
Run DPM Job
Starts processing of a plan or component using remote Data Processing Module (DPM).
Configuration parameters
| Name | Type | Description | ||
|---|---|---|---|---|
Main Plan |
mandatory |
Points to the main ONE plan that should be executed. |
||
Main Plan Path |
optional |
The path to the main plan at the remote site. If not defined, the local path is used by default. |
||
Runtime Configuration |
optional |
Points to the runtime configuration that should be applied. |
||
ONE Platform |
mandatory |
The name of your instance of ONE Platform. |
||
Priority |
optional |
Sets the priority of the job in the DPM job queue.
The default value is The higher the value, the higher the priority. |
||
Zip |
optional |
If set to |
||
Async |
optional |
If set to By default, jobs are executed synchronously ( |
||
Force Cluster Launch |
optional |
If set to |
||
Cluster Name |
optional |
The name of the Spark cluster on which the job should be executed.
|
||
Cluster User |
optional |
Sets the Spark cluster credentials. Used if the credentials are not provided in the default configuration or if you want to use another set of credentials. If Spark credentials are not provided, the authentication is skipped. |
||
Cluster Password |
optional |
Sets the password for the Spark user. If not provided, the password file is checked instead. |
||
Cluster Password File |
optional |
Points to the file that contains the password for the Spark cluster. |
||
Working Dir |
optional |
The absolute path of the working directory from which relative paths are computed.
If not set, it defaults to the current working folder.
If set to Must be defined as an absolute path. |
||
DPE Label |
optional |
Assigns Data Processing Engines (DPE) with the matching label to the DPM job. For more information, see Run task on selected DPEs. |
||
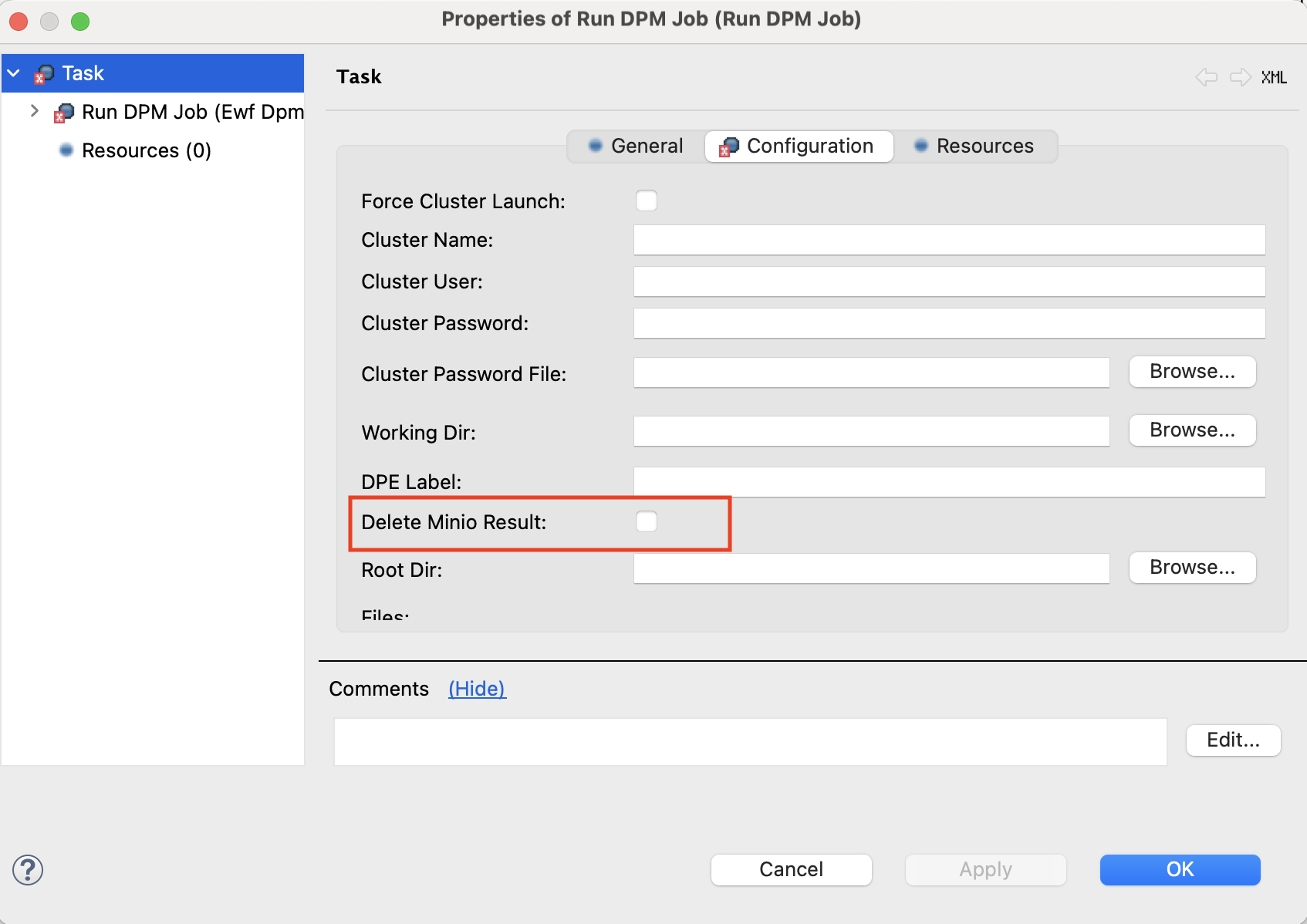
Delete Minio Result |
optional |
If configured, run results are deleted from ONE Object Storage (MinIO) after the plan finishes successfully. For more information, see Delete run results.
|
||
Root Dir |
optional |
For Unix-like paths, if not specified, the system default is used ( |
||
Files |
optional |
Points to additional input files, such as lookups, components, CSV files:
|
||
Links |
optional |
Points to files from ONE Object Storage. Consists of two values, the first one being the path that Executor uses when running the job, the second one a link that refers to the actual location of the file in the Object Storage. |
||
Path Vars |
optional |
Defines additional path variables.
For more information about workflow variables, see Expressions in Workflows.
Paths and other string values to files need to be enclosed in double quotes, for example: |
||
Parameters |
optional |
If using parametrized components, this is used to configure those parameters. Each parameter takes two values: a key and a value. |
||
Mount Drivers |
optional |
Used if the job needs access to a database.
DPM and DPE add this database driver into the runtime configuration, in the If a connection is already defined, it should point to the driver name ( |
Run task on selected DPEs
You can choose which Data Processing Engine should execute your job by configuring a DPE label for the task. This label is then matched against available DPEs, ensuring the job runs on the correct engine.
As such, defining which DPE is used for a job is particularly useful when you have multiple DPEs with different configurations, such as hybrid DPEs for accessing private data sources or DPEs optimized for performance.
Consider setting a DPE label in the following scenarios:
-
When your job requires access to confidential on-premise databases that are only accessible via a hybrid DPE within your private network.
-
When you are running resource-intensive jobs. In this case, you might want to run them on a DPE with higher resources available.
To set a DPE label for the Run DPM Job task, enter the name of the DPE you want to use in the DPE Label property.
If you do not set a DPE label, DPM uses the known capabilities of DPEs and evaluates them against the job requirements to determine which DPEs can run the job. DPM will automatically select an appropriate engine based on factors such as available resources and engine capabilities.
| For more information about how DPM selects engines, see Constraints Configuration. |
|
You can view and manage DPEs and their labels on the Configuration > DPE Configurations tab in the DPM Admin Console. This screen displays a list of labels and the configurations assigned to them. For more information, see DPM and DPE Configuration in DPM Admin Console. |
Was this page useful?