
dbt Lineage Scanner
Introduction
This guide details the integration of dbt scanners with Snowflake, focusing on supported methods, configurations, and metadata extraction. It is crucial for users to ensure compatibility with dbt version 1.0 or higher.
Integration methods
The dbt scanner facilitates metadata extraction through two primary integration methods:
-
File-based dbt scanner: Optimized for dbt Core users
-
Cloud API-based dbt scanner: Suitable for dbt Cloud deployments
File-based dbt scanner
Description
The file-based dbt scanner caters primarily to dbt Core users but is also functional for dbt Cloud customers. This method is particularly useful for environments where direct API access is limited or unavailable.
Limitations
File-based integration is limited in certain capabilities compared to Cloud API integration, including:
-
Separate configuration requirements for each dbt project
-
Inability to support runtime metadata extraction
Toolkit configuration
| Property | Description |
|---|---|
|
unique name of the scanner job |
|
must contain DBT |
|
Human readable description |
|
List of Ataccama ONE connection names for future automatic pairing |
|
Path to dbt artefacts |
|
dbt manifest file. Contains model, source, tests and lineage data. Link to dbt documentation: docs.getdbt.com/reference/artifacts/manifest-json |
|
dbt catalog file. It is optional. Contains schema data. Link to dbt documentation: docs.getdbt.com/reference/artifacts/catalog-json |
Legend: *mandatory
{
"scannerConfigs": [
{
"name": "My dbt on-prem project",
"sourceType": "DBT",
"description": "Scan dbt on-prem project",
"file": {
"path": "c:\\dbt_input_files",
"manifest": "manifest.json",
"catalog": "catalog.json"
}
}
]
}Cloud API-based dbt scanner
Description
The Cloud API-based scanner provides comprehensive metadata and lineage extraction from all dbt projects that the provided dbt API token can access.
API choices
Choosing between DISCOVERY_API and ADMIN_API is pivotal based on the available dbt Cloud deployments and their respective features as detailed below.
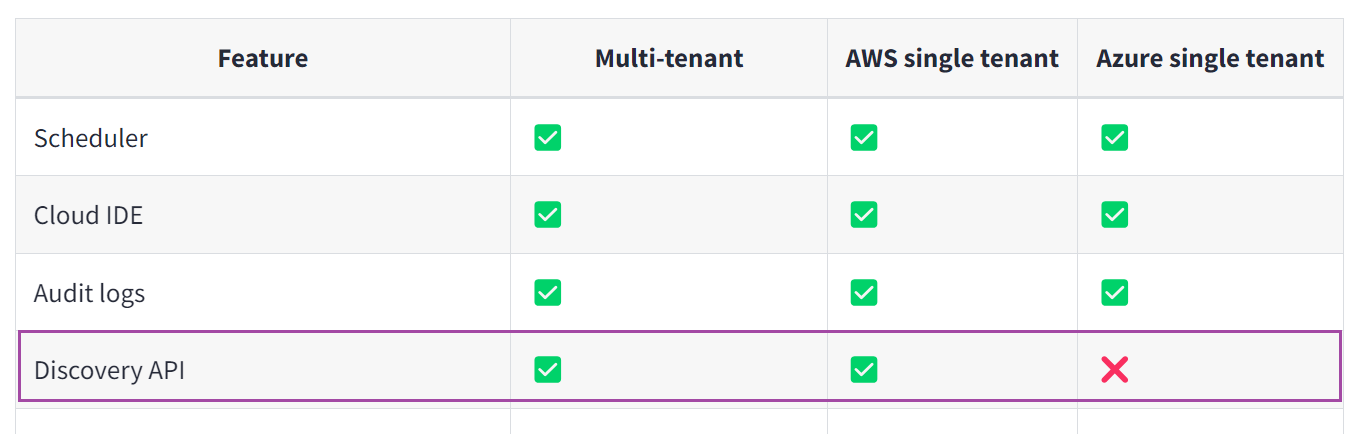
For the most current information, check the dbt Cloud documentation here: dbt Cloud documentation.
Toolkit Configuration
| Property | Description |
|---|---|
|
unique name of the scanner job |
|
must contain DBT |
|
Human readable description |
|
List of Ataccama ONE connection names for future automatic pairing |
|
Possible values: DISCOVERY_API or ADMIN_API |
|
dbt cloud Admin (Rest) API URL. Possible URLs (as of 20.12.2023) : Production (US) : cloud.getdbt.com Production (Europe): emea.dbt.com Production (AU) : au.dbt.com Link to dbt documentation: docs.getdbt.com/docs/dbt-cloud-apis/admin-cloud-api |
|
Mandatory only for connection type DISCOVERY_API. Your dbt discovery (GraphQl) API URL endpoint. See: docs.getdbt.com/docs/dbt-cloud-apis/service-tokens Link to dbt documentation: docs.getdbt.com/docs/dbt-cloud-apis/discovery-querying |
|
dbt service account token. Refer to dbt doc how to create one: docs.getdbt.com/docs/dbt-cloud-apis/service-tokens Link to dbt documentation: docs.getdbt.com/docs/dbt-cloud-apis/service-tokens |
|
Boolean value. If set to "true", lineage is extracted only for dbt jobs executed on dbt environments marked as production environments. If omitted it is evaluated to value "true". Link to dbt documentation: docs.getdbt.com/docs/deploy/deploy-environments#set-as-production-environment |
|
List of included dbt projects. It can be used to limit lineage extraction to the specified list of dbt projects. 💡 Configure includeProjects or excludeProjects or none of them. When you set includeProjects setting excludeProjects make no sense as these filters are mutually exclusive. |
|
List of excluded dbt projects. |
Legend: *mandatory
{
"scannerConfigs": [
{
"name": "dbt ATA prod - Discovery API",
"sourceType": "DBT",
"description": "Scan dbt sources",
"onlyProductionEnvironments": true,
"includeProjects": ["Dwh", "Customer Mart"],
"excludeProjects": [],
"connection": {
"type": "DISCOVERY_API",
"adminApiUrl": "https://cloud.getdbt.com",
"discoveryApiUrl": "https://metadata.cloud.getdbt.com/graphql",
"accessToken": "@@ref:ata:[DBT_TOKEN]"
}
}
]
}Metadata extraction details
Metadata extracted from dbt projects is critical for maintaining up-to-date and accurate data landscapes. The following table outlines the specific types of metadata available for extraction from dbt projects, particularly when using dbt Cloud:
| Metadata Type | Supported in dbt Version | Description |
|---|---|---|
Runtime metadata |
dbt Cloud only |
Includes dynamic metadata viewable in diagrams, such as dbt model descriptions, job names, and execution times. |
dbt model description |
All versions |
Detailed descriptions of each model, which can include information like the purpose of the model, its design, and key considerations. |
dbt job name |
All versions |
Name of the dbt job in which the model was last executed, which is crucial for tracking and managing dbt jobs. |
Last run timestamp |
All versions |
Timestamp indicating when the model was last run, useful for monitoring model freshness and scheduling updates. |
Last successful run timestamp |
Optional |
Timestamp of the last successful run, providing insights into the reliability and stability of the dbt processes. |
Last run status |
All versions |
Current status of the last run, which helps in identifying successes or failures in recent executions. |
Last run duration |
All versions |
Duration of the last run, important for performance analysis and optimization. |
Last run processed rows |
Certain databases |
Number of rows processed in the last run, applicable only to specific databases and providing a measure of the volume of data handled. |
Identification of hardcoded source object names |
Backend only |
Identifies dbt models where source object names are hardcoded, which is a development anti-pattern. |
Identification of orphan CTEs |
Backend only |
Identifies dbt models with unreferenced |
This detailed metadata extraction is instrumental in maintaining an efficient, transparent, and optimized data management environment. The information enables teams to monitor dbt project health, track changes, and plan improvements based on empirical data.
Supported database platforms
| Database Platform | dbt Cloud Support | Datastore Level Lineage | Attribute Level Lineage | Python Models Support in dbt |
|---|---|---|---|---|
Snowflake |
Yes |
Yes |
Yes* |
Yes |
PostgreSQL |
Yes |
Yes |
Partially* |
No |
Amazon Redshift |
Yes |
Yes |
Partially* |
No |
Microsoft Fabric |
Yes |
Yes |
Partially* |
Yes |
Databricks |
Yes |
Yes |
Partially* |
Yes |
Google BigQuery |
Yes |
Yes |
In Next Scanner Release |
Yes |
Apache Spark |
Yes |
No |
No |
No |
Starburst/Trino |
Yes |
No |
No |
No |
Azure Synapse |
No |
Yes |
Partially* |
No |
Other |
No |
No |
No |
No |
|
Details on attribute level lineage and future support plans are explained in the footnotes.
After the availability of a specific internal database technology scanner (i.e., for Azure Synapse) → the full attribute level will be available. |
Unsupported features and future developments
This section highlights the dbt features that are currently not supported by the scanner, as well as insights into future developments and planned enhancements.
Currently unsupported dbt features
-
dbt Semantic Layer utilizing MetricFlow
-
Introduced in dbt v1.6 - see: MetricFlow Documentation
-
-
Cross project references - as part of dbt Mesh
-
Introduced in dbt v1.6 - see: Cross-project References Documentation
Column lineage between cross project references should be available, although it has not yet been tested/verified.
-
-
dbt artifacts (projects, models) are not available as catalog items.
-
Enrichment of Catalog Items with metadata defined in dbt.
-
For instance, custom metadata or tags defined on a table or column level in dbt will not be available on catalog items (as platforms like Atlan support this).
-
-
dbt tests are currently not supported.
Future Developments
Planning for future releases includes enhancements in these areas:
-
Full attribute level lineage for Azure Synapse, pending the development of a specific internal database technology scanner.
-
Support for column lineage in dbt python models, which is currently planned but not yet implemented.
We want to keep users informed about the limitations of the current integration and what to expect in upcoming updates. With this clarity, users can better plan their dbt implementation strategies and understand how future changes might improve their operations.
Scanner special features
dbt scanner supports the same SQL "anomaly" detection checks as the Snowflake scanner. See the SQL "DQ" (Anomaly) detections for more details.
Was this page useful?