
From Query History to Lineage
Motivation
This document explains how to construct lineage from a query log in Snowflake, addressing various challenges and employing specific methodologies to ensure accurate and relevant lineage representation.
Challenges of runtime Lineage
Lineage construction from runtime data involves several challenges:
-
Identification of relevant queries that contribute to lineage.
-
Exclusion of lineage generated by ETL/ELT tools for which specialized scanners are available or will be provided, such as dbt, known as "Operation Lineage."
Design time vs. runtime lineage
Traditional lineage tools typically focus on design time lineage, derived from database object definitions. For Snowflake, this includes:
-
Views.
-
Tasks.
-
Procedures and functions.
-
Streams.
Constructing Snowflake Lineage
Our Snowflake lineage is derived from:
-
Runtime lineage (query log), augmented with design time objects lineage.
-
Views and materialized Views definition lineage is the only design time lineage we apply.
-
Views definition can be stable in time - so it will be not present in the query log (for the extracted query log time range - i.e.: past 5 days).
-
-
Deterministic logic to construct relevant lineage, considering:
-
Time relevance and current validity.
-
Existence of objects (not deleted) during the time of extraction.
-
Exclusion of temporary objects (i.e. tables) and outdated lineage (most challenging part).
-
Runtime Lineage sources
-
Runtime lineage is extracted from the query log, not directly from Snowflake’s runtime lineage features.
-
Future plans include utilizing Snowflake’s ACCESS_HISTORY for queries not currently parsed.
-
No expressions, only direct lineage.
-
-
We currently don’t support lineage versioning (multiple lineage version). However, this is not a Snowflake scanner limitation.
-
No AI is utilized (as of now).
Lineage validity
Maintaining lineage relevance involves:
-
Filtering based on object (database, schema) and database relevancy - i.e. exclude non-production, sandbox databases.
-
Example: exclude ad-hoc backups of production tables.
create table my_db.my_schema.dim_customer_backup as select * from dwh_prod.core.dim_customer;
-
-
Excluding queries from specific applications that produced the query log to avoid duplicated lineage.
Identifying Lineage-relevant statements
In Snowflake, "query" and "statement" are interchangeable terms. Relevant statements for lineage include:
-
CREATE TABLE AS SELECT(CTAS) -
MERGE -
INSERT(specificallyINSERT-SELECT: inserting from other DB objects) -
UPDATE -
CREATE VIEW
DELETE is relevant for impact analysis, but it doesn’t affect lineage analysis - so it is excluded.
|
Identifying statements from the latest ETL run
This is the most challenging part as we construct runtime lineage that should be valid by the time of extraction. If we have daily or hourly ETL jobs, we are interested to see the lineage from the most recent execution of these jobs.
Identifying the most recent statements relevant to the current lineage involves:
-
Analyzing the last execution of procedures.
-
Focusing on the last relevant statement execution for the target object.
Planned enhancements of this algorithm involve improving this logic so that it can be applied also for Snowflake Tasks (scheduled user-defined object - that can contain SQL statements and procedure calls), as well as the last execution of tasks that will have the highest priority. Did you know that Databricks Unity Catalog does not make any "effort" to identify the valid lineage at the time of lineage extraction? Instead, it returns lineage from all queries, jobs, and notebooks within a certain time range (Last 90 days) - along with the timestamp for each lineage edge (from column → to column relationship). (Valid on 11/02/2024)
Procedure level deduplication
Snowflake procedure calls are deduplicated based on the most recent execution , ensuring that only relevant and current lineage is included.
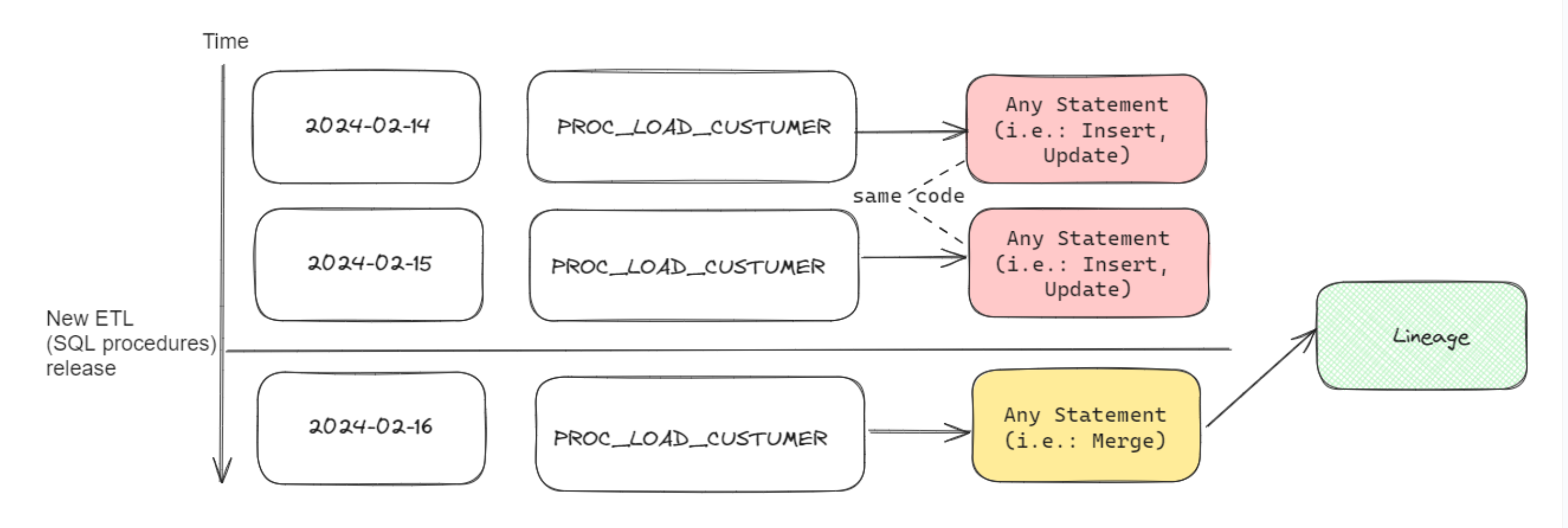
The Snowflake query log includes 2 calls (invocations) of the procedure LOAD_TARGET_TABLE. In this example, both procedure calls would result in the same lineage, as we have recently refactored our code by replacing the combination of INSERT and UPDATE statements with a MERGE statement.
Without this deduplication, all 3 statements would be part of the lineage, resulting in duplicate lineage transformations in ONE.
CREATE PROCEDURE LOAD_TARGET_TABLE()
RETURNS VARCHAR
LANGUAGE SQL
AS
BEGIN
MERGE INTO TARGET T USING SOURCE S ON T.ID = S.ID
WHEN MATCHED THEN UPDATE SET T.NAME = S.NAME, T.AGE = S.AGE
WHEN NOT MATCHED THEN INSERT (T.ID, T.NAME, T.AGE) VALUES (S.ID, S.NAME, S.AGE);
RETURN 'Done';
END;Statement level deduplication
The deduplication at the statement level is crucial for maintaining the accuracy and relevance of lineage.
By applying deduplication, we ensure that only the most recent and relevant versions of statements are included in the lineage, particularly for operations that frequently update or transform data.
This approach helps to avoid clutter in the lineage visualization and provides users with clear and actionable insights.
Supported statements
-
CREATE TABLE AS SELECT (CTAS)
-
CREATE VIEW
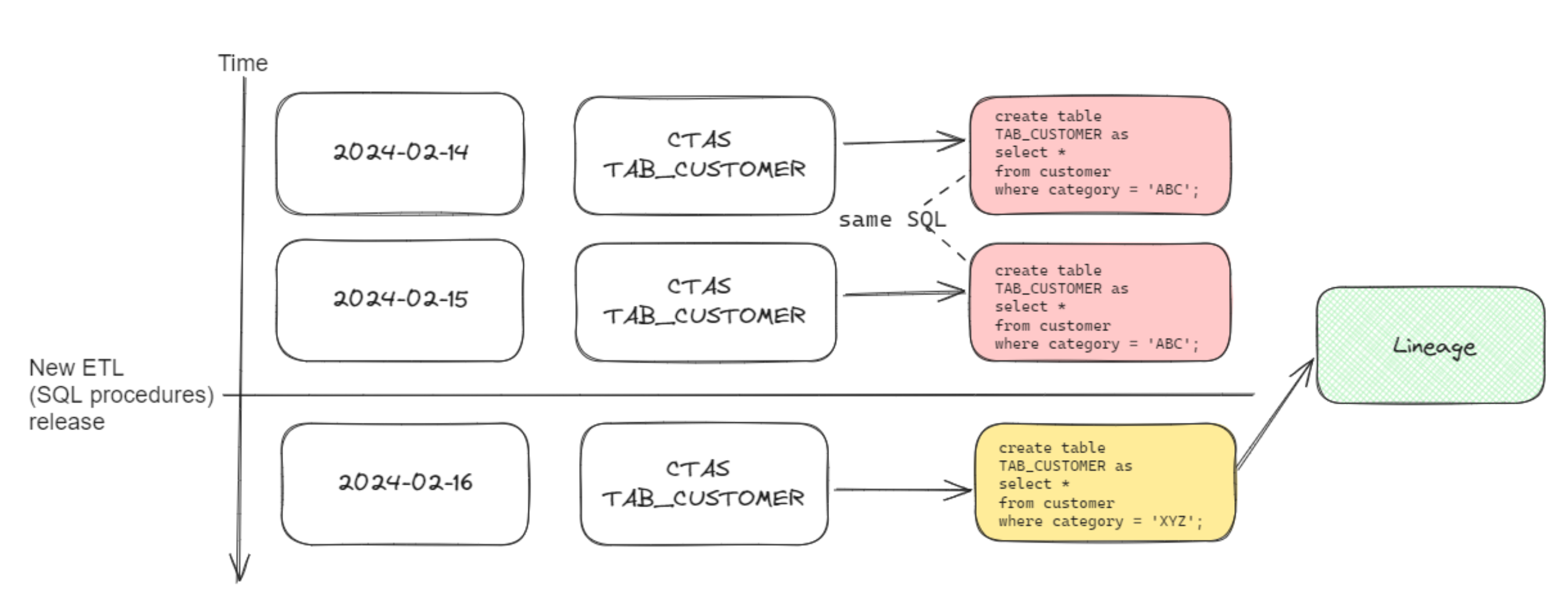
Simple example for CTAS statement deduplication:
Snowflake query log contains 2 different statements to create table TAB_1
create table db_1.schema_1.tab_1 as
select * from customer
where category = 'XYZ';| The latest query from November 2nd will be included in the lineage diagram. |
Unsupported statements
For these statements (query types) we are currently not able to find the latest statement for a specified target object:
-
MERGE -
INSERT(specificallyINSERT-SELECT: inserting from other DB objects) -
UPDATE
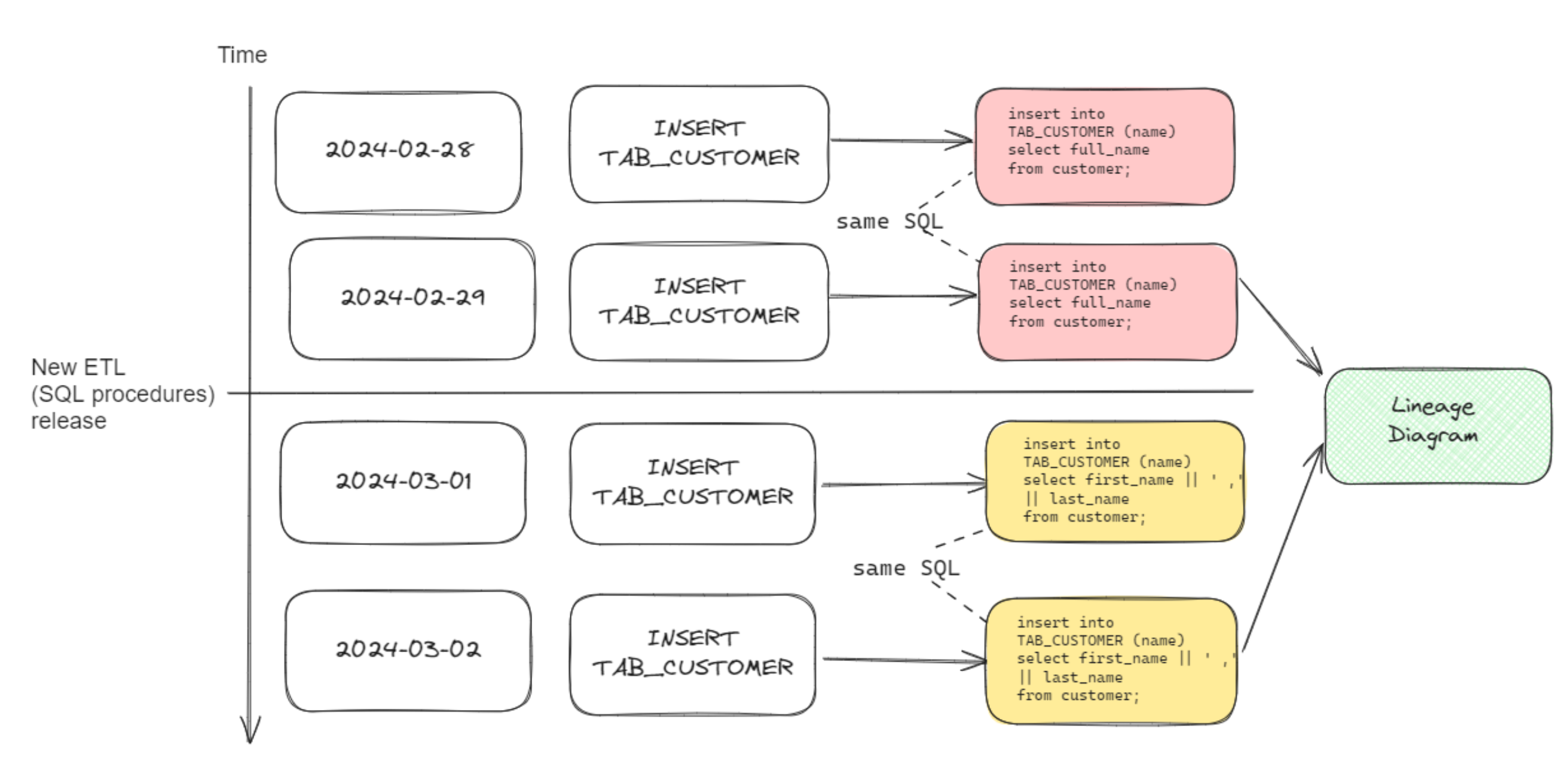
Example for INSERT
Snowflake query log contains 2 different INSERT statements for TAB_1
Both insert will be included in the lineage. This is example is trivial, but in real world scenarios, i.e. when more than 15 inserts are loading a single target table (each from a different source system), when some inserts are executed hourly, some daily, to determine the lineage valid at the time of extraction is not straightforward.
insert into db_1.schema_1.tab_1 as
select * from customer
where category = 'XYZ';Was this page useful?