
Run Documentation Flow
After you connect to a data source, run data discovery to get a better picture of the data you’re working with.
There are three default documentation flows available for data discovery:
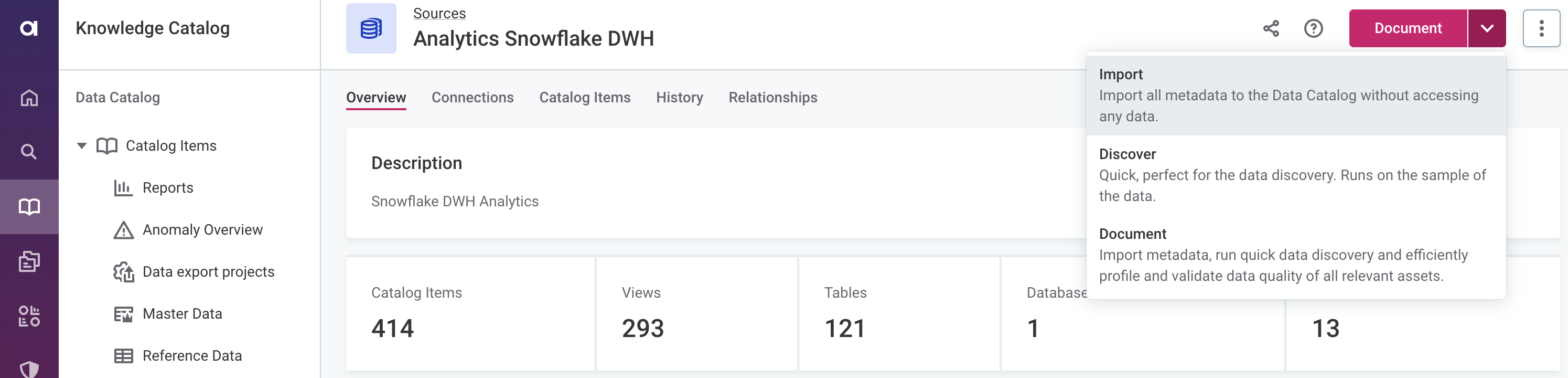
- Import
-
Imports all catalog items from a source and analyzes their metadata without accessing the data. Running this flow populates the metadata information for each catalog item (displayed on the Overview tab).
- Discover
-
The fastest way to dig deeper into your data. This flow imports metadata and runs sample profiling on all catalog items in a source, which allows you to see the relationships between the assets and preview the data.
- Document
-
The most complex documentation flow. The flow imports metadata and runs sample profiling on all catalog items, then identifies the most relevant assets and analyzes them using full profiling, and DQ evaluation, and anomaly detection, giving you the most complete information about the data source.
You can customize the default documentation flows as needed, or create a custom one (see Configure Documentation Flow).
|
We do not recommend making changes to technical (imported) catalog item metadata after it’s been processed using a documentation flow. If attributes (or tables) are renamed, modified, or removed, subsequent documentation attempts might fail. However, if such changes are required, first delete the catalog item and all the related objects, such as monitoring projects, then rerun the documentation flow to import and profile the data again. You can freely edit non-imported metadata like descriptions, stewardship, and relationships. |
Ad hoc documentation flow
To run a documentation flow on an ad hoc basis:
A whole source
-
In Data Catalog > Sources, select the required source and from the document menu, select the flow you want to run: Import, Discover, or Document. Confirm your choice when prompted (Import or Proceed).
Alternatively, start the documentation flow when creating a data source by opting for Create & Document.
Specific assets
If your data source is a relational database, you can choose the schemas and/or tables that you want to analyze. If your data source is a file system, use this to import only specific files.
-
In Data Catalog > Sources, select the required source and switch to the Connections tab.
-
Select Browse to open the connection browser, select all the required assets and, in the ribbon that appears, select the flow you want to run: Import to catalog, Discover, or Profile. Confirm your choice when prompted (Import or Proceed).
To select specific tables from a schema, select the schema first, then choose the required tables. 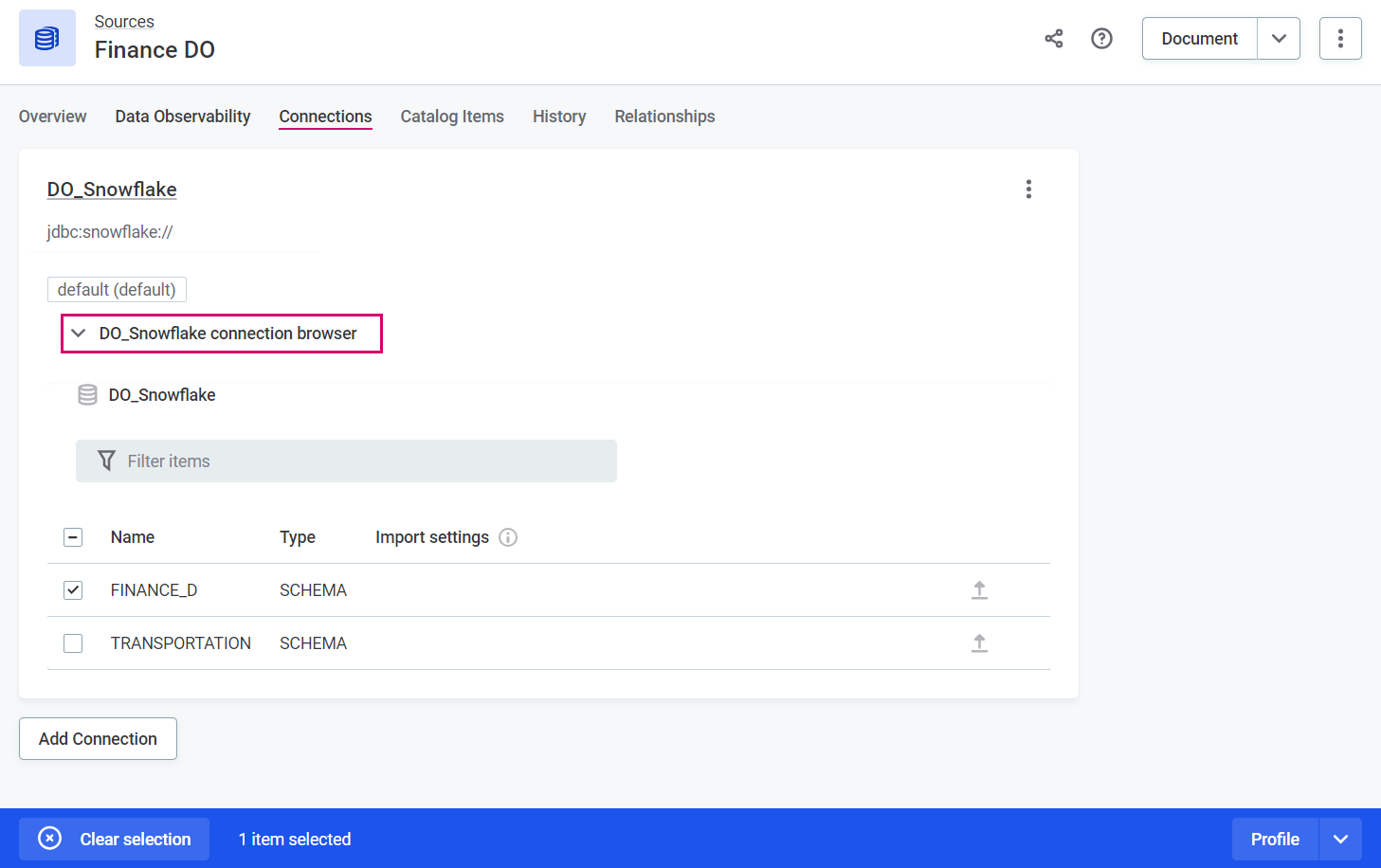
While the documentation flow is running, you can view the details by selecting Show details from the source detailed view.

Alternatively, track the progress using the Processing Center. See Monitor flow progress.
|
In addition, you can also view more details about the status of a particular source by going to Sources > [your data source] > Connections and selecting Show details from the three dots menu. 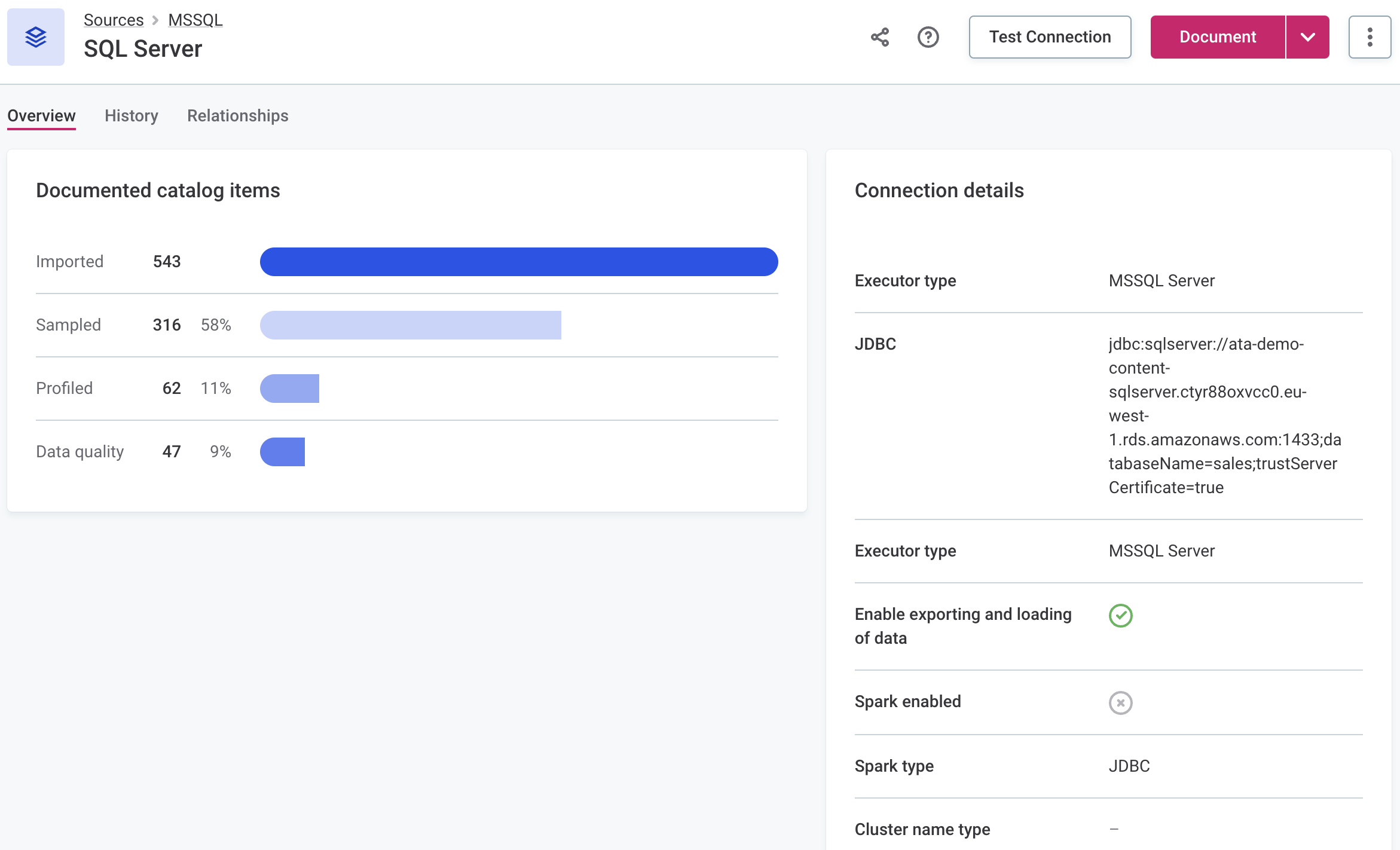
|
When the documentation flow finishes, it remains in the Running status until it is published. Make sure to publish changes.
To view a list of imported (Import flow) or profiled (Discover and Document flows) catalog items, open the Catalog Items tab of the source.
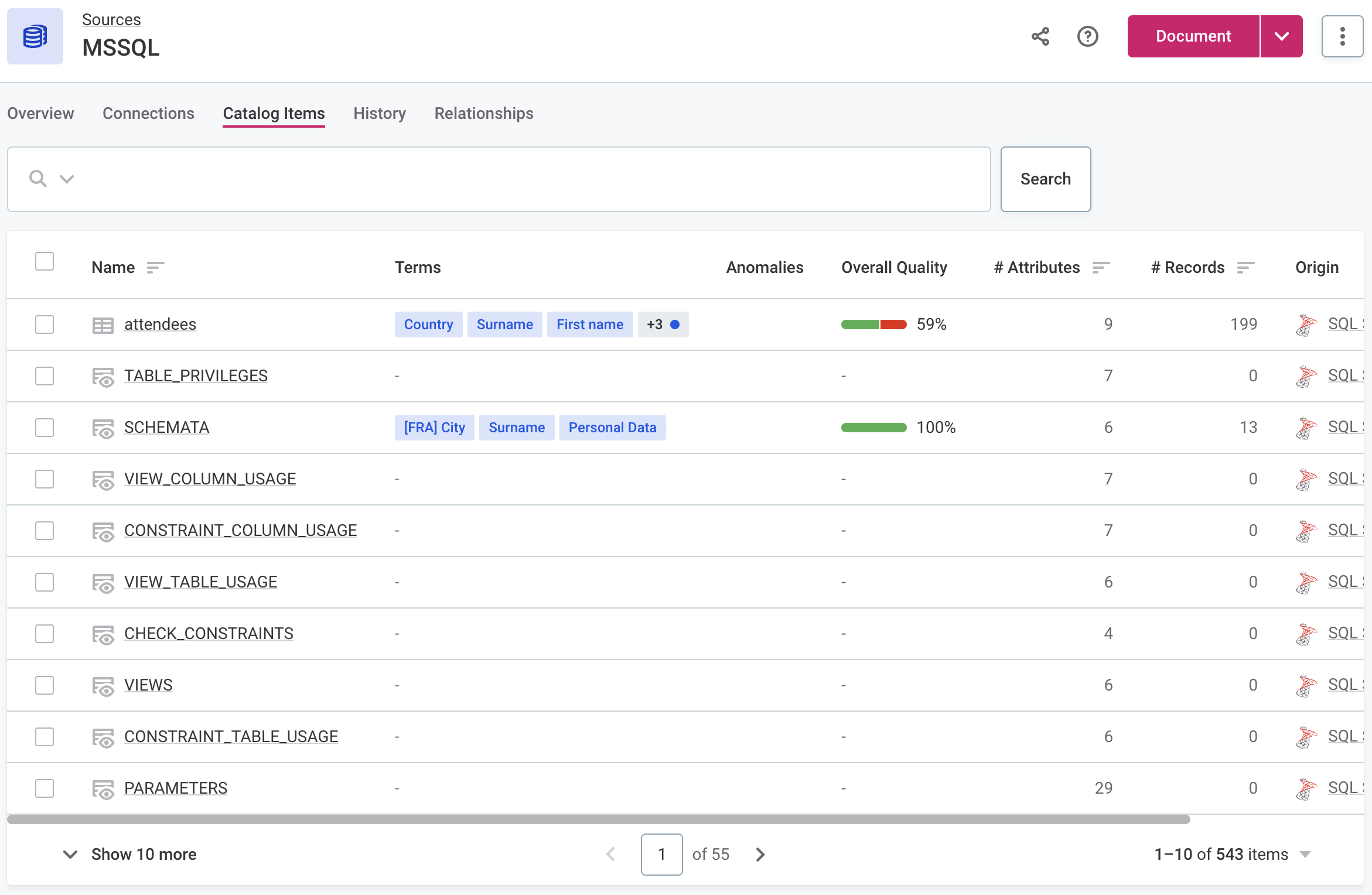
| Once the documentation flow is completed, create tasks that should be performed next on the analyzed assets. For instance, create a task detailing which catalog items need to be fully profiled or a task suggesting how to address the anomalies detected. |
Next steps
Monitor flow progress
When you run documentation flow, ONE starts the following jobs for each profiled catalog items, depending on your profiling configuration: Metadata import, Metadata classification, Profiling, Anomaly detection, and DQ Evaluation of catalog item jobs.
More information about these jobs can be viewed at any time in the Processing Center.
Monitor job status
To monitor the job status, select the Processing Center icon in the main navigation menu to open the Processing Center notifications view.
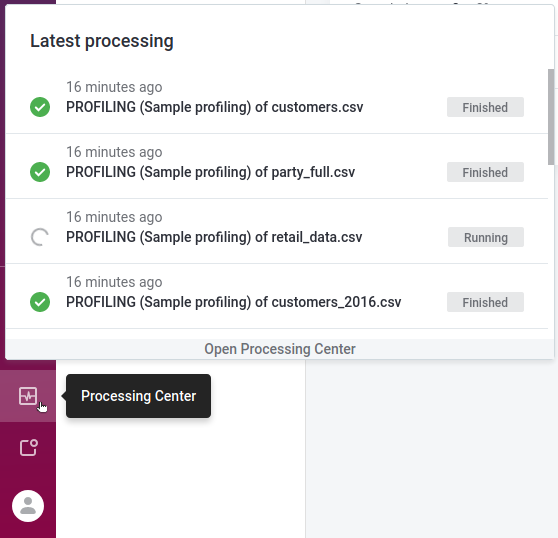
Once the job is successfully completed, its Status changes from RUNNING to FINISHED.
Otherwise, the status is updated to FAILED and an error message is provided.
To view the job results, select the job directly from the notifications list.
View job details
To see the job details, select Processing Center from the left navigation menu and then Open Processing Center under the list of notifications.
From the Base jobs menu, select the job type and locate your job.
If the job was started as part of a documentation flow, its Execution type is FLOW.
For manually initiated jobs, the type is MANUAL.
View profiling results
Open the source and select a catalog item to learn more about the state of your data (available from the Profile and DQ insights tab) and decide on the next steps for improving the data quality. For details, see Understand Profiling Results.
Was this page useful?