
Azure Databricks
This guide explains how to configure Ataccama ONE to work with Azure Databricks clusters for large-scale data processing. You’ll set up the necessary connections between your Ataccama ONE deployment, Databricks cluster, and Azure Data Lake Storage (ADLS) Gen2.
By following this guide, you’ll be able to:
-
Process large datasets using Databricks compute resources
-
Leverage Spark processing capabilities within Ataccama ONE
-
Securely connect to your Azure Databricks workspace
-
Optionally enable Unity Catalog for enhanced data governance
This configuration is suitable for hybrid deployments, self-managed environments, and Custom Ataccama Cloud deployments that need to process data at scale using Azure Databricks.
|
This configuration guide covers Spark integration with Azure Databricks, which requires a Spark processing license. If you do not have a Spark processing license or prefer a simpler setup, use the standard JDBC connection instead. For JDBC connection setup, see Databricks JDBC. |
Prerequisites
Cluster configuration
The following property must be added to your Databricks cluster’s Spark configuration in the Azure Databricks workspace:
spark.serializer org.apache.spark.serializer.KryoSerializerTo add this property:
-
In your Azure Databricks workspace, go to Compute.
-
Select your cluster or create a new one.
-
In the cluster configuration, expand Advanced Options.
-
In the Spark tab, add the property above to the Spark Config field.
-
Save the cluster configuration and restart the cluster if it’s already running.
ADLS container permissions
The container must have either Storage Blob Data Owner or Storage Blob Data Contributor permissions for the blob storage and the user account or Entra ID service principal.
To set up these permissions, refer to the Microsoft article on authorization errors.
Required connections
To work with the Databricks cluster, you need to establish the following connections:
-
Processing virtual machine (VM) with DPE to Databricks cluster
-
Processing VM with DPE to Ataccama dedicated ADLS Gen2 container
-
Databricks cluster to Ataccama dedicated ADLS Gen2 container
| As a customer, you are responsible for setting up the connection from the Databricks cluster to your data lake. |
Download the Databricks JDBC driver
-
Go to the Databricks JDBC drivers download page.
-
Download the latest version of the JDBC driver.
-
Place the downloaded driver in your JDBC drivers directory.
-
Note the exact filename of the downloaded JAR file (for example,
DatabricksJDBC42.jar). You’ll need this for the configuration step.
Step 1: Metadata configuration
Configure the metadata connection in /opt/ataccama/one/dpe/etc/application.properties.
This enables Ataccama ONE to browse and profile data from your Databricks cluster.
Method 1: Token authentication
Use a Databricks personal access token for authentication:
plugin.metastoredatasource.ataccama.one.cluster.databricks.name={ CLUSTER_NAME }
plugin.metastoredatasource.ataccama.one.cluster.databricks.driver-class=com.databricks.client.jdbc.Driver
plugin.metastoredatasource.ataccama.one.cluster.databricks.driver-class-path={ ATACCAMA_ONE_HOME }/dpe/lib/jdbc/DatabricksJDBC42.jar
plugin.metastoredatasource.ataccama.one.cluster.databricks.url={ DBR_JDBC_STRING }
plugin.metastoredatasource.ataccama.one.cluster.databricks.authentication=TOKEN
plugin.metastoredatasource.ataccama.one.cluster.databricks.databricksUrl={ WORKSPACE_URL }
plugin.metastoredatasource.ataccama.one.cluster.databricks.timeout=15m
plugin.metastoredatasource.ataccama.one.cluster.databricks.profiling-sample-limit=100000
plugin.metastoredatasource.ataccama.one.cluster.databricks.full-select-query-pattern=SELECT {columns} FROM {table}
plugin.metastoredatasource.ataccama.one.cluster.databricks.preview-query-pattern=SELECT {columns} FROM {table} LIMIT {previewLimit}
plugin.metastoredatasource.ataccama.one.cluster.databricks.row-count-query-pattern=SELECT COUNT(*) FROM {table}
plugin.metastoredatasource.ataccama.one.cluster.databricks.sampling-query-pattern=SELECT {columns} FROM {table} LIMIT {limit}
plugin.metastoredatasource.ataccama.one.cluster.databricks.dsl-query-preview-query-pattern=SELECT * FROM ({dslQuery}) dslQuery LIMIT {previewLimit}
plugin.metastoredatasource.ataccama.one.cluster.databricks.dsl-query-import-metadata-query-pattern=SELECT * FROM ({dslQuery}) dslQuery LIMIT 0
spring.profiles.active=SPARK_DATABRICKSMethod 2: Service principal authentication
Use an Entra ID service principal for authentication:
TIP: Your clientId is the same as your applicationId.
# Basic metadata connection settings
plugin.metastoredatasource.ataccama.one.cluster.databricks.name=Databricks Cluster
plugin.metastoredatasource.ataccama.one.cluster.databricks.url=jdbc:databricks://{ JDBC_CONNECTION_STRING }
plugin.metastoredatasource.ataccama.one.cluster.databricks.databricksUrl={ WORKSPACE_URL }
plugin.metastoredatasource.ataccama.one.cluster.databricks.driver-class=com.databricks.client.jdbc.Driver
plugin.metastoredatasource.ataccama.one.cluster.databricks.driver-class-path=${ataccama.path.root}/lib/runtime/jdbc/databricks/*
plugin.metastoredatasource.ataccama.one.cluster.databricks.timeout=15m
# Authentication settings
plugin.metastoredatasource.ataccama.one.cluster.databricks.authentication=INTEGRATED
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.authType=AAD_CLIENT_CREDENTIAL
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.tenantId={ TENANT_ID }
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.clientId={ CLIENT_ID }
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.clientSecret={ CLIENT_SECRET }
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.scope=2ff814a6-3304-4ab8-85cb-cd0e6f879c1d/.default
# Query patterns
plugin.metastoredatasource.ataccama.one.cluster.databricks.full-select-query-pattern=SELECT {columns} FROM {table}
plugin.metastoredatasource.ataccama.one.cluster.databricks.preview-query-pattern=SELECT {columns} FROM {table} LIMIT {previewLimit}
plugin.metastoredatasource.ataccama.one.cluster.databricks.row-count-query-pattern=SELECT COUNT(*) FROM {table}
plugin.metastoredatasource.ataccama.one.cluster.databricks.sampling-query-pattern=SELECT {columns} FROM {table} LIMIT {limit}
plugin.metastoredatasource.ataccama.one.cluster.databricks.dsl-query-preview-query-pattern=SELECT * FROM ({dslQuery}) dslQuery LIMIT {previewLimit}
plugin.metastoredatasource.ataccama.one.cluster.databricks.dsl-query-import-metadata-query-pattern=SELECT * FROM ({dslQuery}) dslQuery LIMIT 0
# Enable Spark profile
spring.profiles.active=SPARK_DATABRICKSAdditional Unity Catalog configuration
Unity Catalog provides a unified approach to governing your data and AI assets across Databricks workspaces, along with centralized access control, auditing, lineage, and data discovery capabilities.
In Unity Catalog, data assets are organized in three levels, starting from the highest: Catalog > Schema > Table, allowing you to work with multiple catalogs at once.
If you are using Unity Catalog, add these properties to /opt/ataccama/one/dpe/etc/application.properties:
# Unity Catalog settings
plugin.metastoredatasource.ataccama.one.cluster.databricks.unity-catalog-enabled=true
plugin.metastoredatasource.ataccama.one.cluster.databricks.catalog-exclude-pattern=^(SAMPLES)|(samples)|(main)$
Use plugin.metastoredatasource.ataccama.one.cluster.databricks.catalog-exclude-pattern to specify catalogs as technical and prevent them from being imported to ONE.
The value should be a regular expression matching the catalog items that you don’t want to import.
|
|
Unity Catalog is only supported with Dedicated access mode enabled. For more information about what this means for your Databricks configuration, see the official Databricks documentation, article Create clusters & SQL warehouses with Unity Catalog access. |
Step 2: Spark job configuration
Configure Spark processing in /opt/ataccama/one/dpe/etc/application-SPARK_DATABRICKS.properties.
This enables running data quality and processing jobs on your Databricks cluster.
Spark processing basic settings
Add the following properties to /opt/ataccama/one/dpe/etc/application-SPARK_DATABRICKS.properties:
# Cluster selection
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.cluster={ CLUSTER_NAME }
# Databricks workspace URL
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.url=https://{ YOUR_DATABRICKS_CLUSTER }.azuredatabricks.net
# Mount point for temporary storage
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.point=/ataccama/dbr-tmp
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.url=abfss://{ CONTAINER_NAME }@{ STORAGE_NAME }.dfs.core.windows.net/{ PATH_TO_FOLDER }Libraries and classpath configuration
Add the following properties to /opt/ataccama/one/dpe/etc/application-SPARK_DATABRICKS.properties:
# File system implementation
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.adl.impl=org.apache.hadoop.fs.adl.AdlFileSystem
# Relative to temp/jobs/${jobId} from repository root directory
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.cpdelim=;
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.cp.runtime=../../../lib/runtime/*;../../../lib/jdbc/*;../../../lib/jdbc_ext/*;../../../lib/runtime/ext/*;../../../lib/runtime/extra/*
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.cp.ovr=../../../lib/ovr/*.jar
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.cp.databricks=../../../lib/runtime/databricks/*
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.cp.!exclude=!atc-hive-jdbc*!hive-jdbc*;!kryo-*.jar;!scala*.jar;!cif-dtdb*.jar
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.lcp.!exclude=!guava-11*
# Hadoop 3 library path
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.lcp.ext=../../../lib/runtime/hadoop3/*Authentication configuration
Choose one of the following authentication methods and add the properties to /opt/ataccama/one/dpe/etc/application-SPARK_DATABRICKS.properties:
Method 1: Token authentication
# Databricks authentication
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.authType=PERSONAL_TOKEN
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.token={ DBR_TOKEN }Method 2: Service principal authentication
# Databricks authentication
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.authType=AAD_CLIENT_CREDENTIAL
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.aad.tenantId={ TENANT_ID }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.aad.clientId={ CLIENT_ID }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.aad.clientSecret={ CLIENT_SECRET }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.aad.resource=2ff814a6-3304-4ab8-85cb-cd0e6f879c1dAzure configuration
Configure ADLS Gen2 access for both DPE and Databricks cluster by adding the following properties to /opt/ataccama/one/dpe/etc/application-SPARK_DATABRICKS.properties:
# Connection from Processing VM with DPE to ADLS Gen2
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.azure.account.auth.type=OAuth
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.azure.account.oauth.provider.type=org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.azure.account.oauth2.client.id={ ABFSS_CLIENT_ID }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.azure.account.oauth2.client.secret={ ABFSS_CLIENT_SECRET }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.azure.account.oauth2.client.endpoint=https://login.microsoftonline.com/{ TENANT_ID }/oauth2/token
# Connection from Databricks cluster to ADLS Gen2
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.conf.fs.azure.account.auth.type=OAuth
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.conf.fs.azure.account.oauth.provider.type=org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.conf.fs.azure.account.oauth2.client.id={ ABFSS_CLIENT_ID }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.conf.fs.azure.account.oauth2.client.secret={ ABFSS_CLIENT_SECRET }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.conf.fs.azure.account.oauth2.client.endpoint=https://login.microsoftonline.com/{ TENANT_ID }/oauth2/token
Replace all placeholder values in { } with your actual configuration values.
|
Azure Key Vault integration (optional)
You can use Azure Key Vault to manage secrets instead of entering plain text values in the configuration. Connect to Key Vault using either direct connection credentials or through Managed Service Identity (MSI).
Key Vault direct connection
Add the following properties to /opt/ataccama/one/dpe/etc/application.properties to configure direct Key Vault authentication:
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.keyvault.authType=AAD_CLIENT_CREDENTIAL
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.keyvault.vaultUrl=https://{ VAULT_NAME }.vault.azure.net/
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.keyvault.tenantId={ TENANT_ID }
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.keyvault.clientId={ CLIENT_ID }
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.keyvault.clientSecret={ CLIENT_SECRET }Managed Service Identity (MSI)
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.keyvault.authType=AAD_MANAGED_IDENTITY
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.aad.keyvault.vaultUrl=https://{ VAULT_NAME }.vault.azure.net/
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.aad.keyvault.clientId={ CLIENT_ID }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.dbr.aad.keyvault.tenantId={ TENANT_ID }
plugin.metastoredatasource.ataccama.one.cluster.databricks.aad.keyvault.resource=2ff814a6-3304-4ab8-85cb-cd0e6f879c1d|
Retrieve the client ID using: |
Using Key Vault secrets
Reference secrets in your configuration:
# Example: Using Key Vault for ADLS credentials
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.conf.fs.azure.account.auth.type=OAuth
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.conf.fs.azure.account.oauth.provider.type=org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.conf.fs.azure.account.oauth2.client.id=keyvault:SECRET:{ SECRET_NAME }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.conf.fs.azure.account.oauth2.client.secret=keyvault:SECRET:{ SECRET_NAME }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.mount.conf.fs.azure.account.oauth2.client.endpoint=https://login.microsoftonline.com/{ TENANT_ID }/oauth2/token
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.azure.account.auth.type=OAuth
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.azure.account.oauth.provider.type=org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.azure.account.oauth2.client.id=keyvault:SECRET:{ SECRET_NAME }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.azure.account.oauth2.client.secret=keyvault:SECRET:{ SECRET_NAME }
plugin.executor-launch-model.ataccama.one.launch-type-properties.SPARK.conf.fs.azure.account.oauth2.client.endpoint=https://login.microsoftonline.com/{ TENANT_ID }/oauth2/tokenDriver configuration
This guide assumes the use of DatabricksJDBC42.jar.
If you are using SparkJDBC42.jar, you need to modify the following property values in your configurations:
Using SparkJDBC42.jar
Replace these properties in /opt/ataccama/one/dpe/etc/application.properties:
# Replace this:
plugin.metastoredatasource.ataccama.one.cluster.databricks.url=jdbc:databricks://{ DBR_JDBC_STRING }
plugin.metastoredatasource.ataccama.one.cluster.databricks.driver-class=com.databricks.client.jdbc.Driver
# With this:
plugin.metastoredatasource.ataccama.one.cluster.databricks.url=jdbc:spark://{ DBR_JDBC_STRING }
plugin.metastoredatasource.ataccama.one.cluster.databricks.driver-class=com.simba.spark.jdbc.DriverConfigure the connection in ONE
After completing the configuration steps above, you’re ready to add the Databricks connection in ONE.
Create a source
To connect to a Databricks source in ONE:
-
Navigate to Data Catalog > Sources.
-
Select Create.
-
Provide the following:
-
Name: The source name.
-
Description: A description of the source.
-
Deployment (Optional): Choose the deployment type.
You can add new values if needed. See Lists of Values. -
Stewardship: The source owner and roles. For more information, see Stewardship.
-
| Alternatively, add a connection to an existing data source. See Connect to a Source. |
Add a connection
-
Select Add Connection.
-
In Select connection type, choose Metastore and select your configured Databricks cluster from the dropdown.
-
Provide the following:
-
Name: A meaningful name for your connection. This is used to indicate the location of catalog items.
-
Description (Optional): A short description of the connection.
-
Dpe label (Optional): Assign the processing of a data source to a particular data processing engine (DPE) by entering the DPE label assigned to the engine. For more information, see DPM and DPE Configuration in DPM Admin Console.
-
-
Select Spark enabled.
-
In Additional settings, select Enable exporting and loading of data if you want to export data from this connection and use it in ONE Data or outside of ONE.
Add credentials
-
Select Add Credentials.
-
In Credential type, select Token credentials or Integrated credentials according to the authentication method you used in the configuration. If you use integrated credentials, add a name and description for the set of credentials and proceed to Test the connection. If you used token:
-
Select a secret management service (optional): If you want to use a secret management service to provide values for the following fields, specify which secret management service should be used. After you select the service, you can enable the Use secret management service toggle and provide instead the names the values are stored under in your key vault. For more information, see Secret Management Service.
-
Token: The access token for Databricks. For more information, see the official Databricks documentation. Alternatively, enable Use secret management service and provide the name this value is stored under in your selected secret management service.
-
-
If you want to use this set of credentials by default when connecting to the data source, select Set as default.
One set of credentials must be set as default for each connection. Otherwise, monitoring and DQ evaluation fail, and previewing data in the catalog is not possible.
Test the connection
To test and verify whether the data source connection has been correctly configured, select Test Connection.
If the connection is successful, continue with the following step. Otherwise, verify that your configuration is correct and that the data source is running.
Save and publish
Once you have configured your connection, save and publish your changes. If you provided all the required information, the connection is now available for other users in the application.
In case your configuration is missing required fields, you can view a list of detected errors instead. Review your configuration and resolve the issues before continuing.
Next steps
You can now browse and profile assets from your Databricks connection.
In Data Catalog > Sources, find and open the source you just configured. Switch to the Connections tab and select Document. Alternatively, opt for Import or Discover documentation flow.
Or, to import or profile only some assets, select Browse on the Connections tab. Choose the assets you want to analyze and then the appropriate profiling option.
| As your Databricks cluster can shut down when idle, it sometimes takes a bit of time before it is ready again for requests. If you try to browse the cluster during this period, you receive a timeout error. |
|
If you are using Unity Catalog you can see the three catalog levels in the Source field when viewing catalog item details. Use this in the Location filter to narrow down the catalog items you’re looking for. 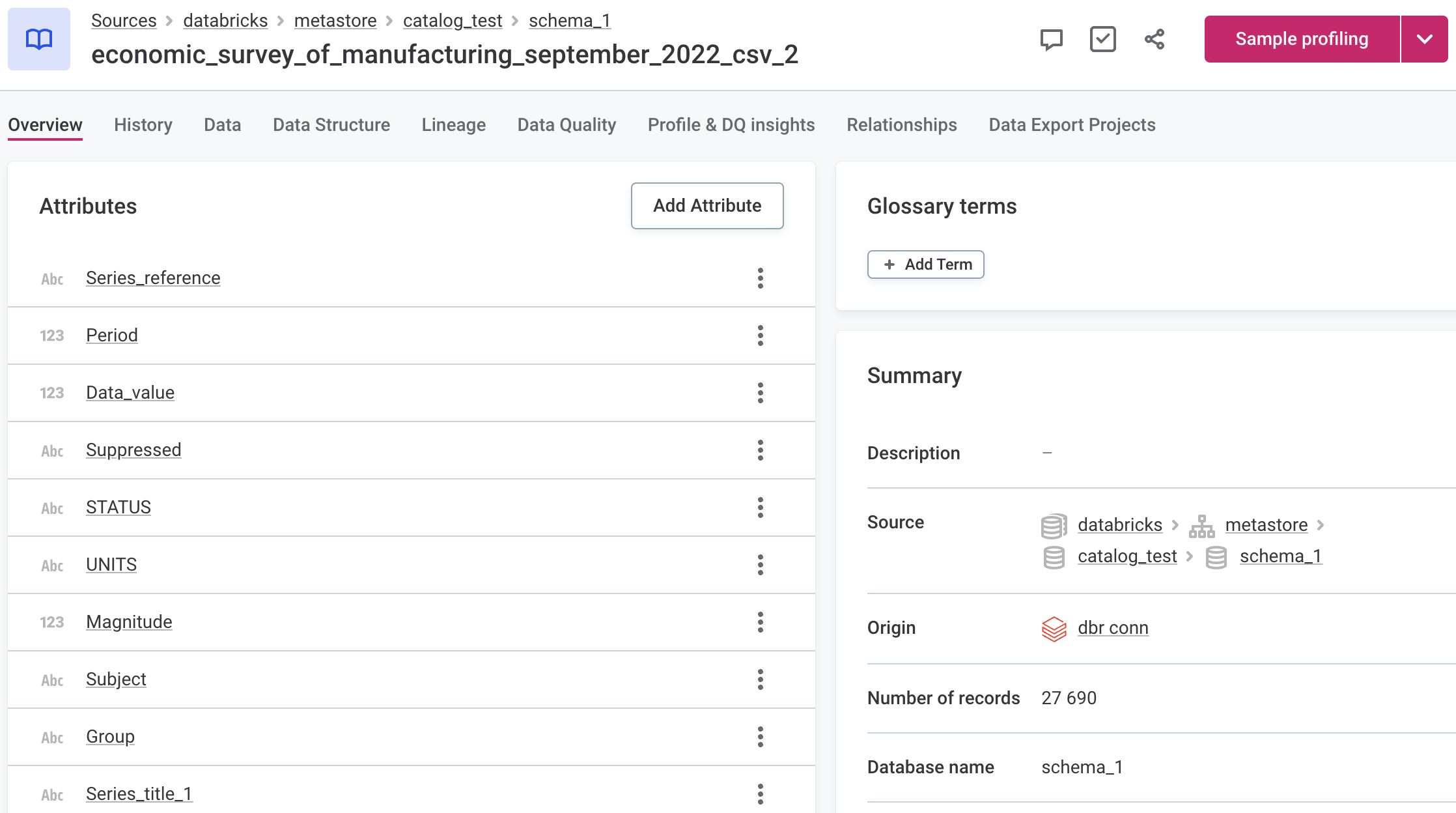
|
Was this page useful?