
MDM Model
Ataccama MDM follows a model-driven implementation, that is, the model is the most important part of the MDM, and everything is generated from it.
Some of the features of MDM are tightly related to the model:
-
Database structures are created automatically.
-
Cleansing, matching, and merging orchestration of the phases is handled automatically by MDM (MDM workflow).
-
Native MDM services are created based on the model.
-
Convention over configuration, removing complexity and supporting most processes by using the model information.
Overview
To support the modeling capabilities of the tool, Ataccama MDM includes a powerful modeling interface in which developers can define the whole data model from scratch. In the following diagram, you can see a representation of the MDM model project and its relationship with the rest of the elements of the MDM architecture.
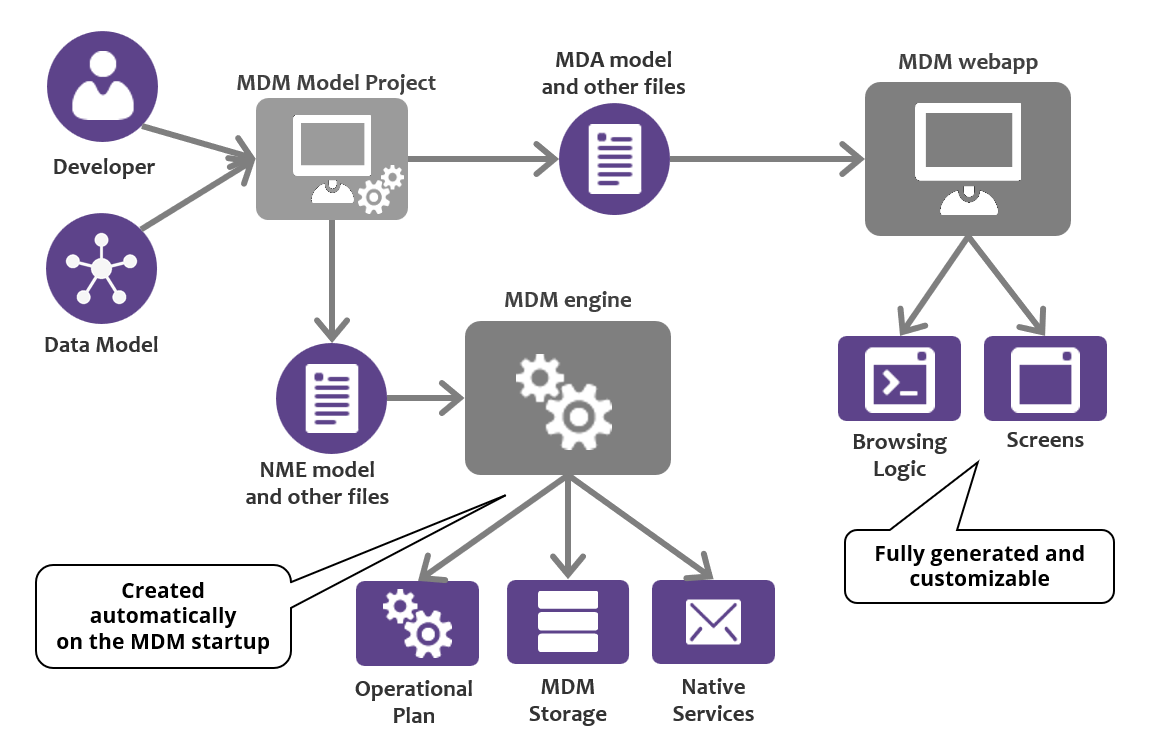
Ataccama MDM is driven by several data models, defined visually using a built-in case tool (master data, data sources, data consumers, input and output interfaces in general). Model metadata lives in MDM, thus making the model completely flexible and allowing developers to create entities and structures independently of the source system structures.
Models can be abstracted from the original data, defining the different entities that appear in the sources and the different relationships and dependencies that exist between the different entities. This also allows to create a common canonical model.
As the whole metadata layer is XML-based, MDM can import models from other case tools via standards for metadata exchange (XMI, XSD) and native formats (Power Designer, ERwin). MDM data models might also be imported from a database.
Importing models from external tools or database schemas supports incremental differences, allowing incremental imports, and selective imports based on the model (that is, importing only a subset of the entities or entity attributes available in the original model resource).
In Ataccama MDM, the model abstraction is split into the instance layer and master layers.
Instance
The instance model is devised to accommodate all the instances coming from the source data, that is, there is a one-to-one relationship between source records and records in the instance layer.
The instance layer should also be wider than any particular source of data as it needs to fit all possible structures. This is done through a Canonical model that does not relate to any particular source but instead has the attributes to accommodate all of the different structures.
The instance model represents not only source data but also the cleansed form of each record. Model relationships are also imported from relationships in the source data. This has some implications in terms of features and the data available to different records through their relationships.
Hence, the instance layer serves the following purposes:
-
Creates a structure to accommodate all the different attributes from sources.
-
Defines a target structure for the cleansing phase.
-
Hosts all metadata related to the matching process.
-
Defines attributes that are imported from other entities through their relationships. This advanced feature is meant to help during the matching process of a given entity by using attributes from other entities as additional information.
-
Maintains all source records and their cleansed forms, accepting updates and allowing redistribution and export of cleansed instance records.
Master
The master layer is composed of models that represent entities after the matching and merging MDM phases have taken place and relationships between them and across layers (with the instance layer).
The master model represents the model generated after cleansing, matching, and merging, the resulting entities, and their sets of attributes, together with relationships between them and across layers (with the instance layer). Relationships are mandatory and are based on the initial model, and their master relationships are derived from the results of the previous matching process.
Ataccama MDM supports multiple master layers, that is, different domain views created with different structures, relationships, and attributes.
Hence, the master layer, together with each of the defined (multiple) models, achieves the following:
-
Unifies all source data after the MDM phases (cleansing, matching, merging) into one common master structure.
-
Defines which instance records correspond to each master record (either golden records or deduplicated instances).
-
Defines entities that are matched as either deduplicated or unified based on matching rules (golden records).
-
Defines all relationships between master entities created in the model (enforced by MDM automatically). Relationships help several services to retrieve data, for example, Traversal services.
-
Creates the base layer for the MDM Web App to interact with master data.
-
Defines relationships across layers, that is, master to instance entity relationships.
Physical
The physical layer of the MDM repository is represented by a unique table at the instance level for each entity, and another table for each entity that has been mastered (matched and merged).
As seen in the following diagram, the physical layer has a different disposition that relates to logical layers. All tables are created based on the model.
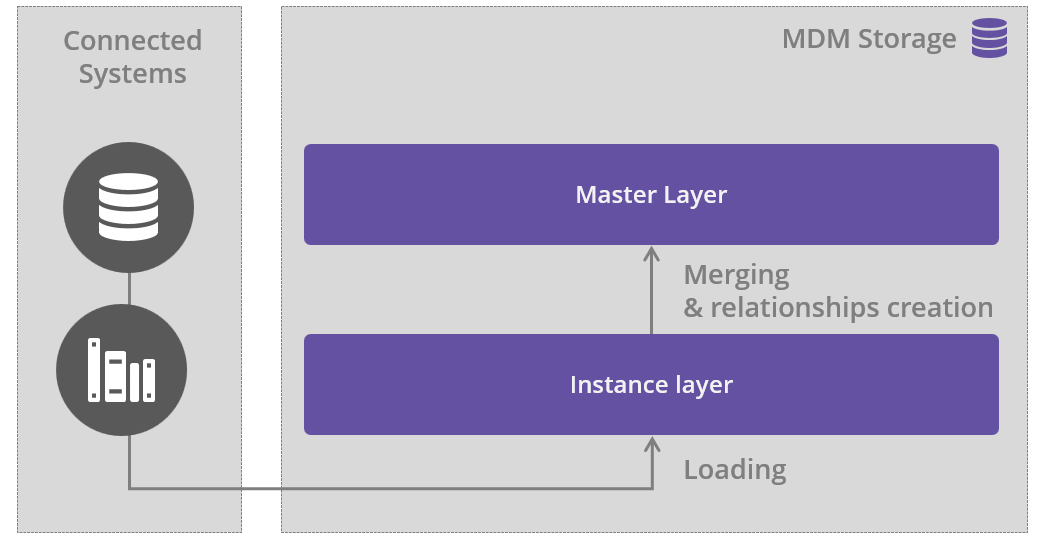
The following section describes how the physical layers correspond to logical ones.
In addition, the physical layer offers other features:
-
Records are maintained as logical deletes (that is, inactive records are supported through status flags).
-
Historical tables for selected entities can be activated, thus storing history following a SCD4 approach.
Logical
The following diagram represents the logical layers within the two physical layers. The Mixed style option of writing directly to a master layer is not shown here.
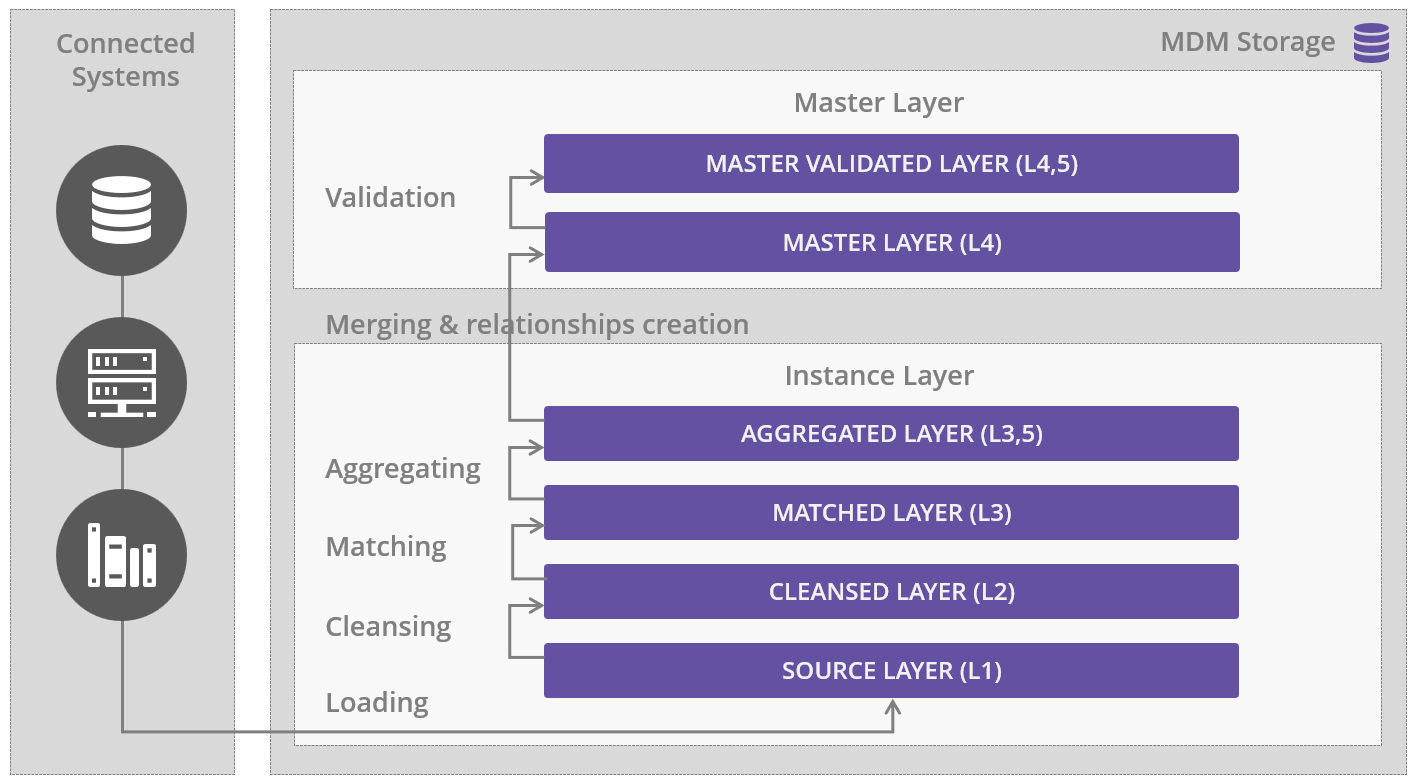
For the physical instance layer, there are four different logical layers in each entity table.
-
L1: Stores the source data. The fields in this layer are the ones defined in the canonical structure devised to fit all heterogeneous structures from disparate connected systems.
The canonical layer is a feature of L1 that stands before the source data accommodation into the model. The canonical layer defines a common model to fit all different heterogeneous structures from the source data and, optionally, stores the source data from the connected systems. -
L2: Stores cleansed data, that is, the fields that have been defined as target attributes for the Cleanse MDM phase. These fields include not only standardized or cleansed attributes but also the metadata related to the process of cleansing (for example, scores and explanations).
-
L3: A virtual layer that defines metadata related to the process of matching. These values are only defined for those entities that are selected for the matching process (and the subsequent merging process).
-
L3.5: A layer that allows to aggregate records being processed by a selected attribute. It is defined for those entities where the process is enabled.
For the physical master data layer, there is only one table per entity that corresponds to the logical layer one-to-one. If multiple master views are defined, then multiple master tables exist.
-
L4: A layer that stores all the master data, that is, the merged results from matching. The physical layer stores relationship keys, the master data itself for both mastered entities and deduplicated entities.
-
L4.5: A layer that stores the validation scores and explanation codes for all master data. Scoring and explanation data is translated into validation messages, data quality grades, and attribute validation severity grades in the MDM Web App.
When master matching-configured MDM allows writing data to the Master Layer (L4) and getting data validated (L4.5), matching rules are reused as follows:
-
For Master Identify service to prevent creating duplicates.
-
For Master Matching to guarantee you are aware of any duplicates created on a master layer.
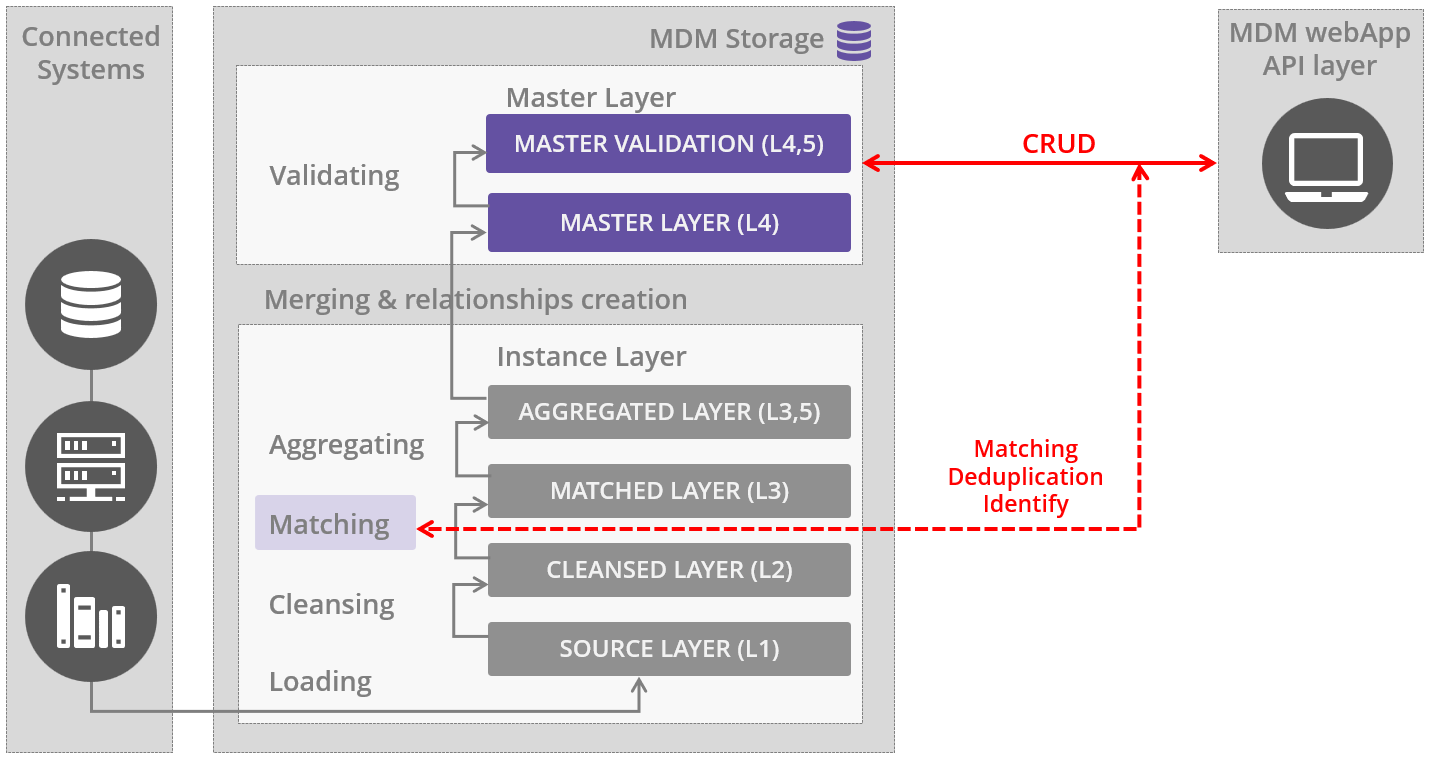
| When authoring data on Master layer and data consolidation on Instance layers are used together, we refer to this as the Mixed style. |
Configuration
Apart from the data models (entities and relations), other related tasks need to be configured in the MDM project:
-
Connected systems definitions.
-
Cleansing rules.
-
Validation rules.
-
Match rules.
-
Aggregation logic.
-
Merge rules.
-
Services provided to the connected systems, such as exports, Event handler, and Publishers.
-
Additional features, such as reprocessing for selected data.
-
Level of auditing (both business and technical level), context-dependent authorizations based on consolidated consents and user perspective.
-
MDM Web App, if used.
Developers can also configure the GUI model for access via the MDM Web App (see MDM Web Application Configuration). Configuring GUI views is fully flexible, making them abstracted from the actual MDM models defined. The GUI model also supports role-based access to the data.
Transformation (MDM phases)
The MDM process is divided into three well-defined phases. MDM is in charge of orchestrating and maintaining the flow of data between the phases, removing the need for configuration. The diagram illustrates the order of MDM phases in the context of MDM processing.
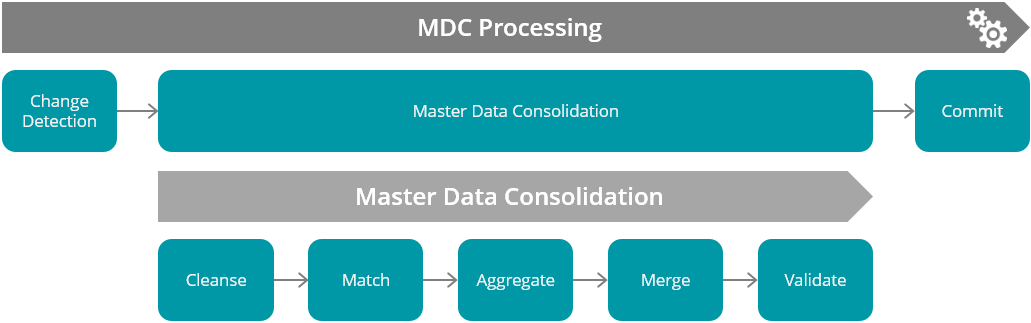
Cleansing
MDM comes with a powerful expression engine for data quality, with a great array of prebuilt operations and functions that can be easily extended. MDM also includes the ability to create powerful, high-performance dictionaries for data validation and enrichment, which in addition serve the purpose of detaching implementation logic from reference data.
Any functionality can be packaged in a modular component and reused, centralizing logic, fostering sharing, and creating DQ services from these components.
Matching
MDM includes a state-of-the-art, high-performance rule-based matching engine, which supports multiple strategies for matching, combination for matching operations for more refined results, and scoring-based rule matching.
Matching repositories for incremental matching are created automatically, and the engine also supports ID generation and configurable ID stability for supporting key business processes.
MDM can match entities on different levels as MDM supports multiple mastering layers (also called domain views).
Aggregating
An optional layer, aggregation enables calculating aggregate values, like counts, sums, median values, and even concatenations, on records grouped by a selected attribute, for example, master_id, phone number.
The aggregated values can then be propagated to one or multiple master layers and viewed in MDM Web App.
Aggregation can be performed even when the processing is incremental. This means that the aggregation layer ensures the whole group (based on the aggregation definition) of records is available for each record that is processed (sent on MDM input).
Aggregation can be performed even if cleansing and matching are skipped.
Merging
MDM includes a high-performance merging operation used in combination with the metadata generated from the matching. Merging is rule-based, which provides great flexibility when selecting the data to be included in the golden record. Data can be divided into blocks (with one or more attributes), and particular rules can be defined for each block.
Online service interfaces
Based on the model, Ataccama MDM generates a set of native MDM services. They are SOAP or XML services with the most common operations for accessing hub data (MDM repository) and can be easy combined into more complex services using an ESB.
The online interface also supports data queries for accessing hub data from other applications. MDM provides list SOAP master data services that interact with the MDM repository. These native out-of-the-box MDM services are defined automatically based on the model.
Any native service can be activated or disabled on command. The service definitions are contained in a single configuration file that Ataccama MDM server must be able to access.
Was this page useful?