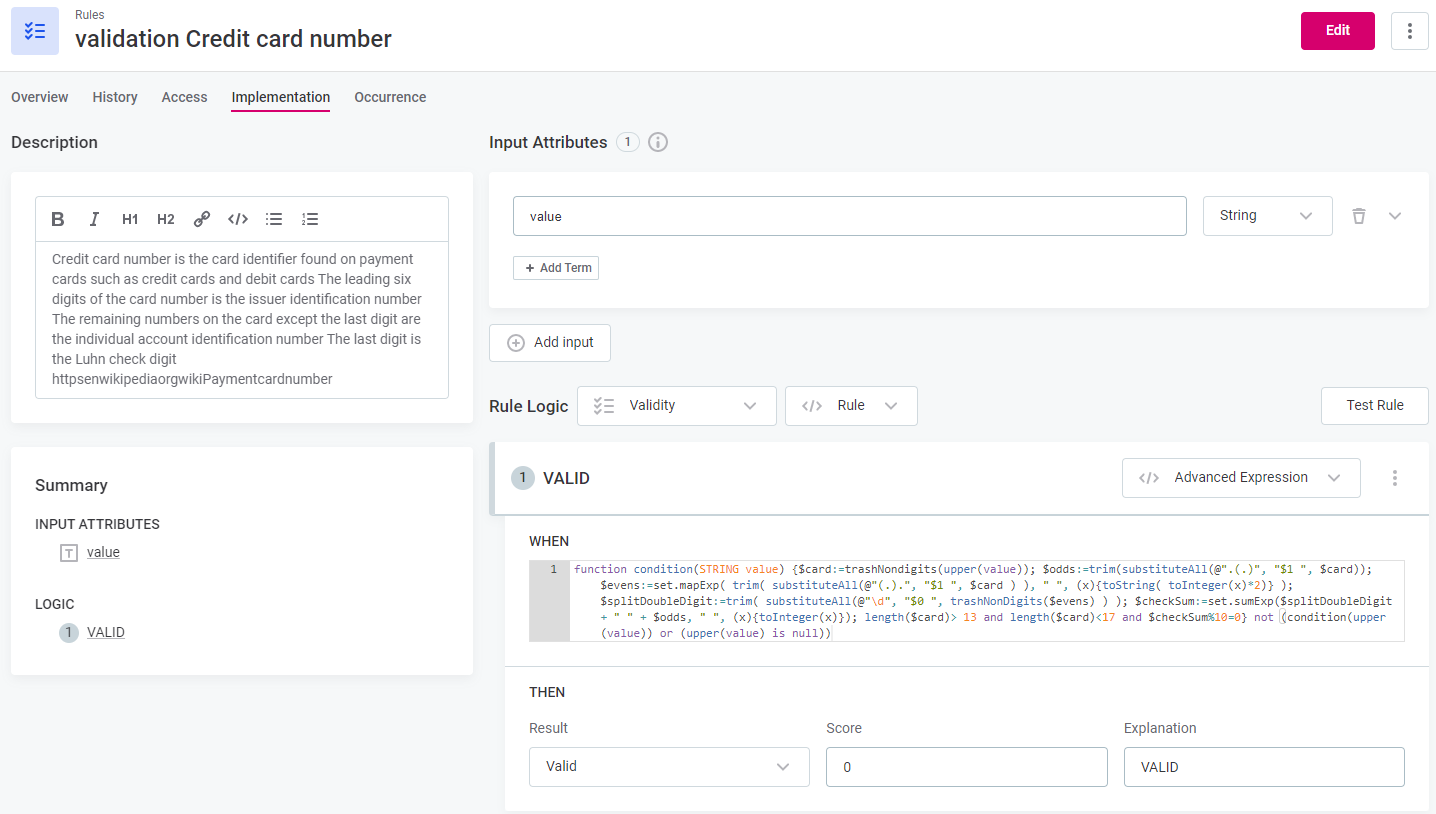
How does it work?
The basic flow is as follows:
-
Terms from the glossary are applied to catalog items through detection rules, AI, or manually.
-
DQ evaluation rules are mapped to terms (1). These contain the conditions determining which values pass the DQ rules and which fail (2).
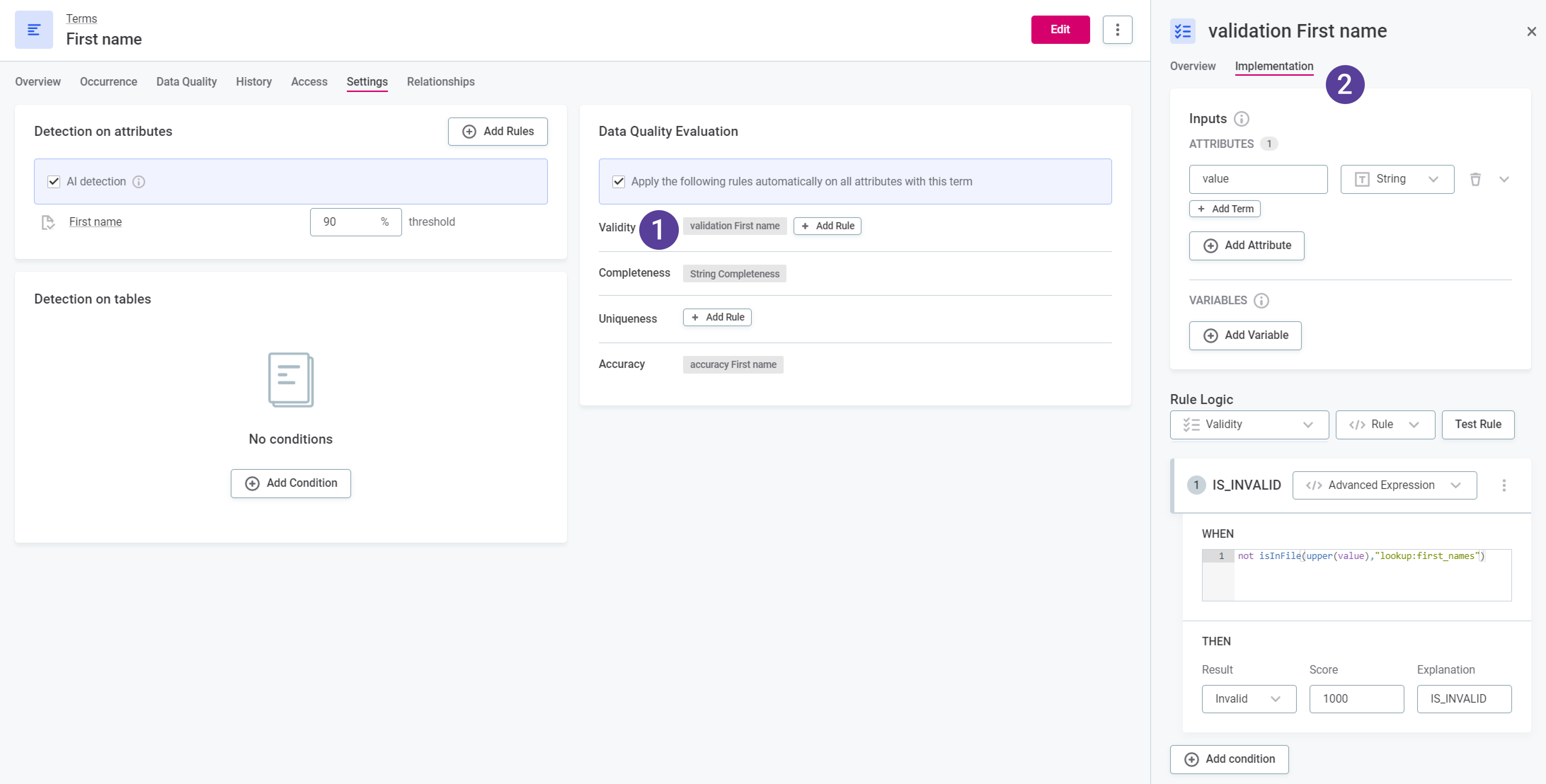
It is also possible to map DQ rules to individual attributes to run localized DQ evaluation. This is useful, for example, in cases where results have been exported from monitoring projects, remediated in ONE Data, and now, you want to re-evaluate them from the catalog. -
When you run DQ evaluation, the rules applied to terms evaluate the quality of data containing those terms.
-
The result is a data quality percentage representing the number of records which passed all applied DQ rules.
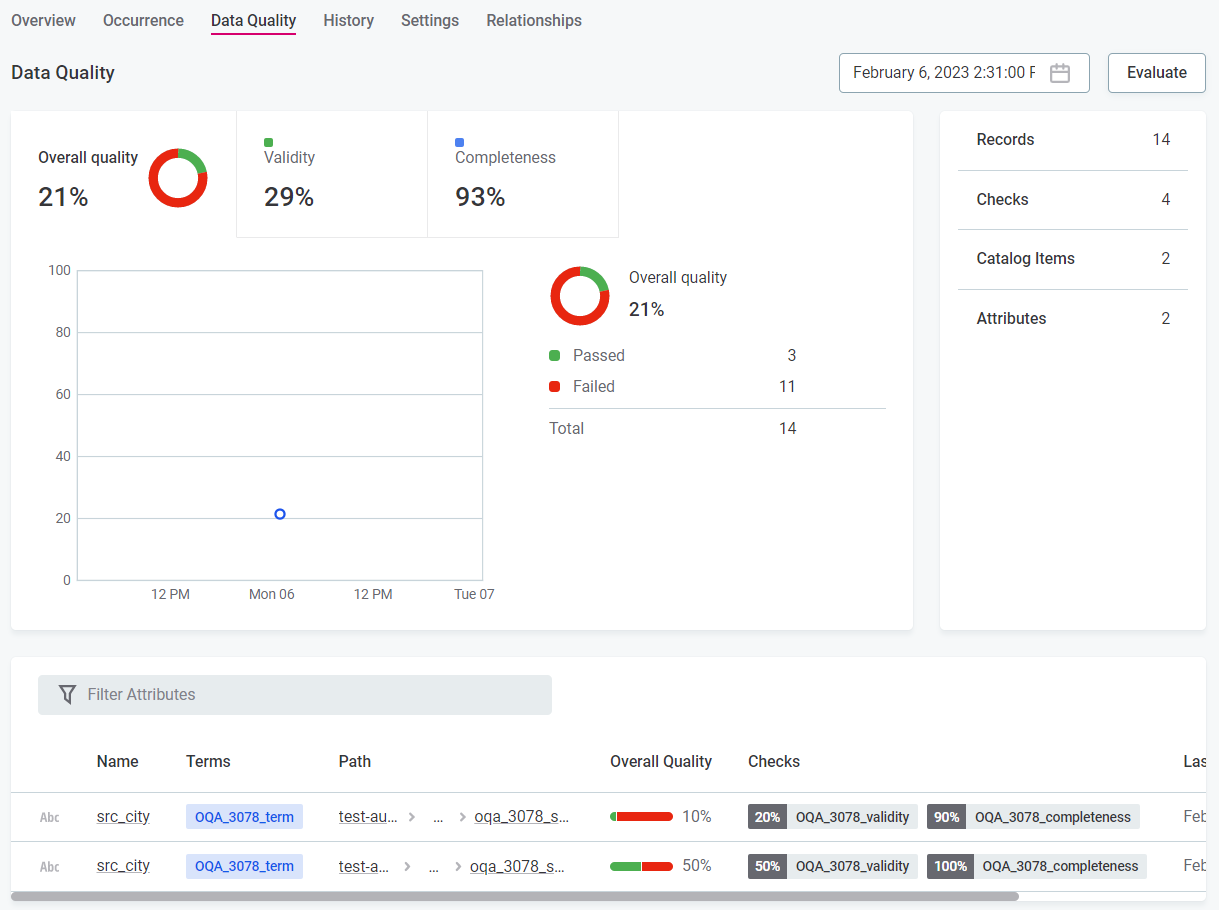
Additional checks are available in monitoring projects and in the Data Observability module: Structure checks and AI anomaly detection. However, these don’t contribute to the data quality metric.
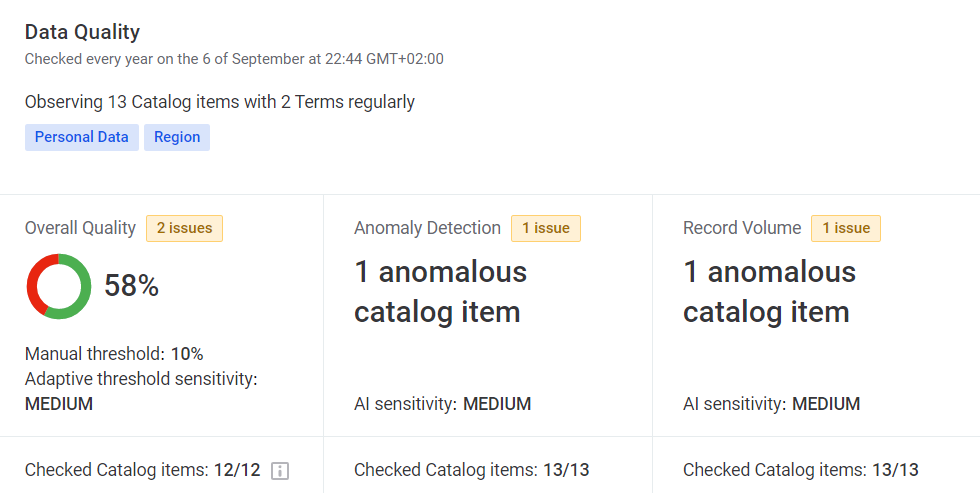
The data quality metric is found throughout the application (for example, for sources and terms as well as individual catalog items and attributes).
When is data quality evaluated?
Data quality is evaluated during a number of processes, such as:
-
Ad hoc data quality evaluation on catalog items, attributes, or terms.
-
Profiling and DQ evaluation on catalog items.
-
The Document documentation flow on sources.
-
Monitoring project runs.
-
Data observation.
Key concepts
It is vital to understand the following concepts to understand data quality evaluation in Ataccama ONE.
Terms
Terms, which are managed in the Glossary, are labels that are added to catalog items and attributes based on predefined conditions, either via detection rules or AI term suggestions. You can also manually add terms on the attribute level.
They help you to organize and understand your dataset. Automatic mapping of terms and catalog items using system-derived detection rules is known as domain detection.
-
Term assignment via detection rules - Detection rules add terms to catalog items and attributes according to the rule conditions. Both system-derived rules and user-created rules can be active in the application.
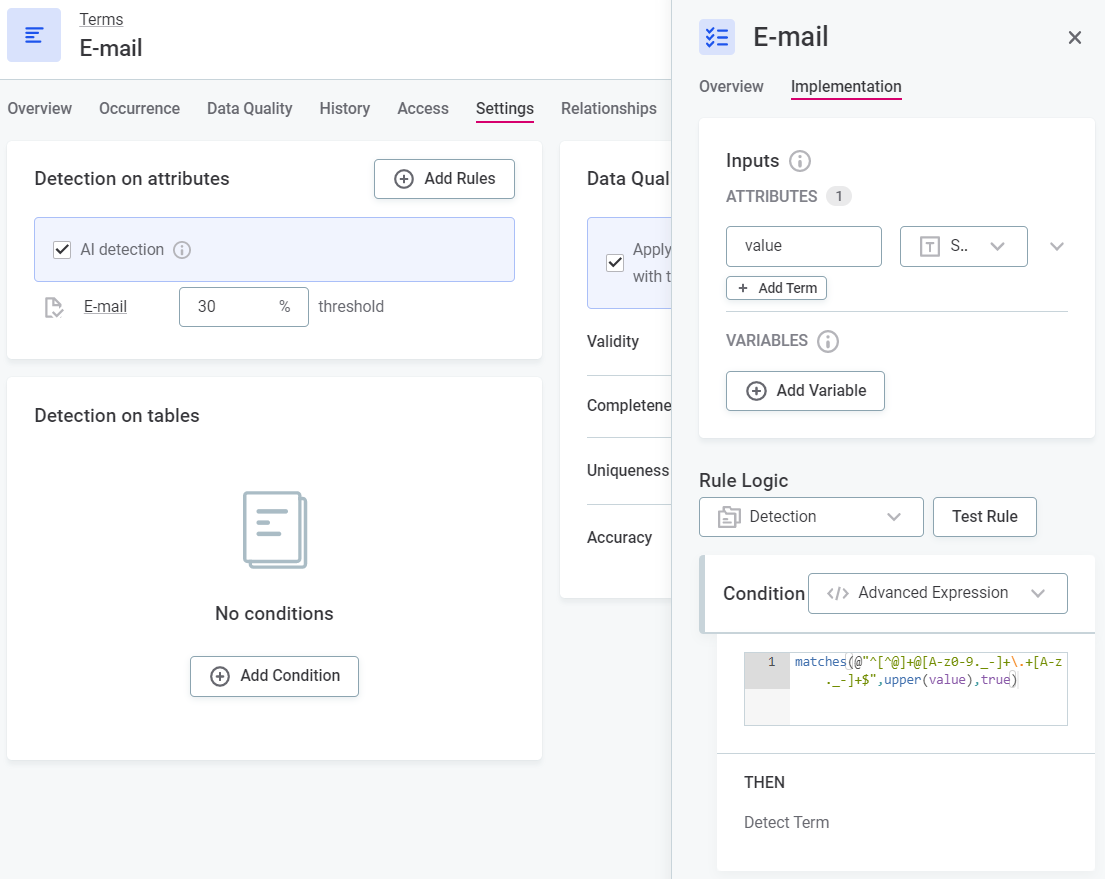
-
Term assignment via AI suggestions - AI suggests terms for catalog items and attributes after discovery of the data, either in the form of documentation flows or profiling (for more information, see terms:term-suggestions.adoc). A confidence level is provided; you can accept or reject the suggestions accordingly.
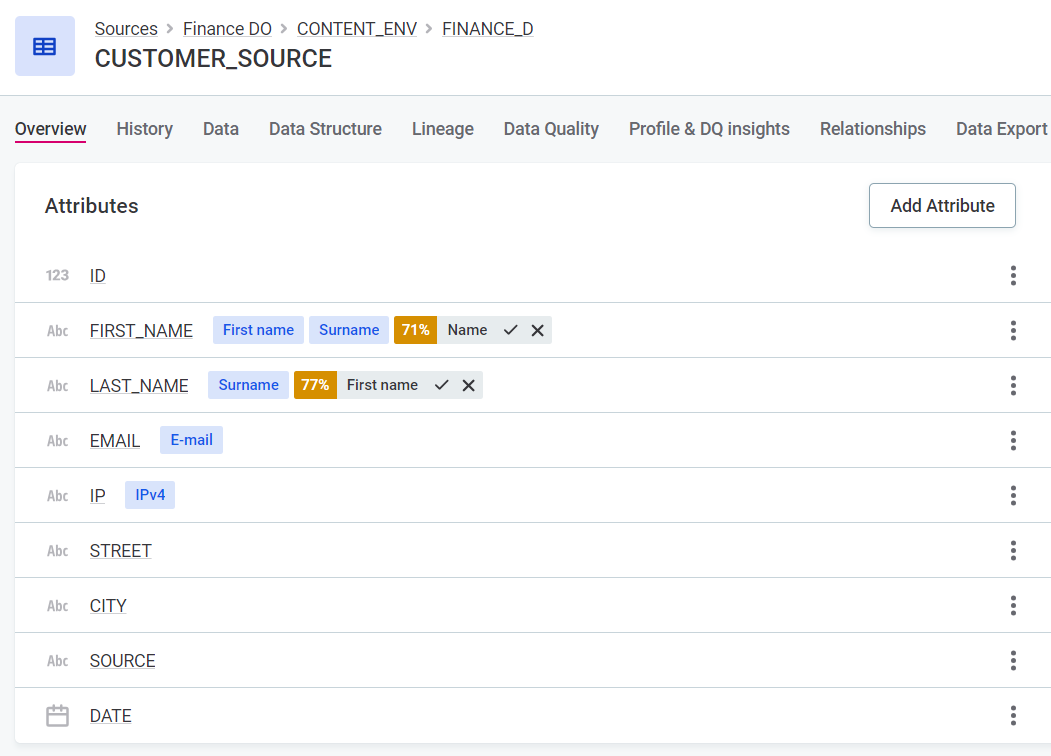
-
Manual term assignment - Manually add terms to attributes in the attribute sidebar or Overview tab.
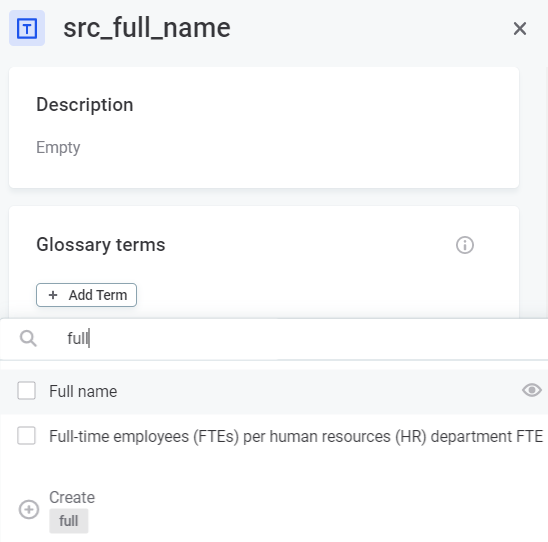
Detection rules
Detection rules add terms to catalog items and attributes based on the rule conditions. Some detection rules exist by default in the application and allow initial data discovery.
You can also define specific detection rules for your dataset. To create and apply detection rules in your dataset, see Create Detection Rule.
Data quality evaluation rules
DQ evaluation rules allow you to evaluate the quality of catalog items and attributes according to the rule conditions.
DQ evaluation rules act in one of two ways:
-
DQ evaluation rules are mapped to terms and evaluate the quality of catalog items and attributes containing those terms.
-
DQ evaluation rules are manually applied directly to attributes in the Data Catalog. For more information see Add DQ Rules to Attributes.
Ataccama ONE’s extensive rule implementation includes aggregation rules, component rules, and advanced expressions. DQ evaluation rules are further differentiated into rule dimensions, so you can indicate whether a value passes or fails according to different criteria, such as Accuracy or Completeness.
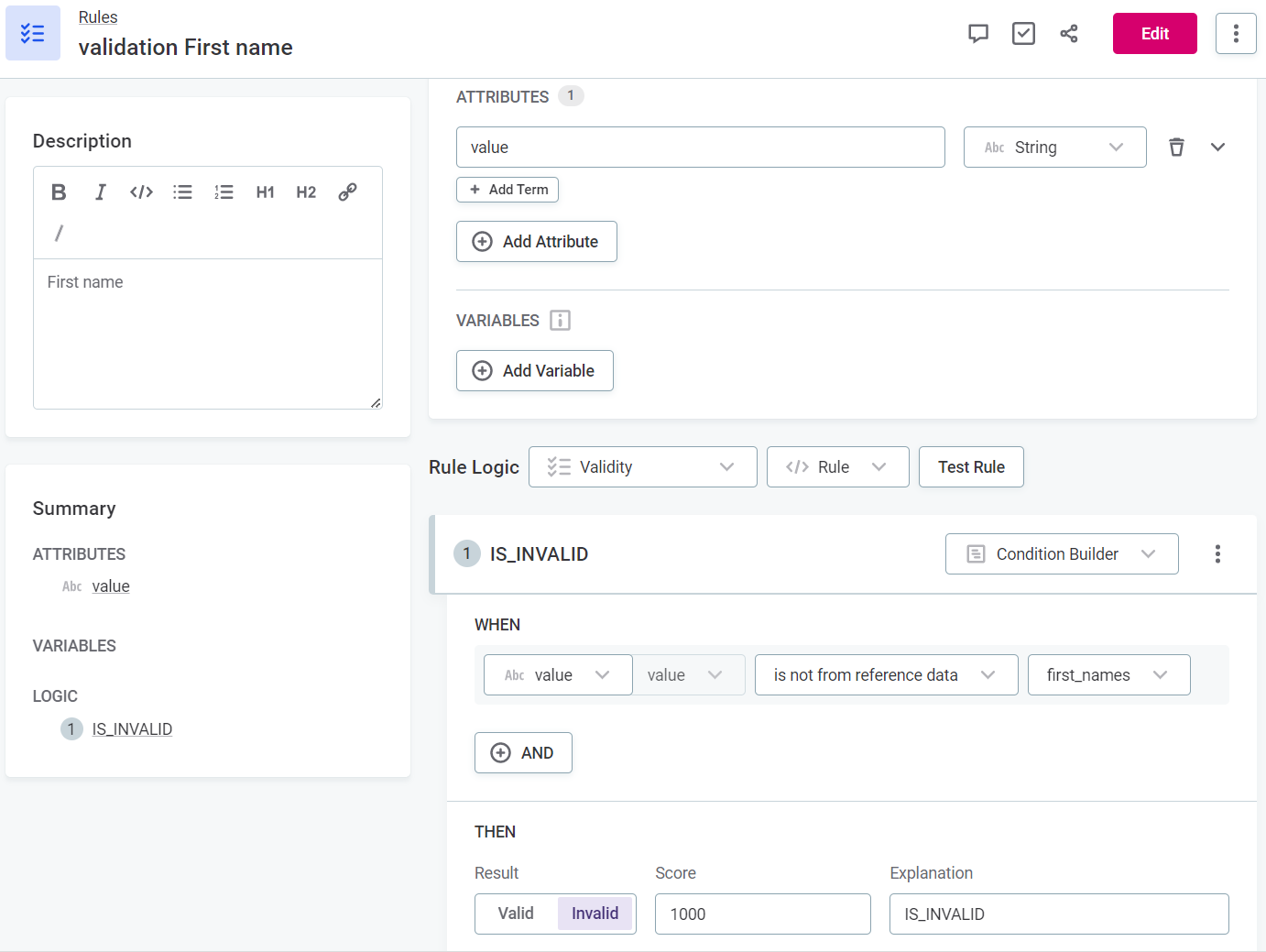
DQ dimensions
DQ dimensions allow you to see results for the data quality based on different criteria.
Use the preset dimensions or create your own, and define the results available for the dimension and whether they contribute positively or negatively to the data quality.
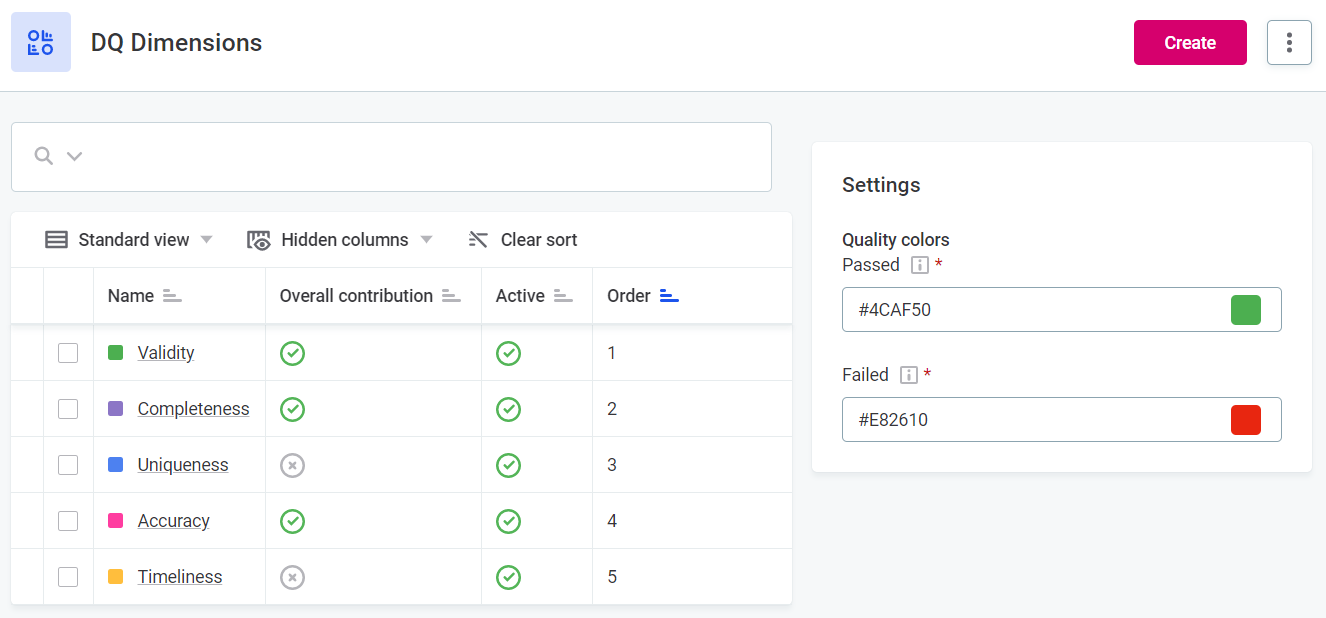
Overall quality
The overall quality metric seen throughout the application aggregates the data quality results from all contributing dimensions.
Which dimensions contribute to overall quality is defined in DQ Settings. See Data Quality Dimensions.
You can also see the results for individual data quality dimensions on the corresponding tab.
|
A tab for the individual dimension results is only available if the following two conditions are met:
|
AI anomaly detection
In the Document documentation flow, monitoring projects, full profiling and DQ evaluation, and data observability, data quality evaluation is coupled with AI anomaly detection. AI alerts you of potential anomalies in the metadata.
Choose between time-dependent and time-independent anomaly detection, depending on which better suits your dataset. You can accept or reject detected anomalies.
An additional anomaly detection feature is available: Time Series Analysis for transaction data. However, this requires additional configuration and is not part of the standard processes. For more information, see Time Series Data.
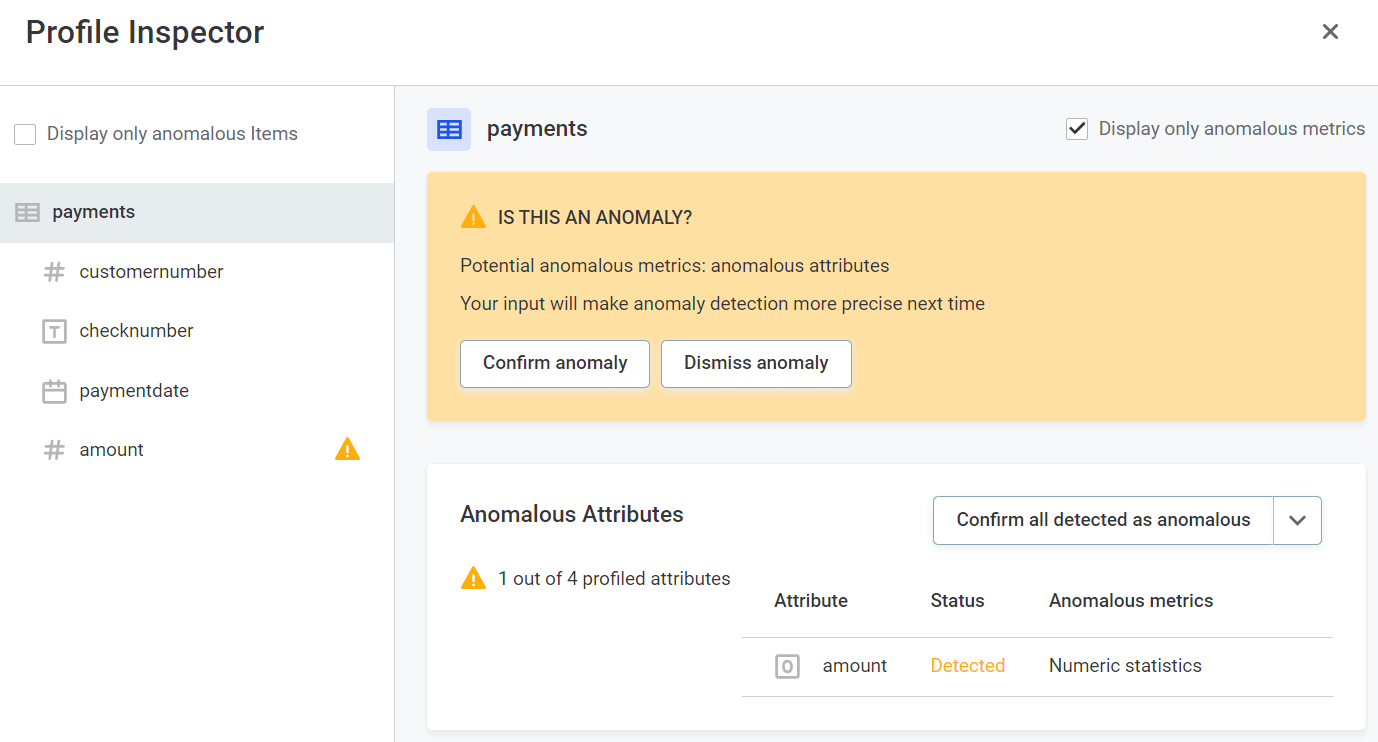
Structure checks
Structure checks are carried out alongside data quality evaluation in monitoring projects and data observability and alert you, for example, if columns are missing or the data type changes.
Data observability
The data observability feature in ONE allows you to monitor whole sources quickly and easily.
Connect your data source, and Ataccama ONE will automatically discover data domains. Select the domains you want to track, and Ataccama ONE will apply bundled DQ evaluation rules, detect anomalies, and monitor other changes, alerting you in case of issues.
For more information, see Data Observability.
Monitoring projects
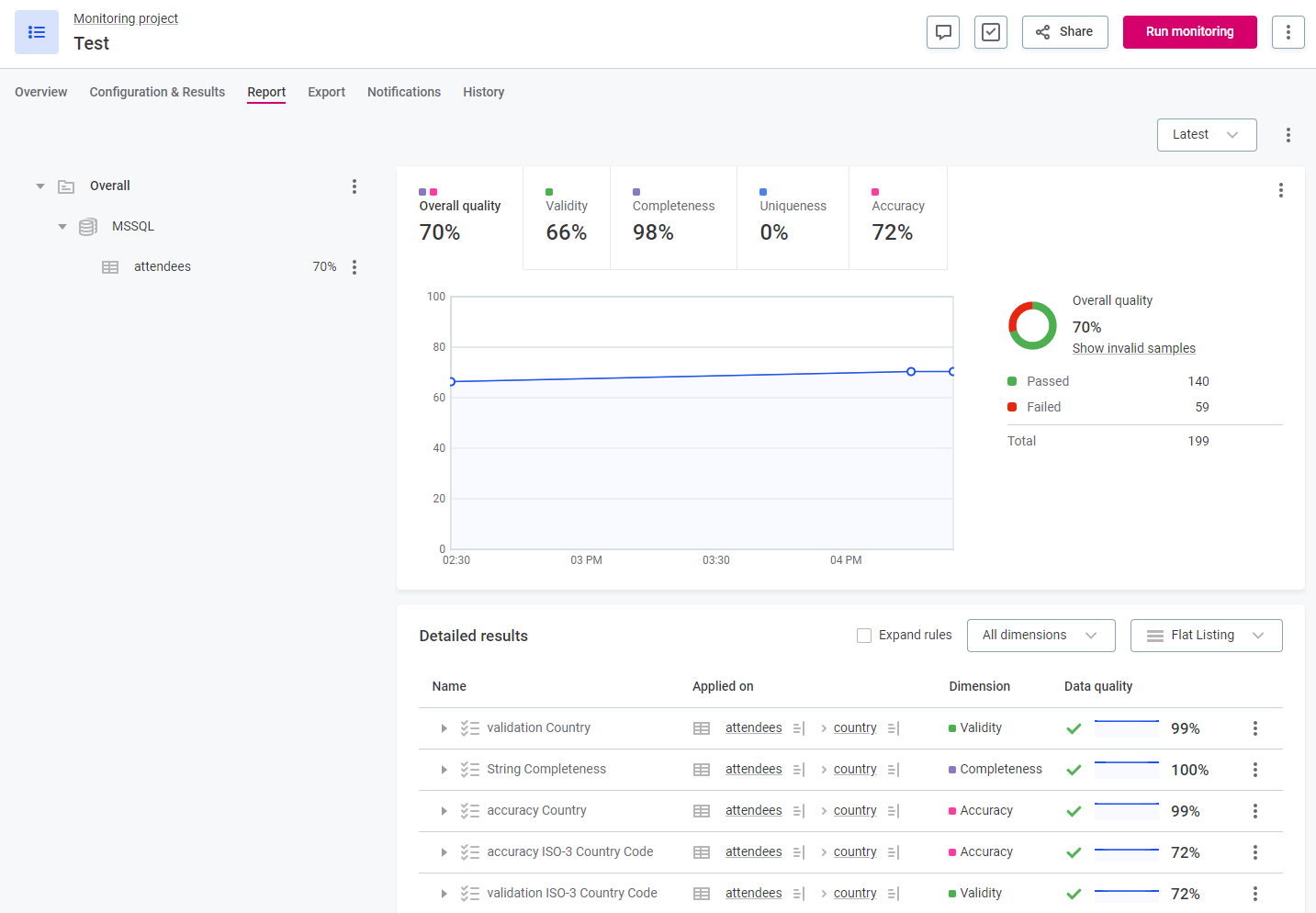
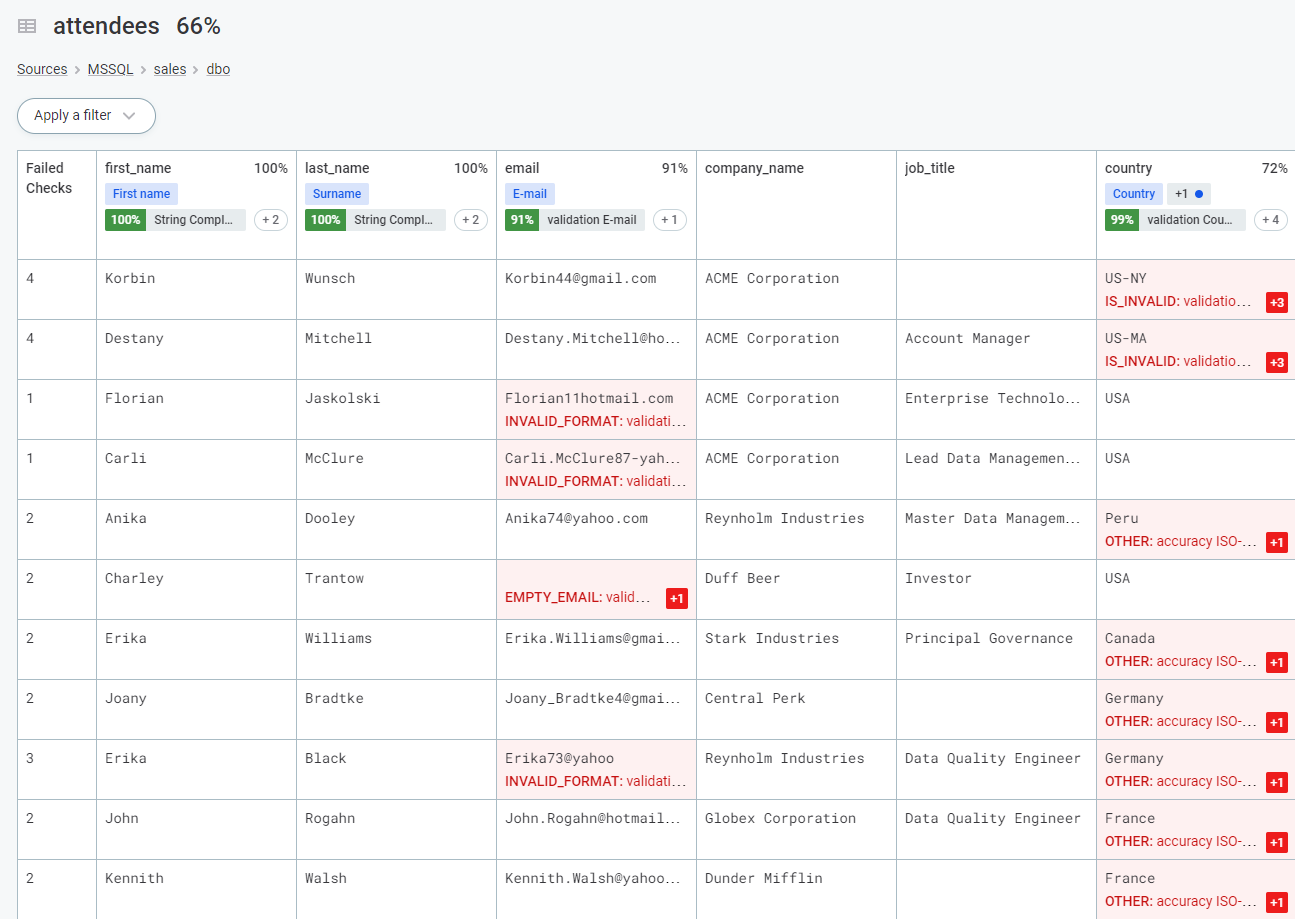
Monitoring projects allow you to select a number of key catalog items, apply rules, run both scheduled and ad hoc monitoring, and configure notifications for issues. DQ reports are generated with detailed results and invalid results samples.
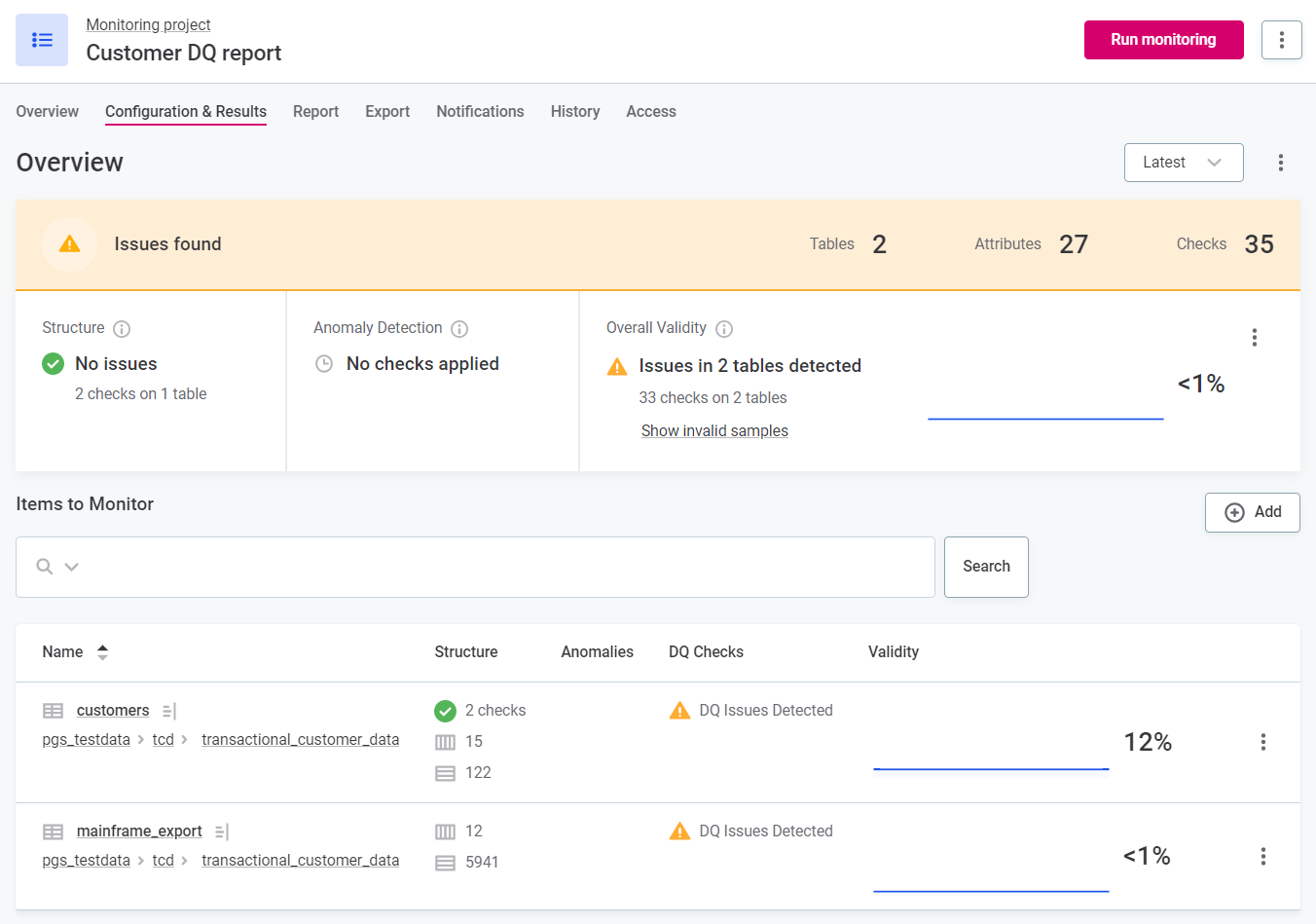
DQ reports
DQ reports are specific to monitoring projects. You can create filters for the reports, view results for individual DQ dimensions, and configure custom alerts for data issues.
Post-processing
Record-level data from monitoring projects is not stored. To store and further utilize monitoring project results, you need to define post-processing jobs.
There are three options available:
-
Transformation plans
-
Post-processing plans
-
Data remediation plans
For full details on all three plan types, see Monitoring Project Results Post-Processing.
All three plan types run with each run of the monitoring project. When post-processing options are defined, they can be found in the Export tab of the monitoring project.
Invalid samples
In monitoring projects and catalog items, you can see a sample of the data that failed the DQ rules. See Invalid Samples.
Additionally, load invalid records to ONE Data for data remediation. For more information, see Data Remediation with ONE Data.
Was this page useful?