
ONE Expressions Handbook
This guide describes how Ataccama ONE expressions are used throughout the platform for rules, data transformations, and more, and provides immediate practical guidance for using expressions.
What are ONE expressions?
ONE expressions are formulas that let you create validation conditions and transformations throughout the Ataccama platform.
Expressions are built using functions - pre-defined operations that perform specific tasks like manipulating text, calculating dates, or evaluating conditions.
An expression can be as simple as a single function (for example, upper(name) to convert text to uppercase) or combine multiple functions to create complex logic.
Expressions are used in multiple contexts:
-
Rules: Used as condition logic to validate data.
-
Variables: Used to transform rule inputs before evaluation.
-
Transformation plans: Used in various steps including:
-
Transform Data steps - To modify and calculate values.
-
Filter conditions - To select specific records.
-
Split conditions - To route data to different paths.
-
|
Expressions in ONE Desktop
ONE expressions are also used extensively in ONE Desktop for data processing steps. Within ONE Desktop, expressions enable you to manipulate strings, work with dates, apply conditional logic, perform pattern matching with regular expressions, calculate string and set distances, and retrieve system parameters during plan execution. |
If you use Microsoft Excel, you already understand expressions:
| Concept | Microsoft Excel | ONE Expression |
|---|---|---|
Text joining |
|
|
Conditional logic |
|
|
Text functions |
|
|
Date functions |
|
|
However, there are some key differences from Microsoft Excel:
-
Use
+instead of&for text joining. -
Use
iif()instead ofIF()for conditions. -
Use
substr()instead ofMID()for text extraction. In addition, counting starts at 0, not 1.
| The following sections provide examples of the most useful ONE expressions for common data tasks. For a list of all available functions and their syntax, see ONE Expressions Reference. |
Your first expression: checking for empty fields
Let’s start with a common validation scenario.
To check if a required field like CUSTOMER_NAME is empty or contains only spaces:
length(trim(CUSTOMER_NAME)) = 0
This expression works as follow (step-by-step):
-
CUSTOMER_NAME- Get the field value. -
trim(CUSTOMER_NAME)- Remove leading and trailing spaces. -
length(trim(CUSTOMER_NAME))- Count remaining characters. -
length(trim(CUSTOMER_NAME)) = 0- Check if count equals 0 (empty).
In Microsoft Excel, the equivalent would be =LEN(TRIM(A1))=0.
Essential functions
The following are some of the functions you might need most frequently:
Text processing functions
| ONE function | Purpose | Example |
|---|---|---|
|
Remove extra spaces. |
|
|
Convert to uppercase. |
|
|
Convert to lowercase. |
|
|
Get first N characters. |
|
|
Get last N characters. |
|
|
Extract middle characters. |
|
|
Count characters. |
|
|
Replace text. |
|
substr() starts counting from 0.
|
Conditional logic functions
| ONE Function | Purpose | Example |
|---|---|---|
|
Simple if-then logic. |
|
|
Multiple conditions. |
|
|
Use first non-null value. |
|
Date functions
| ONE Function | Purpose | Example |
|---|---|---|
|
Current date. |
|
|
Calculate date difference. |
|
|
Add time to date. |
|
|
Extract date part. |
|
| The returned time is in the server time zone (UTC by default), see Time zones. |
Pattern matching with regular expressions
Regular expressions (regex) allow you to match complex text patterns.
In ONE expressions, regex patterns are prefixed with @ and used with the matches() function.
| Pattern | Purpose | Example |
|---|---|---|
|
Test if text matches pattern. |
|
|
Start of text. |
|
|
End of text. |
|
|
Any uppercase letter. |
|
|
Any digit. |
|
|
One or more of any character. |
|
|
Either pattern. |
|
Some common regex patterns used in the examples are:
-
Email:
@"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$". -
US phone:
@"^\(\d{3}\)\s\d{3}-\d{4}$"for (123) 456-7890 format. -
ISO country code:
@"^[A-Z]{3}$"for 3-letter codes like USA.
Nesting functions
You can embed functions within functions by using brackets. For example:
`Upper(Left("AtaccamaONE", 8) & " Data Quality")`This expression would return ATACCAMA DATA QUALITY in upper case.
When functions are nested with brackets, they are evaluated from the innermost bracket (the function Left in this case), then any operations (in this case the concatenation &), and finally the outer function Upper (which converts text to upper case).
Expression examples
This section provides a compilation of example expressions for use across the various contexts mentioned earlier in the article. The examples are organized by type - transformations first, followed by detailed rule validation examples.
Transformation expressions
These expressions are used to transform data in variables or transformation plans. They can also be used together with rules—either as variables to transform rule inputs before validation, or after validation to extract additional information from validated data. See ISIN validation and parsing for an example of how transformations work together with validation rules.
Remove special characters from customer name
Replaces all characters other than specified letters (including German umlauts), spaces, and selected punctuation (comma, dot, dash) with a space.
substituteAll("[^a-zA-ZäöüßÄÖÜ\\s',.-]", " ", CLIENT_NAME)
Combine fields
Creates a full address string from component fields.
full_address := trim(ADDRESS1 + ", " + CITY + ", " + STATE + " " + ZIP_CODE)
Compute age in months
Calculates the number of months between birth date and today.
dateDiff(birth_date, today(), 'MONTH')
Compute age in years
Calculates the number of years between birth date and today.
dateDiff(birth_date, today(), 'YEAR')
Convert Celsius to Fahrenheit
Standard formula for converting Celsius temperature to Fahrenheit.
(TEMPERATURE_CELSIUS * 1.8) + 32
Convert Fahrenheit to Celsius
Standard formula for converting Fahrenheit temperature to Celsius.
(TEMPERATURE_FAHRENHEIT - 32) / 1.8
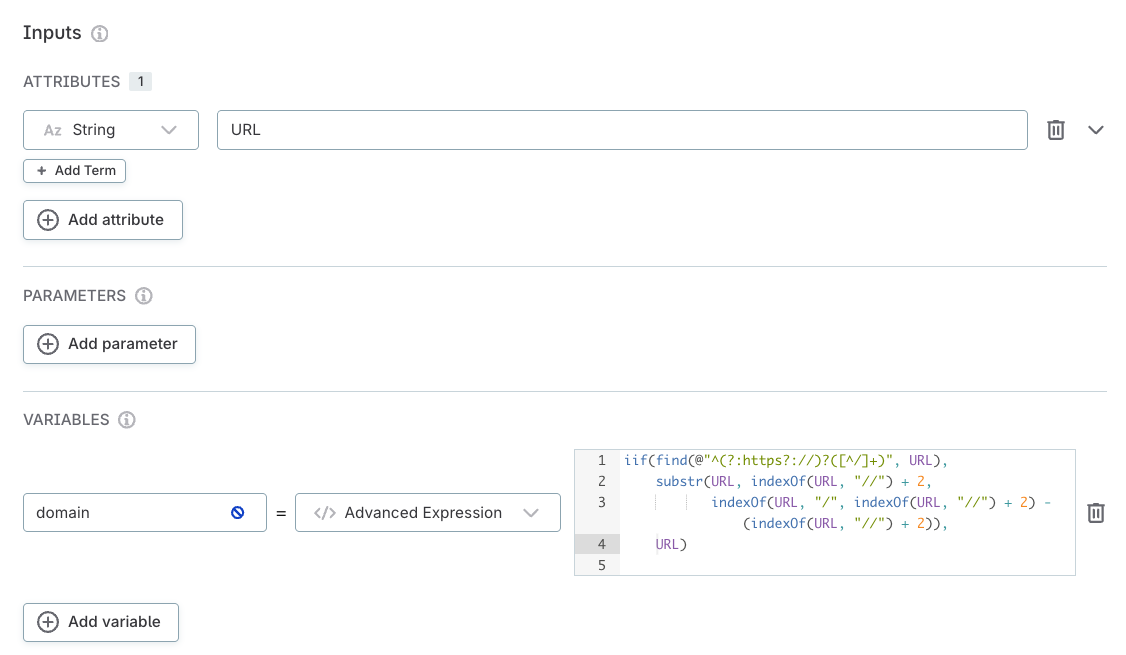
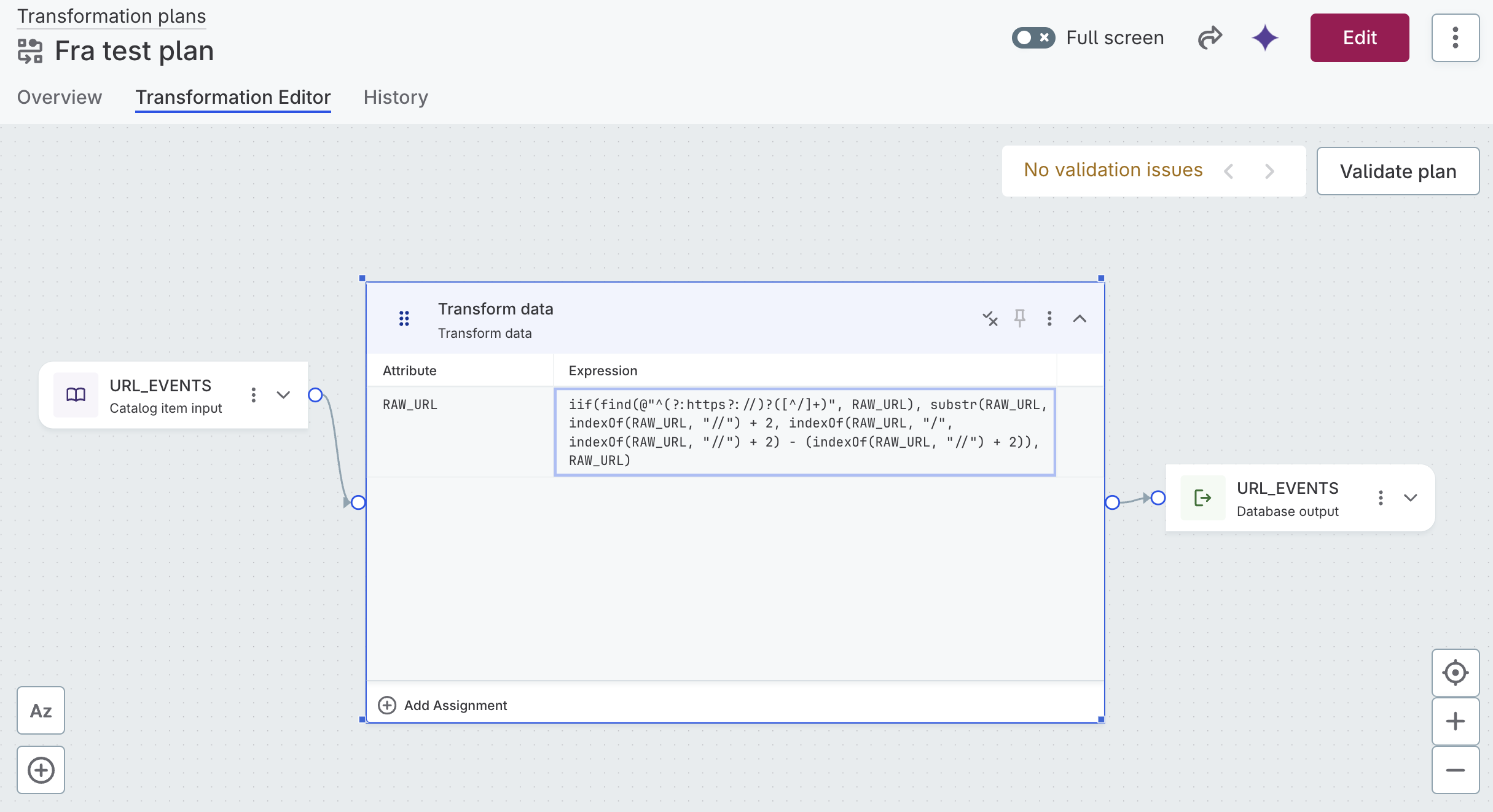
Parse domain from URL
If the input string starts with "http://" or "https://", this expression extracts the domain by taking the substring between the first double forward slash ("//") and before the next forward slash ("/").
iif(find(@"^(?:https?://)?([^/]+)", in_URL),
substr(in_URL, indexOf(in_URL, "//") + 2,
indexOf(in_URL, "/", indexOf(in_URL, "//") + 2) - (indexOf(in_URL, "//") + 2)),
in_URL)
Rule examples
These expressions are typically used in rule conditions to validate data quality.
The examples are presented in a format that mimics how you would configure them in the platform, showing the inputs (attributes) and rule logic (conditions) as they would appear when setting up rules.
Check for specific values
Validate that STATUS must be one of these values: "ACTIVE", "INACTIVE", "PENDING". Any other value, including null or empty strings, should be considered invalid.
- Inputs
-
-
Attributes:
-
type:
String, value: STATUS
-
-
- Rule Logic
Simple number validation
Validate that amount must be positive. This ensures that financial amounts, quantities, or other numeric values that should never be negative or zero are properly validated.
- Inputs
-
-
Attributes:
-
type:
Integer, value: AMOUNT
-
-
- Rule Logic
Null or placeholder value detection
Detect missing or placeholder data. This expression checks if a value represents missing, null, or placeholder data. It trims whitespace and checks against common null indicators including various cases of "NULL", "N/A", single punctuation marks, and empty strings.
- Inputs
-
-
Attributes:
-
type:
String, value: VALUE
-
-
- Rule Logic
Pattern matching rules
Pattern matching only validates the format of values (for example, checking if a phone number follows the pattern 123-456-7890).
To ensure data validity, combine pattern matching with additional checks such as domain or reference data validation.
For instance, a phone number might match the correct format but still be invalid if it doesn’t exist in your reference data or uses an invalid area code.
|
Email format validation
Validate email format using regular expressions.
This expression uses a regex pattern to check if the email follows standard format requirements—ensuring it has a username part, an at symbol ("@"), and a domain part with at least two letters.
- Inputs
-
-
Attributes:
-
type:
String, value: EMAIL_ADDRESS
-
-
- Rule Logic
Phone number format validation
US phone number format
Validate US phone number patterns using regular expressions.
This rule uses regex patterns to check if a phone number matches one of three valid US formats: parentheses with area code (for example, (123) 456-7890), dashes (123-456-7890), or 10 consecutive digits (1234567890).
- Inputs
-
-
Attributes:
-
type:
String, value: PHONE
-
-
- Rule Logic
UK phone number format
Validate UK phone number format using regular expressions.
This rule uses a regex pattern to validate UK phone numbers which can start with +44 (international), 0 (domestic), or neither. The country code can optionally be in parentheses, and the number must contain exactly 10 digits with optional spaces between digits.
- Inputs
-
-
Attributes:
-
type:
String, value: PHONE
-
-
- Rule Logic
Date range validation
Validate that birth date is reasonable. This expression checks if a person’s birth date is between January 1, 1900, and today’s date.
- Inputs
-
-
Attributes:
-
type:
Date, value: BIRTH_DATE
-
-
- Rule Logic
ISO-3 country code format validation
Validate 3-letter country code format using regular expressions.
This rule uses a regex pattern to ensure country codes are exactly three alphabetic characters (like USA, GBR, FRA). It rejects numeric values and values that aren’t exactly three characters long.
- Inputs
-
-
Attributes:
-
type:
String, value: COUNTRY_CODE
-
-
- Rule Logic
Complex business logic rules
Healthcare provider licensing
Validate that license numbers are correctly associated with provider types.
Healthcare Providers (HCP) must have a license number, while Healthcare Organizations (HCO) should not have one. This rule ensures proper data entry based on the provider type.
- Inputs
-
-
Attributes:
-
type:
String, value: PROVIDER_TYPE -
type:
String, value: LICENSE_NUMBER
-
-
- Rule Logic
Customer identification requirements
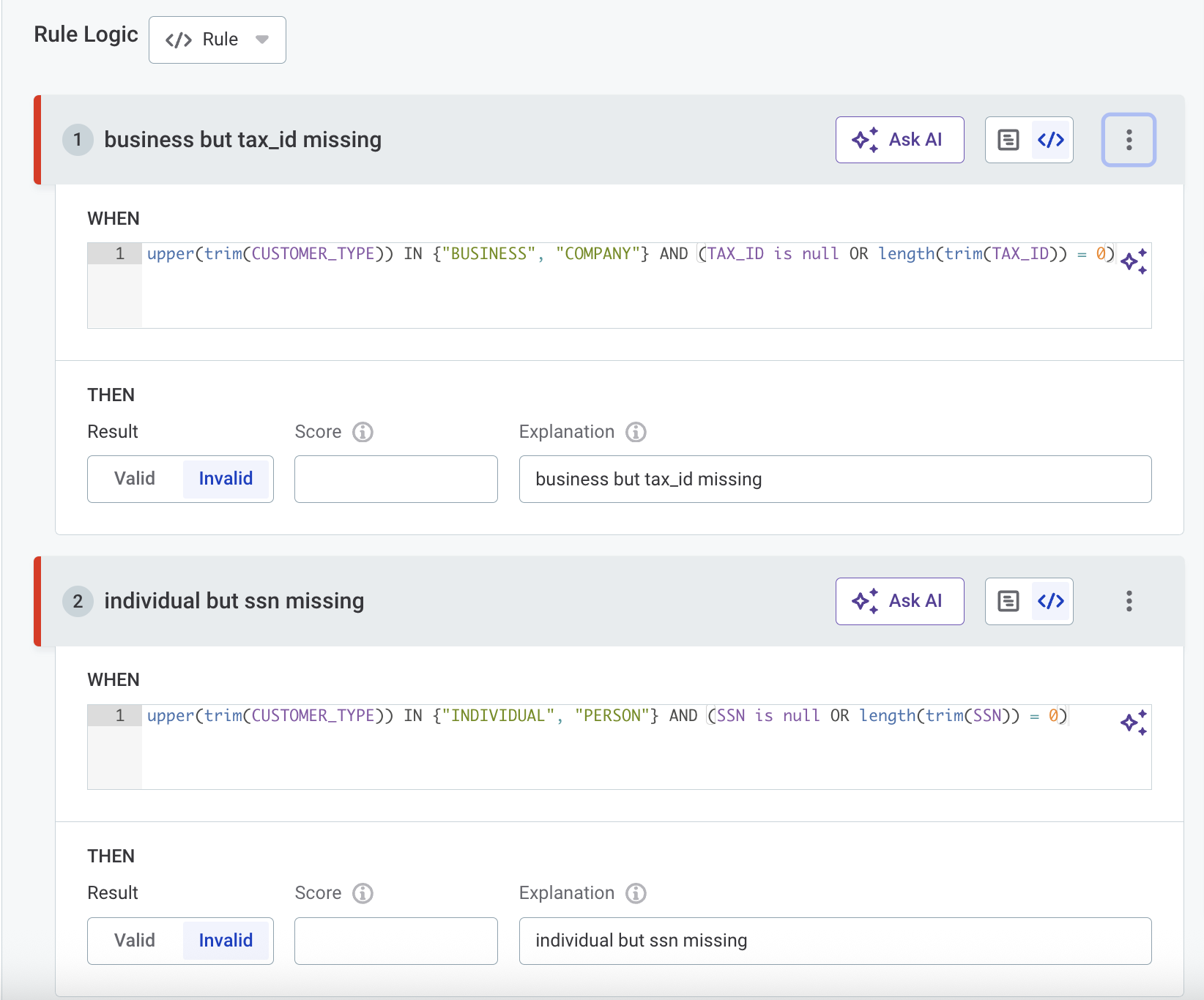
Validate that customers have the appropriate identification based on their type.
Business customers must have a Tax ID and should not have an SSN. Individual customers must have an SSN and should not have a Tax ID. This rule ensures the correct identifier is provided depending on the type of customer.
- Inputs
-
-
Attributes:
-
type:
String, value: CUSTOMER_TYPE -
type:
String, value: TAX_ID -
type:
String, value: SSN
-
-
- Rule Logic
Financial identifier validation & parsing
CUSIP validation
Validate CUSIP (Committee on Uniform Securities Identification Procedures) identifiers. A CUSIP is a 9-character alphanumeric code uniquely identifying North American financial securities.
This rule validates the format and verifies the check digit using the standard CUSIP algorithm to ensure the identifier hasn’t been corrupted or mistyped.
- Inputs
-
-
Attributes:
-
type:
String, value: CUSIP_VALUE
-
-
- Rule Logic
ISIN validation and parsing
Validate ISIN (International Securities Identification Number). An ISIN is a 12-character alphanumeric code consisting of a two-letter country code, nine-character NSIN (National Securities Identifying Number), and one check digit.
This rule uses a regex pattern to validate the format (2 letters + 9 alphanumeric + 1 digit) and additionally verifies the check digit using the ISIN algorithm (Luhn variant for alphanumeric) to ensure data integrity.
The transformation expression after the example can be used after validation to extract the country code from a valid ISIN.
- Inputs
-
-
Attributes:
-
type:
String, value: ISIN_VALUE
-
-
- Rule Logic
Related transformation: parse country code from ISIN
If the trimmed code has the right length of 12 characters, extract the first two characters as country code. Otherwise return empty string.
This transformation can be used as a variable to pre-process the ISIN or after validation to extract additional information.
iif(length(replace(trim(ISIN_VALUE), '-', '')) = 12, left(ISIN_VALUE, 2), '')
Government identifier validation
UK national insurance number (NINO)
Validate UK national insurance numbers using regular expressions and pattern matching. A valid NINO has the format: two letters + six digits + one letter (for example, AB123456C).
The rule uses regex to check that the first two letters don’t contain invalid characters (D, F, I, Q, U, V, O) or specific invalid combinations (BG, GB, KN, NK, NT, TN, ZZ). The final letter must be A, B, C, or D. This ensures NINOs follow the official UK government format requirements.
- Inputs
-
-
Attributes:
-
type:
String, value: NINO_VALUE
-
-
- Rule Logic
Was this page useful?