
Metadata Concepts
In this section, we are going to explore concepts and differences between metadata, metadata model, and meta-metadata.
Metadata (MD)
Metadata (also known as MD) is used to describe the data. It can be shape of the data (that is, how many columns there is in a table) and additional descriptions of the data (that is, what is in the table - people data, product data, etc).
Let’s imagine we have the following example table (with many records):
| Name | Phone | |
|---|---|---|
John Smith |
(678) 321 7688 |
|
Jane Willson |
(678) 234 3321 |
|
… |
… |
… |
Metadata for this table would look similar to the following code example:
{
TableName: "PeopleTable",
Columns: [
{columnName: "Name", type: "string", description: "name of the person"},
{columnName: "Phone", type: "string", description: "phone of the person"},
{columnName: "E-mail", type: "string", description: "electronic mailing address"}
]
}As you can see, our metadata describes the table, along with some additional information. It is what catalog uses to display the main layout of the table.
Additionally, you can have metadata associated with data assets that goes beyond the simple description such as:
-
Relations to another tables and metadata assets.
-
Business descriptions.
-
Owners of the data.
-
Lineage information (where the data is coming from).
-
Data quality and monitoring information (how good the data in the table is).
-
Sums and duplicates counts (that is, profiling information).
-
Computed information (that is, how many columns there are in the table).
As you can see, we can add lots of useful information to the data that helps us get a better idea of what we are working with when we actually need to use the data.
Metadata swamp
Similarly to data swamps, which are the result of introducing a lot of unorganized data to your data lake without proper metadata management on top of it, metadata can suffer from similar issues. In other words, while you might have lots of (metadata)data, it is not useful when you do not know what is in it and where it is, despite having a lot of data available.
Let’s look at an example with the following directive: For regulation purposes, we need to have "data owner" assigned to every table.
Assume we are already working with these tables:
-
PeopleTable -
ProductsTable -
CountryNames -
Addresses
Now, let’s see what could happen if we request adding another "data Owner" table.
Since PeopleTable and ProductsTable` are in a different system than CountryNames and Addresses, they are managed by different parts of the company.
Additionally, organizations are often working with thousands of tables, and such a task cannot be carried out by a single person or a team.
So the first team that starts adding information might do it in this form:
{
TableName: "PeopleTable",
Owner: "John Smith"
},
{
TableName: "ProductsTable",
Owner: "James Taylor"
}And then the second team uses this format:
{
TableName: "CountryNames",
DataOwner: "John Smith"
},
{
TableName: "Addresses",
DataOwner: "Jackie Holmes"
}Notice that the teams are using different attributes for the same type of information, Owner and DataOwner.
This makes future changes more difficult as, in case an employee leaves the organization and we need to reassign all of their tables to someone else, we would have to search by both attributes (or more) to find all relevant tables.
If you have only free-form metadata and a large organization, you could potentially have hundreds of variations of every attribute.
To prevent such situations, you need to have a system that tells all the departments of the organization not only that they need to add the DataOwner attribute, but also what are the name, formatting, position, and even security settings of that attribute.
To do this, you need meta-metadata and a meta-metadata model.
Meta-metadata (MMD)
Meta-metadata describes the shape of your metadata: names, position, formatting, and cardinality of your metadata attributes.
Let’s take the metadata about a table from our previous example:
{
TableName: "PeopleTable",
Columns: [
{columnName: "Name", type: "string", description: "name of the person"},
{columnName: "Phone", type: "string", description: "phone of the person"},
{columnName: "E-mail", type: "string", description: "electronic mailing address"}
]
}The meta-metadata describing the structure of such metadata can look like this:
{
EntityName: "tableEntity"
Attributes: [
{attributeName: "TableName", attributeType: "string"},
{attributeName: "Columns", attributeType: "array", arrayStructure: ["columnName", "type", "description"]}
]
}While this is a very simplified example, in general we can assume that where metadata equals content, meta-metadata equals shape.
How to add metadata without creating a swamp
When our metadata shapes are properly described in meta-metadata, then we can avoid mistakes from our previous example. Let’s imagine the same scenario (directive: For regulation purposes, we need to have "data owner" assigned to every table), only operating in an MMD system.
In that case, we would first add this attribute to our meta-metadata for this attribute to be available to all the relevant teams. Doing this prevents the teams from introducing arbitrarily named attributes.
So we update our meta-metadata with the new DataOwner attribute:
{
EntityName: "tableEntity"
Attributes: [
{attributeName: "TableName", attributeType: "string"},
{attributeName: "DataOwner", attributeType: "string"},
{attributeName: "Columns", attributeType: "array", arrayStructure: ["columnName", "type", "description"]}
]
}This way, we are telling our teams what the name of the attribute is and what they should use:
{
TableName: "PeopleTable",
DataOwner: "John Smith"
},
{
TableName: "ProductsTable",
DataOwner: "James Taylor"
},
{
TableName: "CountryNames",
DataOwner: "John Smith"
},
{
TableName: "Addresses",
DataOwner: "Jackie Holmes"
}As a result, we have much more searchable metadata and can be certain that all the relevant data is found when we search using this single attribute. In other words, having correctly defined meta-metadata is the key to a successful metadata management strategy.
Advanced meta-metadata and meta models
The example we used across this article is rather basic and doesn’t convey the complexity of metadata in large organizations, which includes cross references, repeating parts, embedded structures, computed content, and more.
Such organizations require meta-models, which are the definitions of all metadata structures in the organization (or at least in one department). This means all the meta-metadata is collected in a single place, but more importantly, it also allows you to establish different types of relationships between various parts of meta-metadata.
Let’s look at another example:
-
We have multiple Databases and File storages in the organization.
-
Each file storage and database contains multiple Tables.
-
Each database has an Admin (User).
-
Each table has an Owner (User).
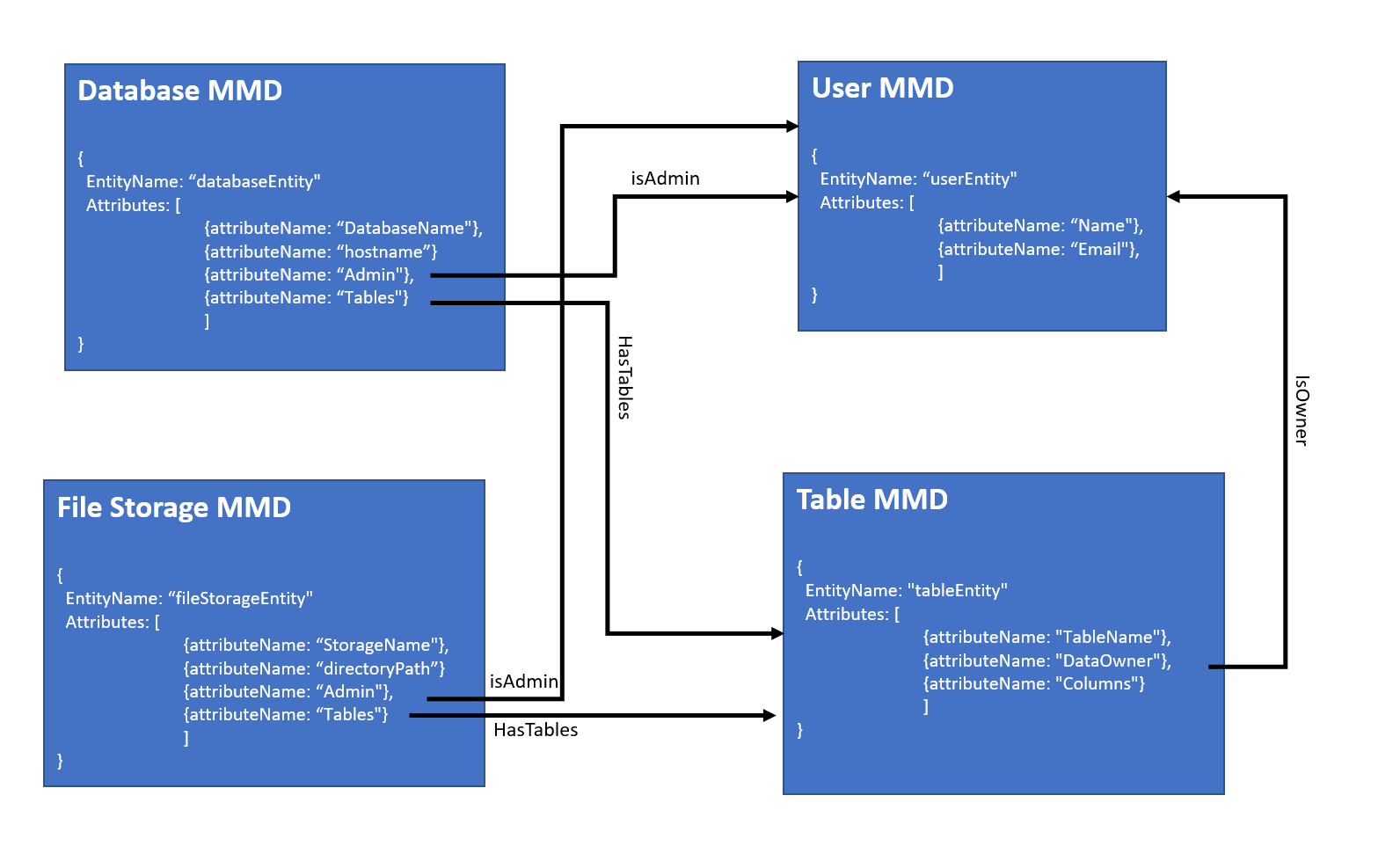
As you can see, what we are creating is essentially a model that describes meta-metadata and the relations between different meta-metadata nodes or entities.
Meta-metadata driven applications
Certain applications (such as ONE) can use these MMD models to create the user interface. In this case, what you see when you log in and are, for example, creating a new database is the form that lets you fill in the attributes (name, hostname) and choose referenced attributes (select a user from the list of users) and then add embedded attributes (each table has its structure defined in the table meta-metadata).
The key here is to keep the application flexible, so that when we change the meta-meta model (for example, we add a DataSteward attribute), the user interface reflects this change and adds the data steward field to the form that users can later fill in.
Such applications are called metadata- or meta-metadata-driven.
Was this page useful?