
Matching Step
The matching step finds records that refer to the same party, product, mailing address and so on. This guide gives you an overview of matching concepts and matching step configuration.
Useful Terms
Partitions
A partition is the first division of records in the matching step. There may be one or more partitions. A partition can contain all records in the data flow. Records from partition A can only be matched to records in Partition A. They are evaluated from top to bottom and if no expression is given for it, TRUE is implied. If a use-case requires the use of the TRUE condition (matching without partitioning), that partition should be last in the list of key rules.
Key Rules
Key rules are used to make key groups. Key groups are divisions within partitions. If a record links two groups, they are unified and assigned the same master ID. Key Groups consist of records whose Component columns match.
Matching Rules
Matching rules are the reason for group creation. Each Key Group can have multiple Matching Rules. Matching Groups are made by Matching Rules. One Matching Group can be made of several Matching Rules:
-
Records A, B and C all belong to the same Key Group.
-
A and B were grouped together by Rule 1.
-
A and C were grouped together by Rule 2.
-
Due to this, they all belong to the same Matching Group.
Tests
Tests are quantifiable checks to determine whether two records match. They are defined in the Match Functions section of the Matching Step. Match Functions use 'x' and 'y' to represent the attributes being tested. 'x' is the tested attribute from one record while 'y' is the attribute from the other record. Tests work in conjunction with Matching Rules. For 2 records to match, they must be connected by a matching rule and pass all tests.
ID Keeper Record
During matching, the records in a matching group are constantly rearranged due to the addition or deletion of records, as well as change of record keys or other attributes. The Matching Step tries to keep already used group IDs as much as possible. Only one record of each group is called the Merge survivor, or in other words, the carrier of the group ID - this is the ID Keeper Record.
Constraint Rules
Constraint rules can be used to prevent records from being matched to the same Matching Group (if a certain condition is met) which would otherwise be matched based on Key Rules and Matching Rules.
When an attribute is used as a Constraint Rule, all records in one Matching Group must have the same value in that attribute (or null values in that attribute). In other words, records that differ in the Constraint Rule value are divided out into different Matching Groups regardless of the Key and Matching Rules.
Records with null Constraint Rule value are match to any other record with null or non-null Constraint Rule value if Key Rules and Matching Rules tests and conditions are satisfied.
Proposal Rules
Records that match based on the configured proposal rules are sent through the matching step’s optional output. They are often integrated with MDM Web App for use as records to be manually matched by data stewards.
Isolate Flag
Isolate flag is a binary column, which if True means the record will not match with any others in any case.
Matching Step Concepts
This section gives an overview of the matching step and how it works. In the matching step, data is divided into partitions. Then, each partition is divided into Key Rules groups. Finally, each Key Rule group is divided into Matching groups. Records which belong to the same Matching groups are considered to be the same, for example, the same person, the same product, the same address, etc.
Partitions
Data enters the Matching Step and is divided into user-defined Partitions. Partitions allow user to split the input records into different groups of records which should not be matched together: typically for splitting a Party entity into records representing persons and companies. A record can only be matched to another record if both records are in the same partition.
Records are put in partitions sequentially:
-
If a record does not belong in the first partition, it us then checked to see if it fits in the second.
-
If it does not fit in the second partition, it is checked to see if it fits in the third.
-
This process repeats. If it fits into no partition, it is not matched.
-
Records that do not belong in any partition are never matched.
Key Rules
Within a partition, there are one or many Key Rules. Key rules are made up of Key Components, which are references to fields in the input data. If records have matching values in their Key Components, they are put into the same Key Rule group.
Records are put in the Key Rule groups sequentially:
-
If a record does not belong in the first Key Rule, it is checked to see if it fits in the second.
A record can belong to two Key Rule groups if it satisfies both Key Components. If a record belongs in the first Key Rule group it is checked against, it still continues to be checked against further groups. In the instance that it belongs to more than one group, these groups are linked. -
If it does not fit in the second, it is checked to see if it fits in the third.
-
This process repeats. If it does not fit into any Key Rule, it is not matched.
Matching Rules
The first record in the first Key Rule group becomes the pivot record. The second becomes the candidate record. The pivot and candidate roles are used by Matching Rules to match records together.
The Matching Rule used to match a pivot and candidate together is checked sequentially:
-
If a record does not belong in the first Matching rule, it is then checked to see if it fits in the second.
-
If it does not fit in the second Matching Rule, it is checked to see if it fits in the third.
-
This process repeats. If it fits no matching rule, it is not matched.
Once a pivot and candidate have checked all Matching Rules, the candidate role is changed to the next record in the Key Rule group. Finally, Proposal Rules are run on the leftover, unmatched records. These proposed matches exit via the Matching Step’s Proposals output.
The Matching Step Concept Example
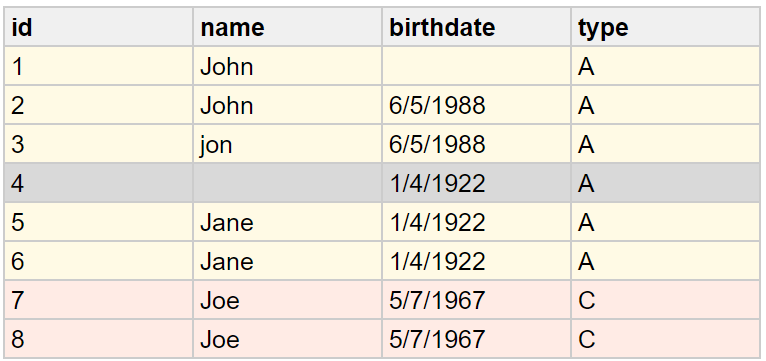
In this example, one partition is defined. Records with non-null names (highlighted) are put into the partition.
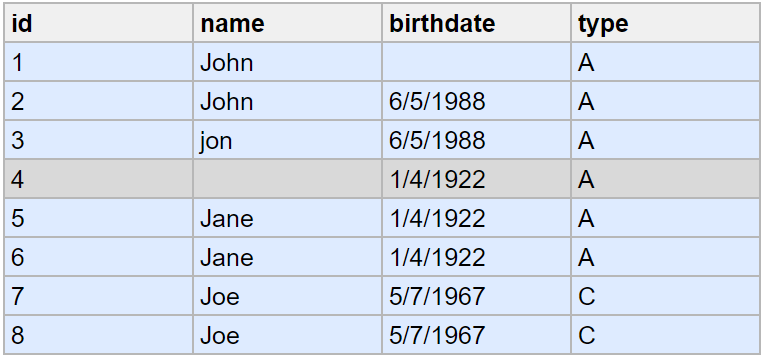
Records highlighted with the same color have been put in the same Key Rule group.
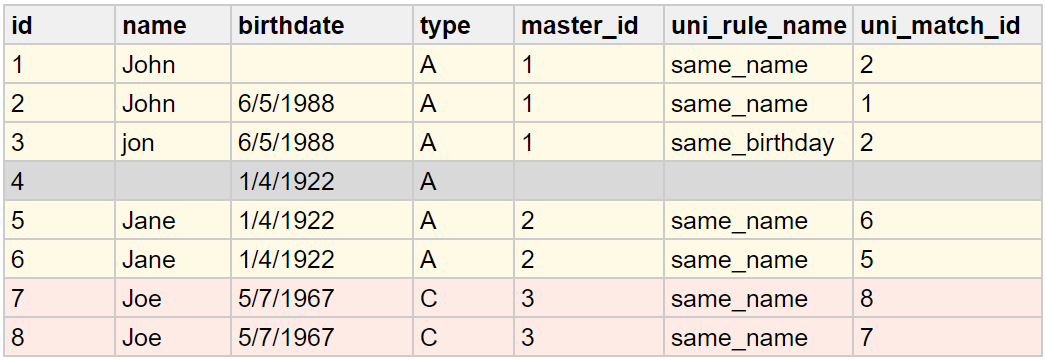
The following table shows the result of the matching:
-
master_id: The group the record belongs to.
-
uni_rule_name: The name of the Matching Rule used to match this record.
-
uni_match_id: The identifier of the record this record was matched to.
Matching Step Configuration
The following section details the configuration of the matching step. It assumes knowledge of what your matching rules are. To get started, double-click the matching step in your plan while in ONE Desktop.
Column Mappings
Details
| Column mapping is necessary only when the matching step is used outside of MDM. |
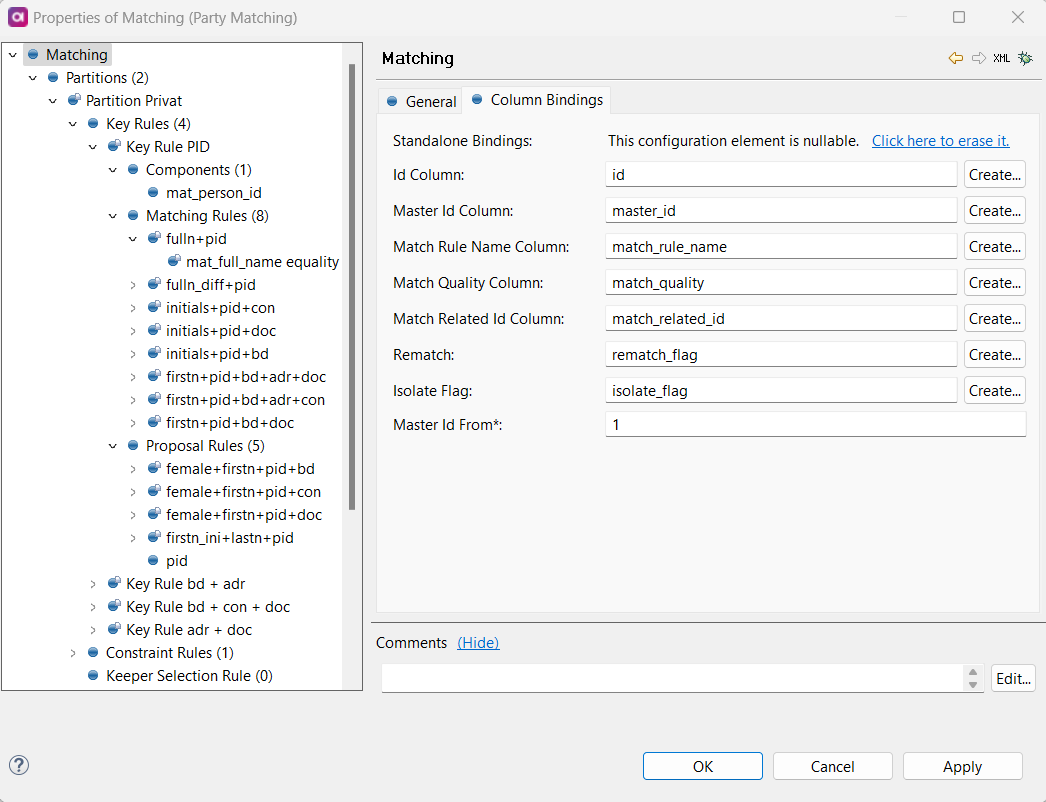
Navigate to Standalone Bindings on the left-hand menu of the Matching Step configuration. If you are matching outside of a complete MDM project, you need to map at least the Master Id Column. Otherwise` java.lang.IllegalStateException: Persistence` is not set (which means the standalone mode may not be configured).
| Parameter | Description |
|---|---|
Id Column |
The column containing the unique id for all records. |
Master Id Column |
The column where the id for matching groups is stored. |
Match Rule Name Column |
The column where the name of the first successful matching rule is stored. |
Match Quality Column |
The column where the strength of the match is stored (a number between 0 and 1, where 0 is a perfect match). |
Match Related Id Column |
The column where the id of the record to which a record was matched to is stored. |
Rematch |
The column in which the Boolean value for rematchis stored. Records with rematch flag set to true are included in the next rematch operation. |
Isolate flag |
The column in which the Boolean value for isolate is stored. Records with isolate flag set to true do not take part in matching. |
Master Id From |
The minimal master id assigned to new groups (default value is 1). |
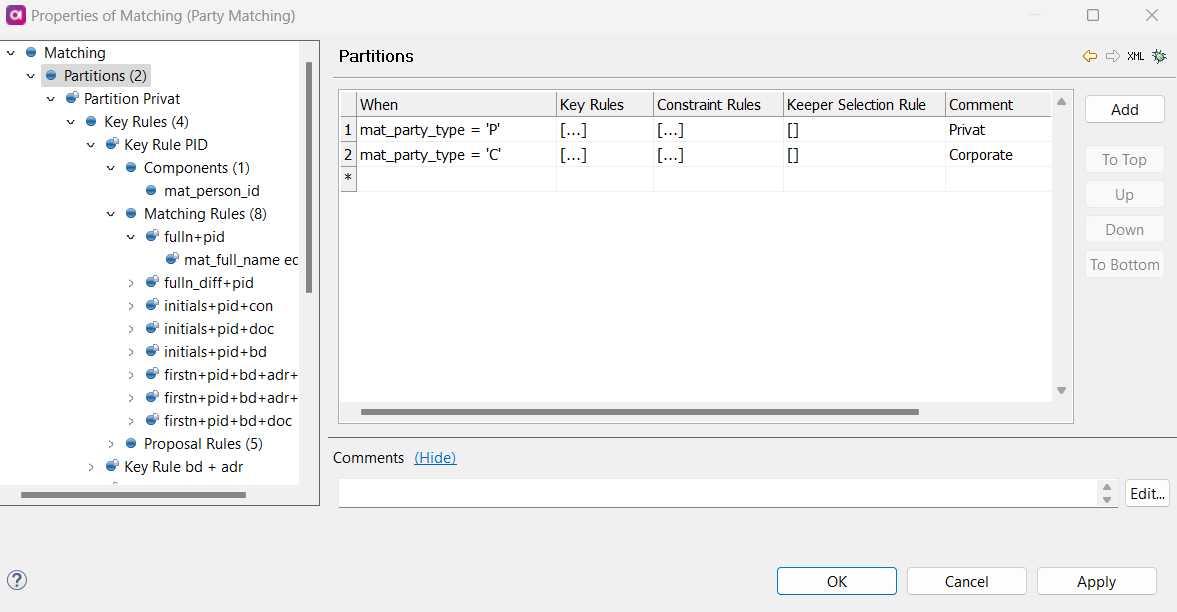
Partitions
In the left navigation menu, select Partitions.
Define your partitions expressions: records that match one expression are put into one partition.
If only a single partition is required, you can make one partition whose expression is true.
The order of the partitions matters - if a record can go into many partitions, it goes into the first eligible candidate in the list.
Leftover records are not matched.
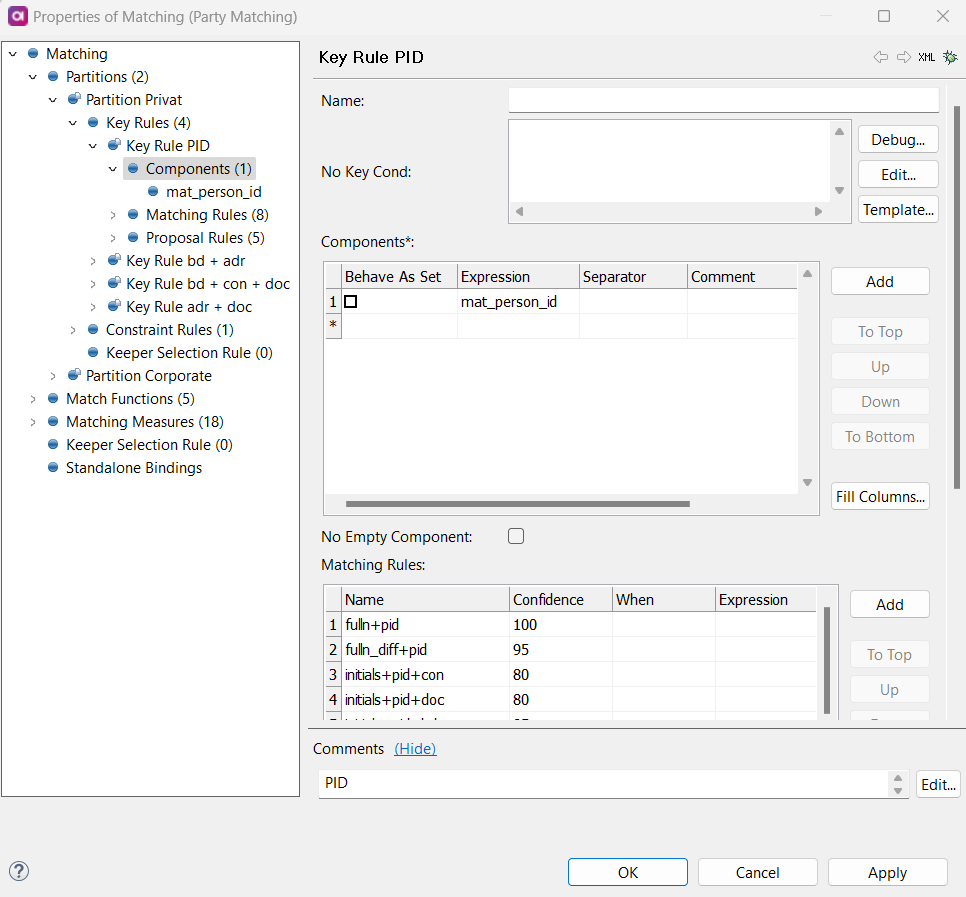
Key Rules
Key Rules are stored inside each partition.
To configure key rules, define the following:
* Name: The name of the rule.
* No Key Cond: If a record follows this condition, it is not put into a key rule group.
* Components: The fields in the data that are included into the rule.
Records with identical key rule components are put into the same key rule group.
Behave as Set: If checked, the component value is assumed as a list of string values.
If two sets have at least one intersecting value, then they are considered identical (for the purpose of key group components).
Separator: Characters used as word separator when Behave as Set is checked.
The default separator is one space.
* *Expression: Expression calculating one key component value.
Non-string values are converted into string.
* No Empty Component: If checked, all components have to be valid (non-null) to conform a valid key.
If not checked and at least one component is non-null, the key is valid and will be used.
* Matching Rules: It is possible to configure one or many matching rules within each key rule.
If no matching rules are defined for a key rule, then records put into that key rule are all considered matched, and all receive the same master_id.
The order of key rules matters: if a record can go into many key rule groups, it goes into the first eligible candidate in the list.
To know more about configuring matching rules, see [Matching rules].
Matching Rules
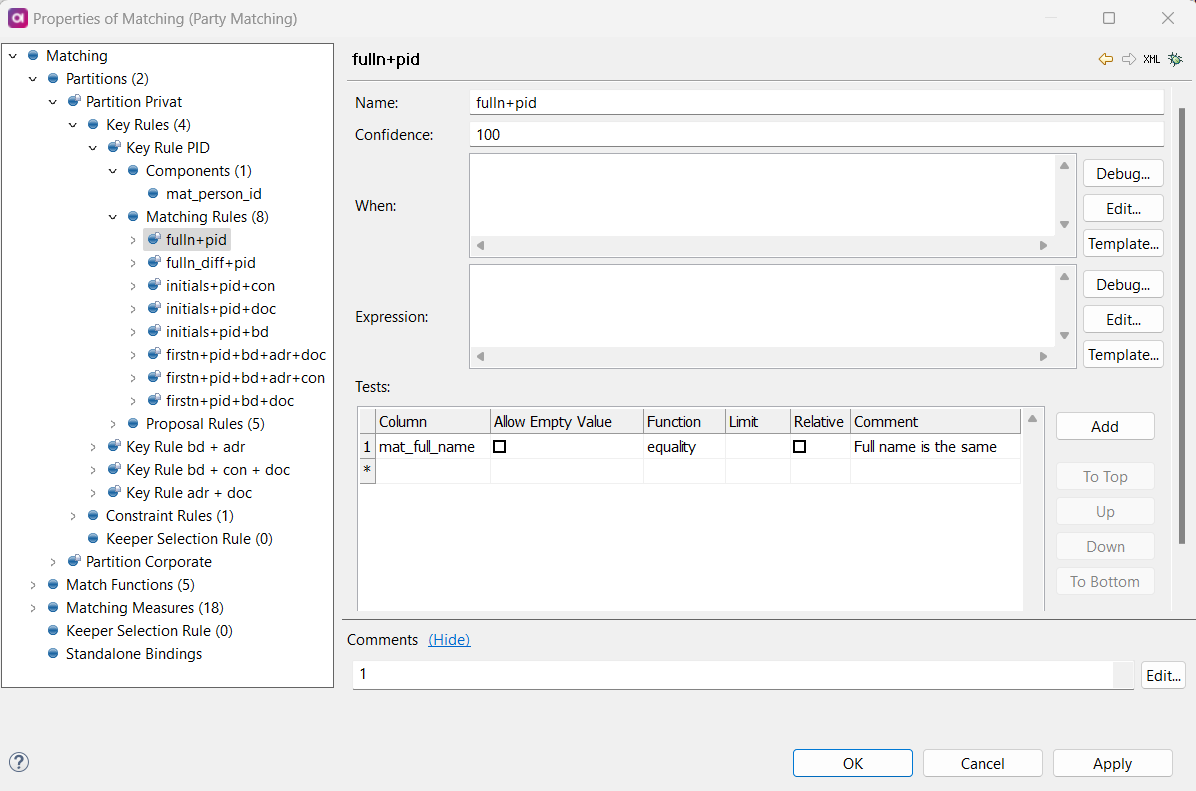
Matching rules determine which records are finally matched together by the step. The order of matching rules matters: if a record can go into many matching rule groups, it goes into the first eligible candidate in your list.
To configure matching rules, define the following:
-
Name: The name of the matching rule, that is displayed in the output Rule Name Column.
-
Confidence: The level of confidence that you define for a particular rule. It is stored for the matched records and displayed in the MDM Web App (to learn more about accessing matching proposals, see Matching Proposals). Possible values are 0-100.
Confidence defined in this step does not affect the matching algorithm and rules priority. -
When: The condition that needs to be true for this rule to be applied. Use if you only want to use a matching rule on records that follow a certain condition.
-
Expression: An expression that needs to be fulfilled for the input records to be matched together. Both expression and all matching tests must be complied with. Whenever a matching rule is tested, it considers two records at a time. One of the records is called the pivot and the other the candidate. To reference the columns in these records, we use
pivot.column_nameandcandidate.column_namein this expression box. -
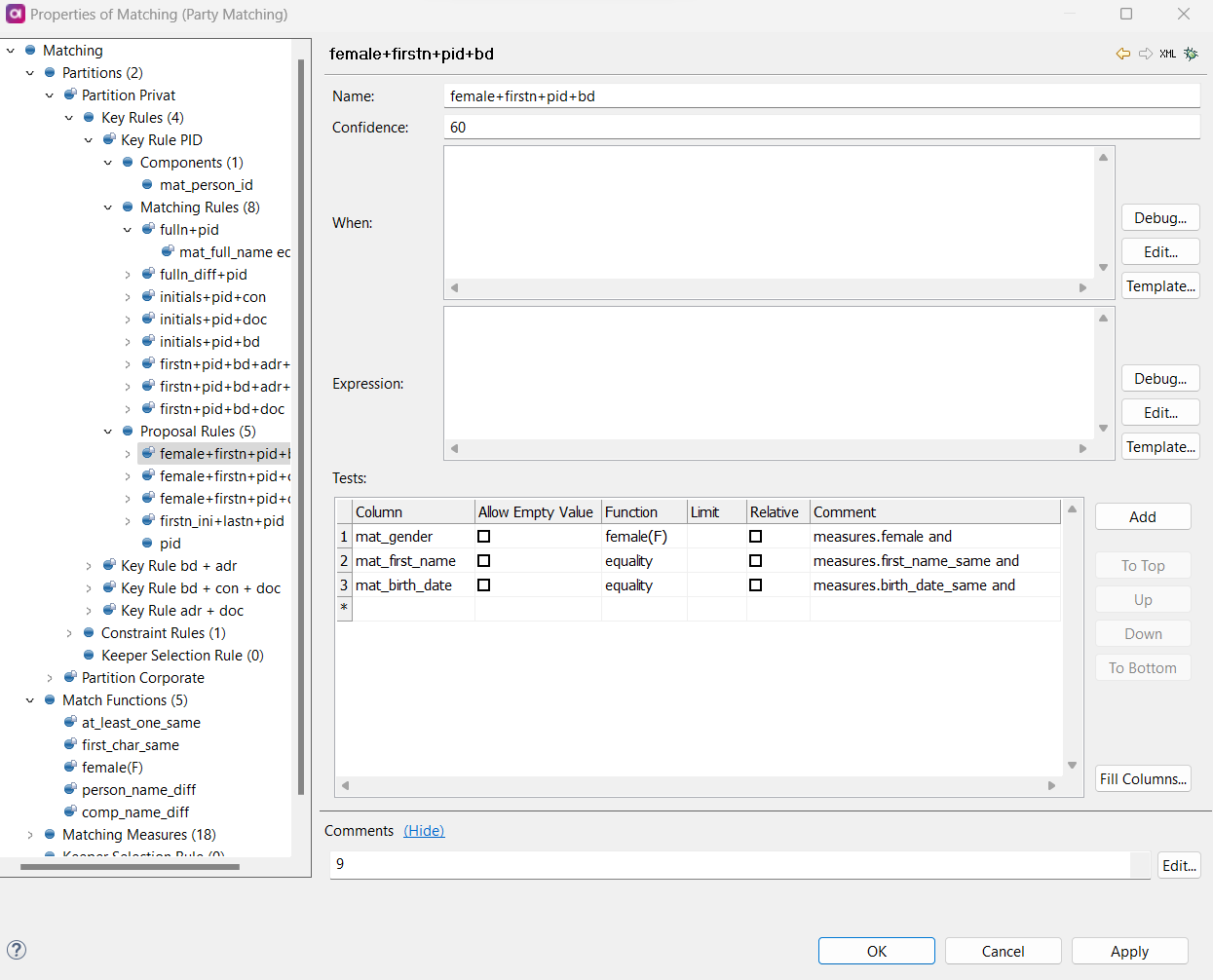
Tests:
-
Column: The column that contains the value to be compared.
-
Allow Empty Value: If checked,
nullvalues are used in the test. If unchecked, the test fails whennullis used in the test. -
Function: The function used to evaluate the distance between records. Choose from predefined functions (for example, equality) and functions defined in Match Function.
-
Limit: The maximum value returned by the function for the test to be fulfilled. If the result of one test goes above the limit, the matching rule is not passed regardless of other tests and expressions.
-
Relative: Specifies whether the returned value of the function should be divided by the longer of the compared values.
-
Was this page useful?