
HA Database Locking and Leadership Election
Database Locking
To track the status of individual nodes and determine which node should be active, MDM HA uses two tables - mdm_lock and mdm_ha_node - configured via MDM Server Application Properties (see MDM Server Application Properties).
Table prefix can be set by ataccama.one.mdm.ha.db.table-prefix , database name defined by ataccama.one.mdm.ha.db.name.
The following table schema is simplified for easier viewing:

-
mdm_lock - Stores unique identifier of lock owner and last active time. Period of heartbeat is defined by
ataccama.one.mdm.ha.db.heartbeat.interval. A scheduler tries to remove expired entries in the interval set byataccama.one.mdm.ha.db.heartbeat.expirationand it marks all entries older thenataccama.one.mdm.ha.db.heartbeat.ttlas expired. -
mdm_ha_node - Stores cluster information about cluster nodes and their status and additional properties. Entries are updated by a similar logic as in mdm_lock, only driven by a different timer. Period of heartbeat is defined by
ataccama.one.mdm.ha.db.heartbeat.interval. A scheduler tries to remove expired entries in the interval set byataccama.one.mdm.ha.db.heartbeat.expirationand it marks all entries older thenataccama.one.mdm.ha.db.heartbeat.ttlas expired.
Leadership Election
The election workflow is called regularly based on ataccama.one.mdm.ha.db.election.interval with a delay defined by ataccama.one.mdm.ha.db.election.startup-timeout.
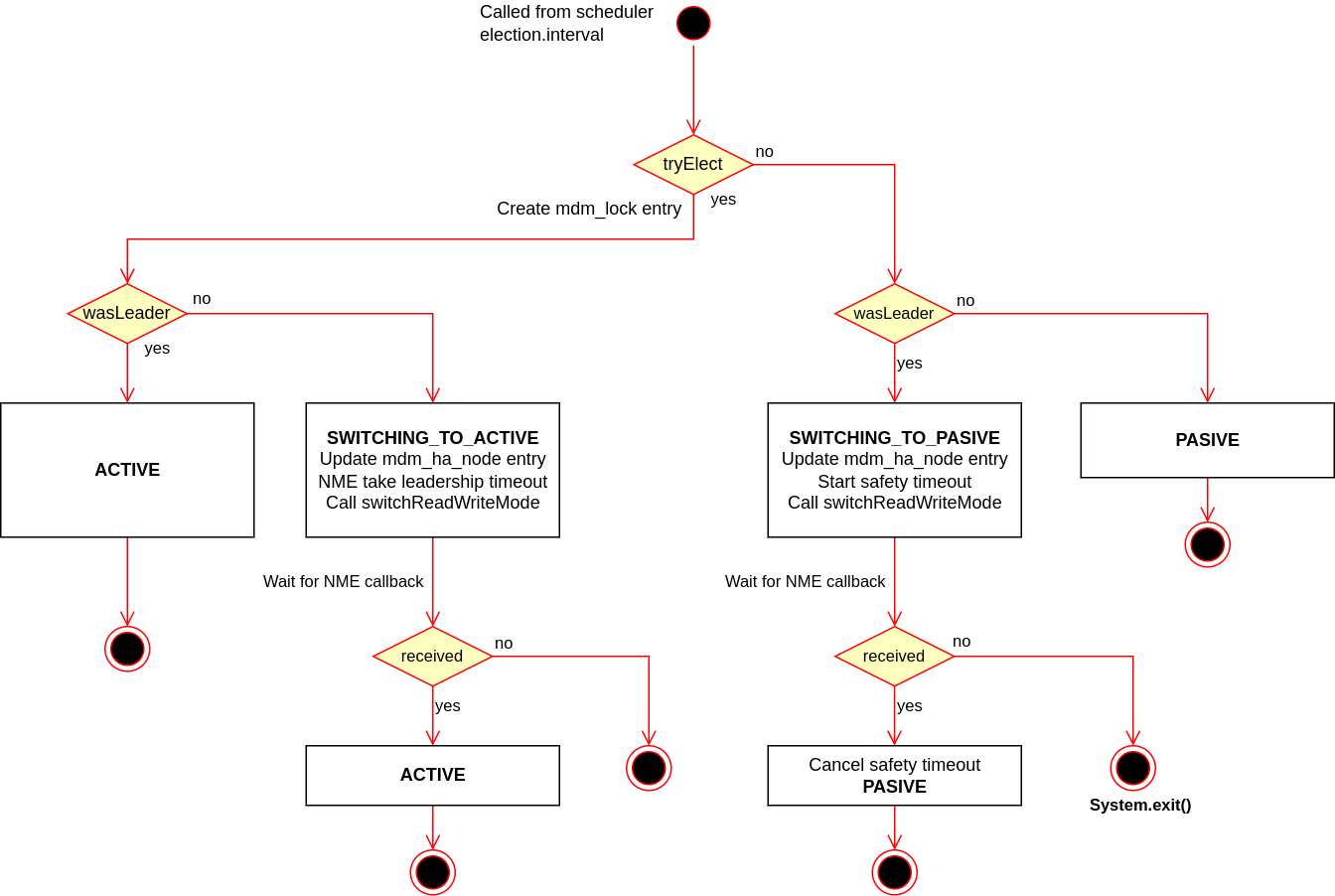
At first, the LockLeaderElector::tryElect is called. It creates a table lock (with an id defined by ataccama.one.mdm.ha.db.lock-key) using the distributed lock library.
If locking is successful, then the lifetime in mdm_ha_node is extended, or the sequence for switching to active mode is started.
If locking is not successful, then the node is staying in passive mode, or the sequence to make the instance passive is started.
-
Switching to active: Initially, the node state is changed to SWITCHING_TO_ACTIVE. Before calling
INmeReadWriteSwitcher::switchToReadWriteMode, there is a safety timeout defined byataccama.one.mdm.ha.db.node.timeout.interval. After this, the HA part stays in SWITCHING_TO_ACTIVE state and it waits for theINmeReadWriteModeSwitchListener::afterSwitchevent from the NME. If the event does not occur, the entire election process is repeated. -
Switching to passive: The node state is changed to SWITCHING_TO_PASSIVE. Then the
INmeReadWriteSwitcher::switchToReadWriteModeis called to switch the NME part to RO mode. At the same time, safety watchdog is started with a timeout defined byataccama.one.mdm.ha.max-active-to-passive-switching-time. If NME does not callINmeReadWriteModeSwitchListener::afterSwitchwith RO status in time, then a NME failure is indicated andSystem.exit()is called. In the case of successful change, the node status is updated to PASSIVE and the safety watchdog is cancelled.
Was this page useful?